Сводная таблица – один из самых базовых видов аналитики. Многие считают, что создать её средствами SQL невозможно. Конечно же, это не так.

Пользователь
Великий раскол в import: проясняем неопределенность с импортом в Typescript
5 min
Translation
Перевод статьи подготовлен в преддверии старта курса «Разработчик React.js»

Я довольно долго работаю с typescript, и у меня было много проблем с тем, чтобы разобраться с его модулями и советующими настройками, и должен сказать, вокруг них и вправду много непонятного. Пространства имен,
Я не буду говорить о пространствах имен как о модульной системе в typescript, поскольку идея оказалась не лучшей (особенно учитывая текущий вектор развития), и этим никто сейчас не пользуется.
Я довольно долго работаю с typescript, и у меня было много проблем с тем, чтобы разобраться с его модулями и советующими настройками, и должен сказать, вокруг них и вправду много непонятного. Пространства имен,
import * as React from 'react', esModuleInterop и т.д. Поэтому давайте разберемся из-за чего поднялась вся шумиха.Я не буду говорить о пространствах имен как о модульной системе в typescript, поскольку идея оказалась не лучшей (особенно учитывая текущий вектор развития), и этим никто сейчас не пользуется.
Я есть root. Разбираемся в повышении привилегий ОS Linux
9 min
Tutorial
Первый квартал 2020 года я провел за подготовкой к экзамену OSCP. Поиск информации в Google и множество «слепых» попыток отнимали у меня все свободное время. Особенно непросто оказалось разобраться в механизмах повышения привилегий. Курс PWK уделяет этой теме большое внимание, однако методических материалов всегда недостаточно. В Интернете есть куча мануалов с полезными командами, но я не сторонник слепого следования рекомендациям без понимания, к чему это приведет.
Мне хочется поделиться с вами тем, что удалось узнать за время подготовки и успешной сдачи экзамена (включая периодические набеги на Hack The Box). Я испытывал сильнейшее ощущение благодарности к каждой крупице информации, которая помогала мне пройти путь Try Harder более осознанно, сейчас мое время отдать должное комьюнити.
Я хочу дать вам мануал по повышению привилегий в OS Linux, включающий в себя разбор наиболее частых векторов и смежных фишек, которые вам обязательно пригодятся. Зачастую сами механизмы повышения привилегий достаточно несложные, трудности возникают при структурировании и анализе информации. Поэтому я решил начать с «обзорной экскурсии» и далее рассматривать каждый вектор в отдельной статье. Надеюсь, я сэкономлю вам время на изучение темы.

Мониторинг акторов в Akka.Net, но на F#
15 min
Сразу скажу, хаба для F# на хабре нет, поэтому пишу в C#.
Для тех кто не знаком с F#, но знаком с C#, рекомендую наисвежайшую статью от Microsoft.
Она поможет Вам испытывать меньше WTF моментов при прочтении, т.к. моя статья не туториал к синтаксису.
Есть сервис, написанный на Akka.NET, он вываливает в разные текстовые логи кучу инфы. Отдел эксплуатации грепает эти логи, жарит по ним регекспами, чтобы узнать о кол-ве ошибок (бизнесовых и не очень), о кол-ве входящих в сервис сообщений и кол-ве исходящих. Далее эта информация заливается в ElasticDB, InfluxDB и показывается в Grafana и Kibana в разных срезах и агрегациях.
Звучит сложно, да и парсить текстовые логи сервиса, который генерит несколько десятков ГБ текстового мусора в день — занятие неблагодарное. Поэтому встала задача — сервис должен быть способен поднять ендпоинт, который можно дёрнуть и получить сразу всю инфу о нём.
Решать задачу будем так:
Для тех кто не знаком с F#, но знаком с C#, рекомендую наисвежайшую статью от Microsoft.
Она поможет Вам испытывать меньше WTF моментов при прочтении, т.к. моя статья не туториал к синтаксису.
Контекст задачи
Есть сервис, написанный на Akka.NET, он вываливает в разные текстовые логи кучу инфы. Отдел эксплуатации грепает эти логи, жарит по ним регекспами, чтобы узнать о кол-ве ошибок (бизнесовых и не очень), о кол-ве входящих в сервис сообщений и кол-ве исходящих. Далее эта информация заливается в ElasticDB, InfluxDB и показывается в Grafana и Kibana в разных срезах и агрегациях.
