Нарастающий (накопительный) итог долго считался одним из вызовов SQL. Что удивительно, даже после появления оконных функций он продолжает быть пугалом (во всяком случае, для новичков). Сегодня мы рассмотрим механику 10 самых интересных решений этой задачи – от оконных функций до весьма специфических хаков.

Системный инженер
Самые позорные ошибки в моей карьере программиста (на текущий момент)
8 min
Translation

Как говорится, если тебе не стыдно за свой старый код, значит, ты не растешь как программист — и я согласна с таким мнением. Я начала программировать для развлечения более 40 лет назад, а 30 лет назад и профессионально, так что ошибок у меня набралось очень много. Будучи профессором информатики, я учу своих студентов извлекать уроки из ошибок — своих, моих, чужих. Думаю, пришло время рассказать о моих ошибках, чтобы не растерять скромность. Надеюсь, кому-то они окажутся полезны.
Надежный, безопасный и универсальный бэкап для U2F
10 min
Мне действительно нравится уровень безопасности, предоставляемый U2F, но вместе с безопасностью, необходимо продумать и план восстановления. Потеря доступа к своим самым важным аккаунтам, если с основным U2F токеном что-то случится — серьезная проблема. В то же время, хотелось бы избежать использования бэкапа, который ставит под угрозу безопасность, предоставляемую U2F.

На сегодняшний день, образцовая практика — держать второй независимый U2F токен для бэкапа; этот токен должен быть добавлен вручную на каждый сервис и храниться в «безопасном» месте. Другая общепринятая практика — использовать не-U2F метод в качестве бэкапа (OTP, коды восстановления). Честно говоря, оба этих метода оставляют желать лучшего.
Популярные методы бэкапа
На сегодняшний день, образцовая практика — держать второй независимый U2F токен для бэкапа; этот токен должен быть добавлен вручную на каждый сервис и храниться в «безопасном» месте. Другая общепринятая практика — использовать не-U2F метод в качестве бэкапа (OTP, коды восстановления). Честно говоря, оба этих метода оставляют желать лучшего.
Идентификация клиентов на сайтах без паролей и cookie: заявка на стандарт
68 min

Уважаемые Хаброжители! Уважаемые эксперты! Представляю на вашу оценку новую концепцию идентификации пользователей на веб-сайтах, которая, как я надеюсь, с вашей помощью станет открытым интернет-стандартом, сделав этот интернет-мир чуточку лучше. Это вариант черновика протокола беспарольной идентификации, оформленный в виде вольной статьи. И если идея, положенная в его основу, получит от вас, уважаемый читатель, положительную оценку, я продолжу публикацию его на reddit.com и rfc-editor.org. И надеюсь, мне удастся заинтересовать в его реализации разработчиков ведущих браузеров. Потому ожидаю от вас конструктивную критику.
Внимание: очень много текста.
Бредогенератор: создаем тексты на любом языке с помощью нейронной сети
17 min
Привет, Хабр.
Эта статья будет в немного «пятничном» формате, сегодня мы займемся NLP. Не тем NLP, про который продают книжки в подземных переходах, а тем, который Natural Language Processing — обработка естественных языков. В качестве примера такой обработки будет использоваться генерация текста с помощью нейронной сети. Создавать тексты мы сможем на любом языке, от русского или английского, до С++. Результаты получаются весьма интересными, по картинке уже наверно можно догадаться.

Для тех, кому интересно что получается, результаты и исходники под катом.
Эта статья будет в немного «пятничном» формате, сегодня мы займемся NLP. Не тем NLP, про который продают книжки в подземных переходах, а тем, который Natural Language Processing — обработка естественных языков. В качестве примера такой обработки будет использоваться генерация текста с помощью нейронной сети. Создавать тексты мы сможем на любом языке, от русского или английского, до С++. Результаты получаются весьма интересными, по картинке уже наверно можно догадаться.
Для тех, кому интересно что получается, результаты и исходники под катом.
Как с Prometheus собирать метрики, не искаженные привязкой ко времени
8 min
Translation

Многие сетевые приложения состоят из веб-сервера, обрабатывающего трафик в реальном времени, и дополнительного обработчика, запускаемого в фоне асинхронно. Есть множество отличных советов по проверке состояния трафика да и сообщество не перестает разрабатывать инструменты вроде Prometheus, которые помогают в оценке. Но обработчики порой не менее – а то и более – важны. Им также нужны внимание и оценка, однако руководства по тому, как осуществлять это, избегая распространенных подводных камней, мало.
Эта статья посвящена ловушкам, наиболее часто встречающимся в процессе оценки асинхронных обработчиков, — на примере инцидента в рабочей среде, когда даже при наличии метрик невозможно было точно определить, чем заняты обработчики. Применение метрик сместило фокус настолько, что сами же метрики откровенно врали, мол, обработчики ваши ни к черту.
Мы увидим, как использовать метрики таким образом, чтобы обеспечить точную оценку, а в заключении покажем эталонную реализацию prometheus-client-tracer с открытым исходным кодом, который и вы можете применить в своих приложениях.
DeepFake своими руками [часть 1]
4 min
Не смотря на все прелести интернета, у него есть много минусов, и один из самых ужасных – это введения людей в заблуждение. Кликбейт, монтаж фотографий, ложные новости – все эти инструменты активно используются для обмана обычных пользователей в мировой сети, но в последние годы набирает обороты новый потенциально опасный инструмент, известный как DeepFake.
Меня данная технология заинтересовала недавно. Впервые о ней я узнал из доклада одного из спикеров на “AI Conference 2018”. Там демонстрировалось видео, в котором по аудиозаписи алгоритм сгенерировал видео с обращением Барака Обамы. Ссылка на подборку видео созданных с помощью этой технологии. Результаты меня сильно вдохновили, и мною было принято решение лучше разобраться с данной технологией, чтобы в будущем противодействовать ей. Для этого я решил написать DeepFake на языке C#. В итоге получил такой результат.

Приятного чтения!
Меня данная технология заинтересовала недавно. Впервые о ней я узнал из доклада одного из спикеров на “AI Conference 2018”. Там демонстрировалось видео, в котором по аудиозаписи алгоритм сгенерировал видео с обращением Барака Обамы. Ссылка на подборку видео созданных с помощью этой технологии. Результаты меня сильно вдохновили, и мною было принято решение лучше разобраться с данной технологией, чтобы в будущем противодействовать ей. Для этого я решил написать DeepFake на языке C#. В итоге получил такой результат.
Приятного чтения!
tinc-boot — full-mesh сеть без боли
8 min

Автоматическая, защищенная, распределенная, с транзистивными связями (т.е. пересылкой сообщений, когда нет прямого доступа между абонентами), без единой точки отказа, равноправная, проверенная временем, с низким потреблением ресурсов, full-mesh VPN сеть c возможностью "пробивки" NAT — это возможно?
Распознавание лиц на коленно-прикладном уровне
7 min
В общем и целом, распознавание лиц и идентификация людей по их результатам выглядит для аксакалов как подростковый секс — все о нем много говорят, но мало кто практикует. Понятно, что мы уже не удивляемся, что после загрузки фоточки с дружеских посиделок Facebook/VK предлагает отметить обнаруженных на снимке персон, но тут мы интуитивно знаем, что у соцсетей есть хорошее подспорье в виде графа связей персоны. А если такого графа нет? Впрочем, начнем по порядку.

Четыре правила интуитивного UX
12 min
Translation
Это советы по улучшению UX ваших проектов БЕЗ многочасовых сессий по изучению пользовательского поведения, бумажного прототипирования или любых других модных словечек.
(Серьёзно, поищите «дизайн-мышление». 100500 результатов!)
Для кого эта статья?
(Серьёзно, поищите «дизайн-мышление». 100500 результатов!)
Для кого эта статья?
- Разработчики. Вы создали собственное приложение, но каждый пользователь мучается с ним. И вы знаете: если они говорят вам это в лицо, то дело действительно плохо.
- Графические дизайнеры. Изучать UX по статьям в интернете — это какой-то… очень болезненный способ умереть.
- Менеджеры проектов. Вы уже на четверть UX-дизайнер. Было бы неплохо освоить остальные навыки.
- И остальные проходимцы. Все, кто корпит над своими проектами по вечерам и выходным. Вам тоже пригодится.
Автоматическое разблокирование корневого LUKS-контейнера после горячей перезагрузки
13 min
Tutorial
Зачем вообще люди шифруют диски своих персональных компьютеров, а иногда — и серверов? Понятное дело, чтобы никто не украл с диска фотографии их любимых домашних котиков! Вот только незадача: зашифрованный диск требует при каждой загрузке ввести с клавиатуры ключевую фразу, а она длинная и скучная. Убрать бы ее, чтобы хотя бы иногда не приходилось ее набирать. Да так, чтобы смысл от шифрования не потерялся.
Котейка для привлечения внимания