Звучит сложно, да и парсить текстовые логи сервиса, который генерит несколько десятков ГБ текстового мусора в день — занятие неблагодарное. Поэтому встала задача — сервис должен быть способен поднять ендпоинт, который можно дёрнуть и получить сразу всю инфу о нём.
Решать задачу будем так:
- Напишем доменную модель для метрик
- Замапим доменную модель метрик на реализацию App.Metrics и поднимем апишечку
- Сделаем структурированный доменный логгер, который натянем на внутренний логгер Akka
- Сделаем обёртку для функциональных акторов, которая спрячет работу с метриками и логгером
- Соберём всё вместе и запустим
Подготовка к собеседованию в компании большой пятерки
5 min
По моим впечатлениям очень многих людей интересует тема подготовки к собеседованиям в топ технические компании, поэтому решил вместо личных ответов написать одну статью на которую в дальнейшем буду ссылаться. Всем кому интересен процесс самого собеседования, вещи на которые нужно обращать внимание, как готовиться и к чему готовиться — добро пожаловать под кат.
Почему люди не используют формальные методы?
20 min
Translation
На Software Engineering Stack Exchange я увидел такой вопрос: «Что мешает широкому внедрению формальных методов?» Вопрос был закрыт как предвзятый, а большинство ответов представляли собой комментарии типа «Слишком дорого!!!» или «Сайт — это не самолёт!!!» В каком-то смысле это верно, но мало что объясняет. Я написал эту статью, чтобы дать более широкую историческую картину формальных методов (FM), почему они на самом деле не используются и что мы делаем для исправления ситуации.
Прежде чем начать, нужно сформулировать некоторые условия. На самом деле существует не так много формальных методов: всего несколько крошечных групп. Это означает, что разные группы по-разному применяют термины. В широком смысле есть две группы формальных методов: формальная спецификация изучает запись точных, однозначных спецификаций, а формальная проверка — методы доказательства. Сюда входят и код, и абстрактные системы. Мало того, что мы используем разные термины для кода и систем, мы часто используем разные инструменты для их верификации. Чтобы ещё больше всё запутать, если кто-то говорит, что создаёт формальную спецификацию, обычно это означает и верификацию дизайна. А если кто-то говорит, что делает формальную верификацию, обычно это относится к верификации кода.
Прежде чем начать, нужно сформулировать некоторые условия. На самом деле существует не так много формальных методов: всего несколько крошечных групп. Это означает, что разные группы по-разному применяют термины. В широком смысле есть две группы формальных методов: формальная спецификация изучает запись точных, однозначных спецификаций, а формальная проверка — методы доказательства. Сюда входят и код, и абстрактные системы. Мало того, что мы используем разные термины для кода и систем, мы часто используем разные инструменты для их верификации. Чтобы ещё больше всё запутать, если кто-то говорит, что создаёт формальную спецификацию, обычно это означает и верификацию дизайна. А если кто-то говорит, что делает формальную верификацию, обычно это относится к верификации кода.
Проблема дублирования и устаревания знания в mock-объектах или Интеграционные тесты — это хорошо
9 min
Многие программисты при выборе между интеграционным и юнит-тестом отдают предпочтение юнит-тесту (или, иными словами, модульному тесту). Некоторые считают интеграционные тесты антипаттерном, некоторые просто следуют модным тенденциям. Но давайте посмотрим, к чему это приводит. Для реализации юнит-теста mock-объекты навешиваются не только на внешние сервисы и хранилища данных, но и на классы, реализованные непосредственно внутри программы. При этом, если мокируемый класс используется в нескольких других классах, то и mock-объект будет содержаться в тестах на несколько классов. А поскольку тестируемое поведение принято задавать внутри теста (смотри given-when-then, arrange-act-assert, test builder), то поведение моки каждый раз заново задаётся в каждом тесте, и нарушается принцип DRY (хотя дублирования кода может и не быть). Кроме того, поведение класса декларируется в mock-объекте, но сама эта декларация не проверяется, поэтому со временем задекларированное в моке поведение может устареть и начать отличаться от реального поведения мокируемого класса. Это вызывает целый ряд сложностей:
1)Во-первых, при изменении функционала сложно вообще вспомнить, что помимо класса и тестов на него нужно изменить ещё и моки этого класса. Давайте рассмотрим цикл разработки в рамках TDD: «создание\изменение тестов на функционал -> создание\изменение функционала -> рефакторинг». Mock-объекты являются декларированием поведения класса и не имеют отношения ни к одной из этих трёх категорий (не являются тестами на функционал, несмотря на то, что в тестах используются, и уж тем более не являются самим функционалом). Таким образом, изменение mock-объектов классов, реализованных внутри программы, не укладывается в концепцию TDD.
2)Во-вторых, сложно найти все места мокирования этого класса. Я не встречал ни одного инструмента для этого. Тут можно или написать свой велосипед, или смотреть все места использования этого класса и отбирать те, где создаются моки. Но при неавтоматизированном поиске можно и ошибиться, проглядеть что-нибудь. Тут у вас, наверное возник вопрос: если проблема столь фундаментальна, как описывает автор, неужели никому не пришло в голову реализовать инструменты, упрощающие её решение? У меня есть гипотеза на этот счёт. Несколько лет назад я начал писать библиотеку, которая должна была собирать mock-объект так же, как IOC-контейнер собирает обычный класс, и автоматически создавать и прогонять тесты на поведение, описываемое в моках. Но затем я отказался от этой идеи, потому что нашёл более элегантное решение проблемы моков: просто не создавать эту проблему. Вероятно, по схожей причине специализированный инструмент для поиска моков конкретного класса или не реализован, или малоизвестен.
3)В-третьих, мест мокирования класса может быть много, и изменение их всех — рутинное занятие. Если программист вынужден делать рутину, которую невозможно автоматизировать, то это явный признак того, что с инструментами, архитектурой или рабочими процессами что-то не в порядке.
Надеюсь, суть проблемы ясна. Далее я опишу пути решения этой проблемы и расскажу, почему, с моей точки зрения, интеграционные тесты предпочтительнее юнит-тестов.

1)Во-первых, при изменении функционала сложно вообще вспомнить, что помимо класса и тестов на него нужно изменить ещё и моки этого класса. Давайте рассмотрим цикл разработки в рамках TDD: «создание\изменение тестов на функционал -> создание\изменение функционала -> рефакторинг». Mock-объекты являются декларированием поведения класса и не имеют отношения ни к одной из этих трёх категорий (не являются тестами на функционал, несмотря на то, что в тестах используются, и уж тем более не являются самим функционалом). Таким образом, изменение mock-объектов классов, реализованных внутри программы, не укладывается в концепцию TDD.
2)Во-вторых, сложно найти все места мокирования этого класса. Я не встречал ни одного инструмента для этого. Тут можно или написать свой велосипед, или смотреть все места использования этого класса и отбирать те, где создаются моки. Но при неавтоматизированном поиске можно и ошибиться, проглядеть что-нибудь. Тут у вас, наверное возник вопрос: если проблема столь фундаментальна, как описывает автор, неужели никому не пришло в голову реализовать инструменты, упрощающие её решение? У меня есть гипотеза на этот счёт. Несколько лет назад я начал писать библиотеку, которая должна была собирать mock-объект так же, как IOC-контейнер собирает обычный класс, и автоматически создавать и прогонять тесты на поведение, описываемое в моках. Но затем я отказался от этой идеи, потому что нашёл более элегантное решение проблемы моков: просто не создавать эту проблему. Вероятно, по схожей причине специализированный инструмент для поиска моков конкретного класса или не реализован, или малоизвестен.
3)В-третьих, мест мокирования класса может быть много, и изменение их всех — рутинное занятие. Если программист вынужден делать рутину, которую невозможно автоматизировать, то это явный признак того, что с инструментами, архитектурой или рабочими процессами что-то не в порядке.
Надеюсь, суть проблемы ясна. Далее я опишу пути решения этой проблемы и расскажу, почему, с моей точки зрения, интеграционные тесты предпочтительнее юнит-тестов.