Ну, совсем убрать ее не получится. Можно вместо нее сделать ключевой файл на флешке, и он тоже будет работать. А без флешки (и без второго компьютера в сети) можно? Если повезло с BIOS, почти можно! Под катом будет руководство, как настроить шифрование диска через LUKS вот с такими свойствами:
- Ключевая фраза или ключевой файл нигде не хранится в открытом виде (или в виде, эквивалентном открытому) при выключенном компьютере.
- При первом включении компьютера требуется ввести ключевую фразу.
- При последующих перезагрузках (до выключения) ключевую фразу вводить не требуется.
Инструкции проверены на CentOS 7.6, Ubuntu 19.04 и openSUSE Leap 15.1 в виртуальных машинах и на реальном железе (десктопы, ноутбуки и два сервера). Они должны работать и на других дистрибутивах, в которых есть работоспособная версия Dracut.
И да, по-хорошему, это должно было бы попасть в хаб "ненормальное системное администрирование", но такого хаба нет.
Семь «абсолютных истин» джуниора, от которых пришлось отучиваться
10 min
Translation

Скоро наступит десятый год, как я профессионально занимаюсь программированием. Десять лет! И кроме формальной работы, почти две трети своей жизни я что-то создавала в интернете. С трудом вспоминаю годы, когда я не знала HTML: даже странно, если подумать об этом. Некоторые дети учатся музыке или балету, а я вместо этого создавала волшебные миры, кодируя в своей детской.
Размышляя об этом первом десятилетии регулярного получения денег за ввод странных символов в терминал, хотелось бы поделиться некоторыми наблюдениями, как изменилось моё мышление за годы работы.
Web tools, или с чего начать пентестеру?
11 min
Продолжаем рассказывать о полезных инструментах для пентестера. В новой статье мы рассмотрим инструменты для анализа защищенности веб-приложений.
Наш коллега BeLove уже делал подобную подборку около семи лет назад. Интересно взглянуть, какие инструменты сохранили и укрепили свои позиции, а какие отошли на задний план и сейчас используются редко.
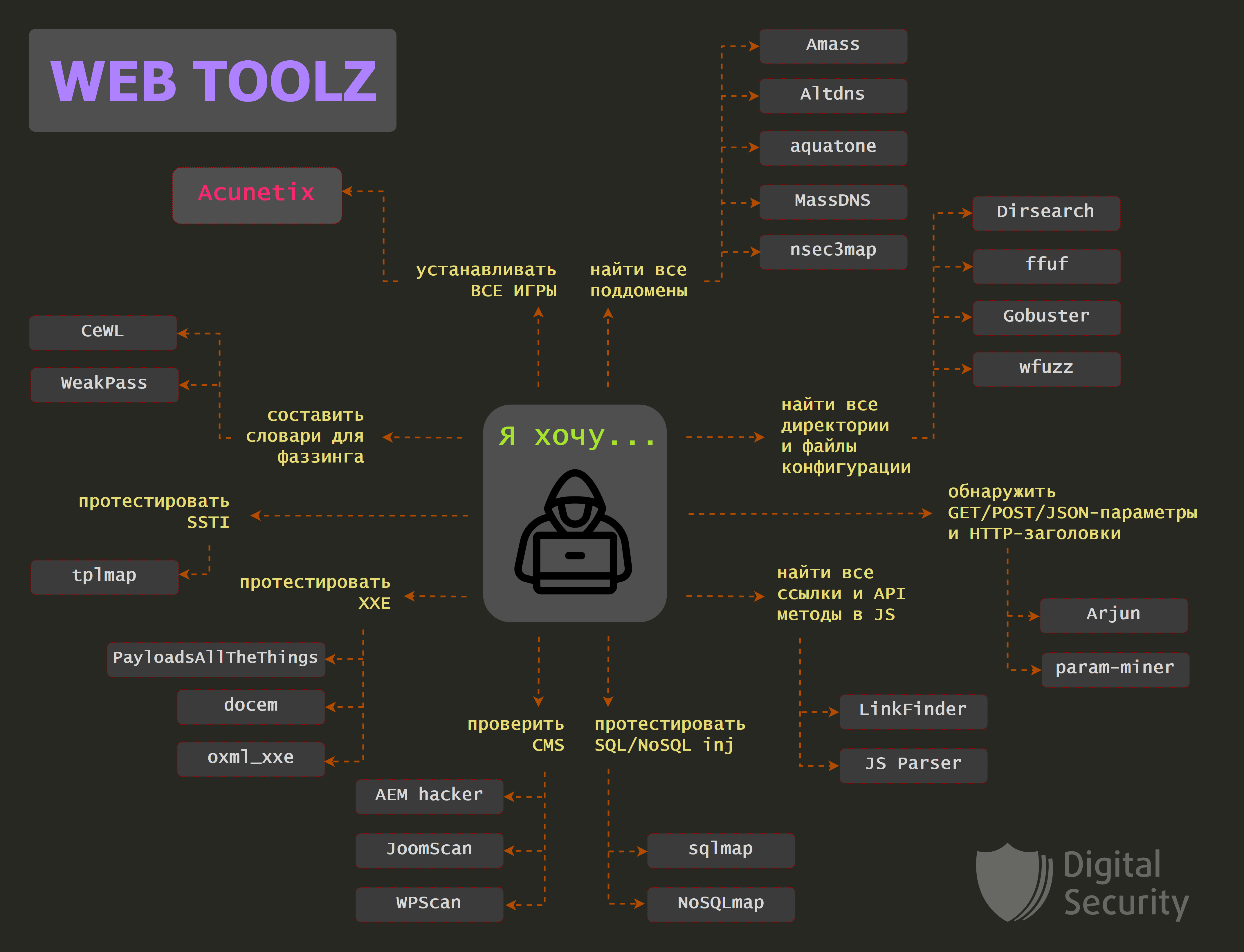
Наш коллега BeLove уже делал подобную подборку около семи лет назад. Интересно взглянуть, какие инструменты сохранили и укрепили свои позиции, а какие отошли на задний план и сейчас используются редко.
Поиск похожих изображений, разбор одного алгоритма
4 min