Организация кода в микросервисах и мой подход применения гексагональной архитектуры и DDD
7 min
Tutorial
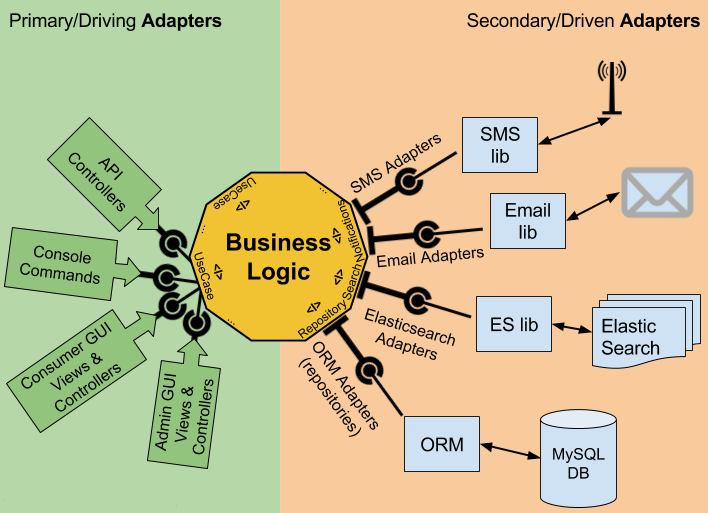
Привет, Хабр! В Монолите весь код должен быть в едином стиле, a в разных микросервисах можно использовать разные подходы, языки программирования и фреймворки. Для простых микросервисов с 1 — 2 контроллерами и 1 — 10 действиями особо смысла городить слои абстракций нет. Для сложных микросервисов с различными состояниями и логикой перехода между ними наоборот лучше изначально не лениться. Я хочу рассказать о моем опыте организации кода и использования подходов DDD, Портов и Адаптеров для обоих случаев. Есть кратко суть статьи: Джун — пишет код в контроллере. Мидл — пишет кучу абстракций. Сеньор — знает когда нужно писать код в контроллере, а когда нужны абстракции.
Спецификации на стероидах
9 min
Тема абстракций и всяких прелестных паттернов – хорошая почва для развития холиваров и вечных споров: с одной стороны, мы имеем следование мейнстриму, всяким модным словам и чистому коду, с другой стороны, мы имеем практику и реальность, которые всегда диктуют свои правила.
Что делать, если абстракции начинают «подтекать», как воспользоваться фишками языка и что можно выжать из паттерна «спецификация» — смотри под катом.
Что делать, если абстракции начинают «подтекать», как воспользоваться фишками языка и что можно выжать из паттерна «спецификация» — смотри под катом.
Типизированные запросы OData в TypeScript
8 min
Tutorial

Традиционно запросы OData к данным выражаются в виде простых строк без проверки типов при компиляции или без поддержки IntelliSense, кроме того, разработчику приходится изучать синтаксис языка запросов. Данная статья описывает библиотеку TsToOdata, которая превращает запросы в удобную языковую конструкцию и применяется аналогично классам и методам. Вы создаете типизированные запросы с помощью ключевых слов языка TypeScript и знакомых операторов.
Что такое Resizable Concurrent Map
6 min
Translation
В одном из прежних постов я рассказывал, как реализовать «простейшую в мире lock-free хеш-таблицу» на C++. Она была настолько проста, что было невозможно удалять из нее записи или менять ее размерность. С тех пор прошло несколько лет, и не так давно я написал несколько многопоточных ассоциативных массивов без таких ограничений. Их можно найти в моем проекте Junction на GitHub.
Junction содержит несколько многопоточных реализаций интерфейса map – даже «самая простая в мире» среди них, под названием
Можете ознакомиться с объяснением того, как работает Crude map, в первоначальном посте. Если коротко, то она основана на открытой адресации и линейном пробировании. Это значит, что она по сути является большим массивом ключей и значений, использующим линейный поиск. Во время добавления или поиска заданного ключа мы вычисляем хеш от ключа, чтобы определить, с какого места начать поиск. Добавление и поиск данных возможны в многопоточном режиме.