Пришлось мне недавно решать задачку по оптимизации поиска дубликатов изображений.
Существующее решение работает на довольно известной библиотеке, написанной на Python, — Image Match, основанной на работе «AN IMAGE SIGNATURE FOR ANY KIND OF IMAGE» за авторством H. Chi Wong, Marshall Bern и David Goldberg.
По ряду причин было принято решение переписать всё на Kotlin, заодно отказавшись от хранения и поиска в ElasticSearch, который требует заметно больше ресурсов, как железных, так и человеческих на поддержку и администрирование, в пользу поиска в локальном in-memory кэше.
Для понимания того, как оно работает, пришлось с головой погружаться в «эталонный» код на Python, так как оригинальная работа порой не совсем очевидна, а в паре мест заставляет вспомнить мем «как нарисовать сову». Собственно, результатами этого изучения я и хочу поделиться, заодно рассказав про некоторые оптимизации, как по объёму данных, так и по скорости поиска. Может, кому пригодится.
Семь лет работы разработчиком: какие уроки я извлёк
3 min
Translation
Время летит, правда?
Моя карьера началась в 2012 году, с первой стажировки по C++. Честно говоря, я понятия не имел, что делаю (на самом деле, ничего не изменилось). Однако я извлёк несколько уроков.
Отказ от ответственности: в этом сообщении не будет никакого кода.
Это английский. Или испанский, китайский, польский. Любой, какой вы используете для общения с коллегами.
Моя карьера началась в 2012 году, с первой стажировки по C++. Честно говоря, я понятия не имел, что делаю (на самом деле, ничего не изменилось). Однако я извлёк несколько уроков.
Отказ от ответственности: в этом сообщении не будет никакого кода.
Вопрос: Какой самый важный язык в программировании?
Это английский. Или испанский, китайский, польский. Любой, какой вы используете для общения с коллегами.
Карьера программиста. Часть 1. Первая программа
10 min
 Уважаемые читатели Хабра, представляю вашему вниманию серию постов, которые в будущем я планирую объединить в книгу. Я захотел покопаться в прошлом и рассказать свою историю, как я стал разработчиком и продолжаю им быть.
Уважаемые читатели Хабра, представляю вашему вниманию серию постов, которые в будущем я планирую объединить в книгу. Я захотел покопаться в прошлом и рассказать свою историю, как я стал разработчиком и продолжаю им быть. Про предпосылки попадания в IT, путь проб и ошибок, самообучения и детской наивности. Свой рассказ я начну с самого раннего детства, и закончу его сегодняшним днем. Я надеюсь, что эта книга будет особенно полезной для тех, кто только учится на IT-специальность.
А те, кто уже работают в IT — возможно проведут параллели со своим путем.
В этой книге вы найдете упоминание прочитанной мной литературы, опыт общения с людьми с которыми я пересекался при обучении, работе и запуске стартапа.
Начиная от преподавателей в университете, заканчивая крупными венчурными инвесторами и владельцами многомиллионых компаний.
На сегодняшний день готовы 3.5 главы книги, из возможных 7. Если первые главы найдут положительный отклик у аудитории, я опубликую всю книгу целиком.
Виртуальные файловые системы в Linux: зачем они нужны и как они работают? Часть 2
6 min
Translation
Всем привет, делимся с вами второй частью публикации «Виртуальные файловые системы в Linux: зачем они нужны и как они работают?» Первую часть можно прочитать тут. Напомним, данная серия публикаций приурочена к запуску нового потока по курсу «Администратор Linux», который стартует уже совсем скоро.
Как наблюдать за VFS с помощью инструментов eBPF и bcc
Самый простой способ понять, как ядро оперирует файлами

Как наблюдать за VFS с помощью инструментов eBPF и bcc
Самый простой способ понять, как ядро оперирует файлами
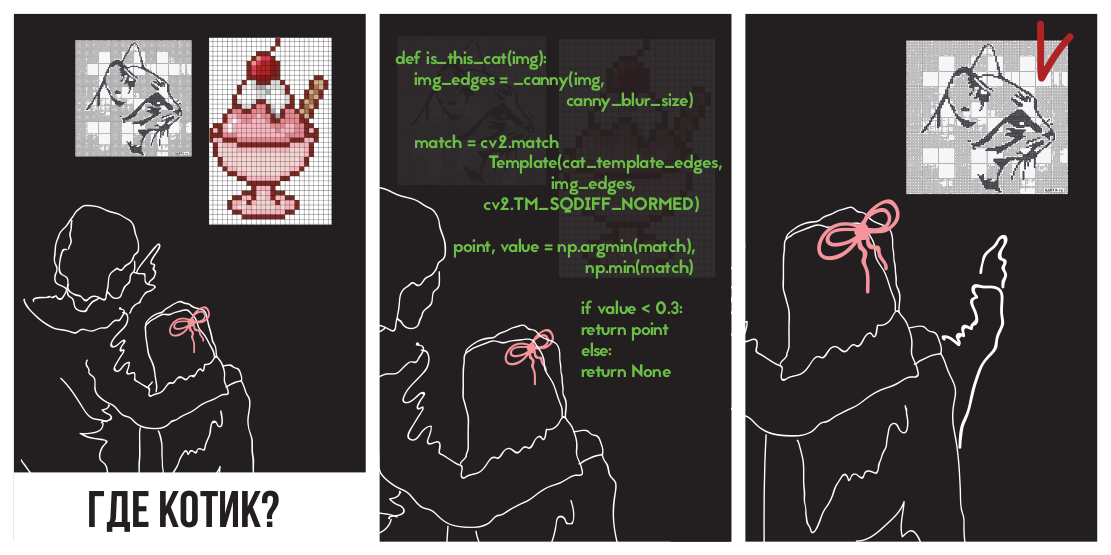
sysfs – это посмотреть за этим на практике, а самый простой способ понаблюдать за ARM64 – это использовать eBPF. eBPF (сокращение от Berkeley Packet Filter) состоит из виртуальной машины, запущенной в ядре, которую привилегированные пользователи могут запрашивать (query) из командной строки. Исходники ядра сообщают читателю, что может сделать ядро; запуск инструментов eBPF в загруженной системе показывает, что на самом деле делает ядро. Нахождение объектов на картинках
18 min
Мы занимаемся закупкой трафика из Adwords (рекламная площадка от Google). Одна из регулярных задач в этой области – создание новых баннеров. Тесты показывают, что баннеры теряют эффективность с течением времени, так как пользователи привыкают к баннеру; меняются сезоны и тренды. Кроме того, у нас есть цель захватить разные ниши аудитории, а узко таргетированные баннеры работают лучше.
В связи с выходом в новые страны остро встал вопрос локализации баннеров. Для каждого баннера необходимо создавать версии на разных языках и с разными валютами. Можно просить это делать дизайнеров, но эта ручная работа добавит дополнительную нагрузку на и без того дефицитный ресурс.
Это выглядит как задача, которую несложно автоматизировать. Для этого достаточно сделать программу, которая будет накладывать на болванку баннера локализованную цену на "ценник" и call to action (фразу типа "купить сейчас") на кнопку. Если печать текста на картинке реализовать достаточно просто, то определение положения, куда нужно его поставить — не всегда тривиально. Перчинки добавляет то, что кнопка бывает разных цветов, и немного отличается по форме.
Этому и посвящена статья: как найти указанный объект на картинке? Будут разобраны популярные методы; приведены области применения, особенности, плюсы и минусы. Приведенные методы можно применять и для других целей: разработки программ для камер слежения, автоматизации тестирования UI, и подобных. Описанные трудности можно встретить и в других задачах, а использованные приёмы использовать и для других целей. Например, Canny Edge Detector часто используется для предобработки изображений, а количество ключевых точек (keypoints) можно использовать для оценки визуальной “сложности” изображения.
Надеюсь, что описанные решения пополнят ваш арсенал инструментов и трюков для решения проблем.
Как мы использовали отложенную репликацию для аварийного восстановления с PostgreSQL
6 min
Translation

Репликация — не бэкап. Или нет? Вот как мы использовали отложенную репликацию для восстановления, случайно удалив ярлыки.
Специалисты по инфраструктуре на GitLab отвечают за работу GitLab.com — самого большого экземпляра GitLab в природе. Здесь 3 миллиона пользователей и почти 7 миллионов проектов, и это один из самых крупных опенсорс-сайтов SaaS с выделенной архитектурой. Без системы баз данных PostgreSQL инфраструктура GitLab.com далеко не уедет, и что мы только не делаем для отказоустойчивости на случаи любых сбоев, когда можно потерять данные. Вряд ли такая катастрофа случится, но мы хорошо подготовились и запаслись разными механизмами бэкапа и репликации.
Репликация — это вам не средство бэкапа баз данных (см. ниже). Но сейчас мы увидим, как быстро восстановить случайно удаленные данные с помощью отложенной репликации: на GitLab.com пользователь удалил ярлык для проекта gitlab-ce и потерял связи с мерж-реквестами и задачами.
С отложенной репликой мы восстановили данные всего за 1,5 часа. Смотрите, как это было.
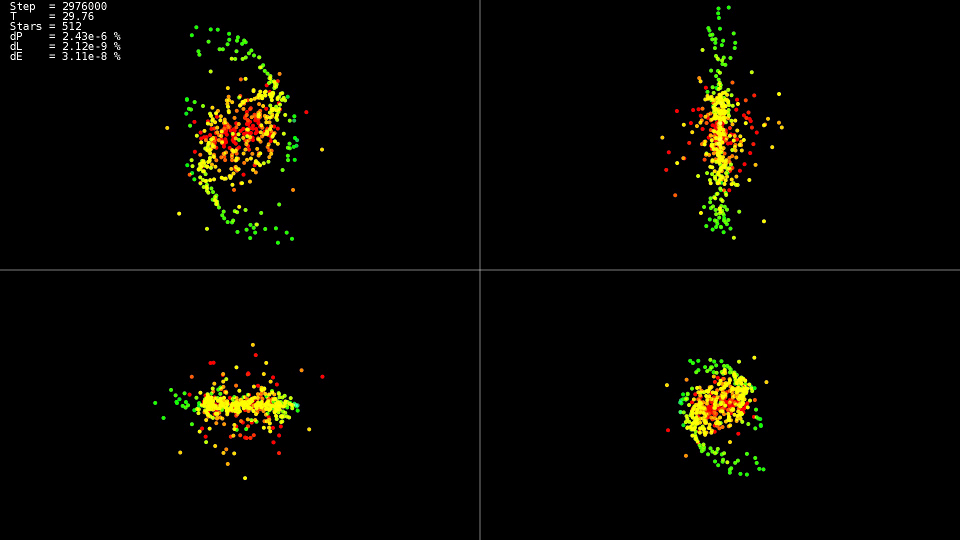
Задача N тел или как взорвать галактику не выходя из кухни
34 min
Не так давно я прочёл фантастический роман «Задача трёх тел» Лю Цысиня. В нём у одних инопланетян была проблема — они не умели, с достаточной для них точностью, вычислять траекторию своей родной планеты. В отличии от нас, они жили в системе из трёх звёзд, и от их взаимного расположения сильно зависела «погода» на планете — от испепеляющей жары до леденящего мороза. И я решил проверить, можем ли мы решать подобные задачи.