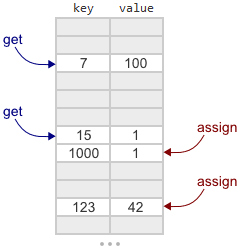
Junction содержит несколько многопоточных реализаций интерфейса map – даже «самая простая в мире» среди них, под названием
ConcurrentMap_Crude. Для краткости будем называть ее Crude map. В этом посте я объясню разницу между Crude map и Linear map из библиотеки Junction. Linear — самый простой map в Junction, поддерживающий и изменение размера, и удаление.Можете ознакомиться с объяснением того, как работает Crude map, в первоначальном посте. Если коротко, то она основана на открытой адресации и линейном пробировании. Это значит, что она по сути является большим массивом ключей и значений, использующим линейный поиск. Во время добавления или поиска заданного ключа мы вычисляем хеш от ключа, чтобы определить, с какого места начать поиск. Добавление и поиск данных возможны в многопоточном режиме.
gRPC в качестве протокола межсервисного взаимодействия. Доклад Яндекса
16 min
gRPC — опенсорсный фреймворк для удаленного вызова процедур. В Яндекс.Маркете gRPC используется как более удобная альтернатива REST. Сергей Федосеенков, который руководит службой разработки инструментов для партнеров Маркета, поделился опытом использования gRPC в качестве протокола для построения интеграций между сервисами на Java и C++. Из доклада вы узнаете, как избежать частых проблем, если вы начинаете использовать gRPC после REST, как возвращать ошибки, реализовать трассировку, отлаживать запросы и тестировать вызовы клиентов. В конце есть неофициальная запись доклада.
— Сначала хотелось бы познакомить вас с некоторыми фактами про Яндекс.Маркет, они будут полезны в рамках доклада. Первый факт: мы пишем сервисы на разных языках. Это накладывает требования по наличию клиентов для сервисов.
— Сначала хотелось бы познакомить вас с некоторыми фактами про Яндекс.Маркет, они будут полезны в рамках доклада. Первый факт: мы пишем сервисы на разных языках. Это накладывает требования по наличию клиентов для сервисов.
Визуальное руководство по диагностике неисправностей в Kubernetes
11 min
Translation
Прим. перев.: Эта статья входит в состав опубликованных в свободном доступе материалов проекта learnk8s, обучающего работе с Kubernetes компании и индивидуальных администраторов. В ней Daniele Polencic, руководитель проекта, делится наглядной инструкцией о том, какие шаги стоит предпринимать в случае возникновения проблем общего характера у приложений, запущенных в кластере K8s.
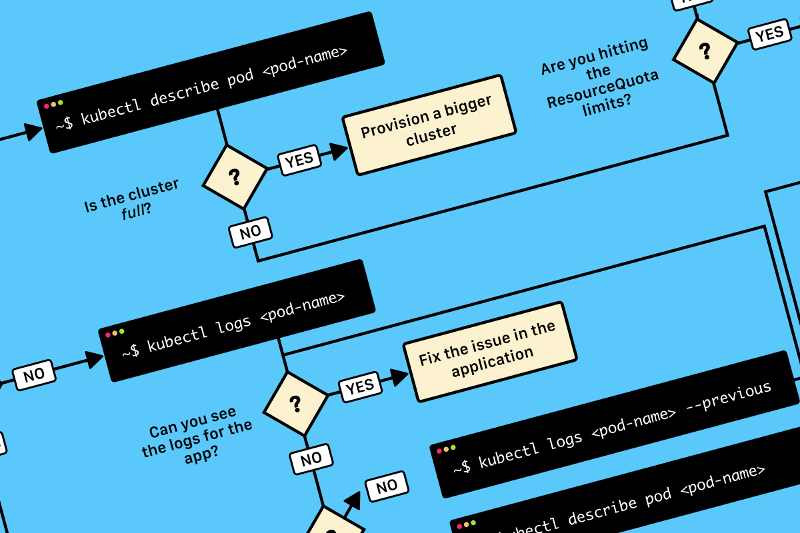
TL;DR: вот схема, которая поможет вам отладить deployment в Kubernetes:
TL;DR: вот схема, которая поможет вам отладить deployment в Kubernetes:
Производительность .NET: приемы настоящего джедая
10 min
Нужно ли вам представлять настоящего джедая .NET, performance-гуру, многократного Microsoft MVP, постоянного спикера конференции DotNext Сашу Гольдштейна? Наверно, не стоит. А если вдруг стоит, смотрите здесь.

В нашей беседе Саша делится профессиональными советами для разработчиков .NET и .NET Core. Рассказывает о том, на что обращать внимание при профилировании и отладке приложений и какими инструментами пользоваться.
В нашей беседе Саша делится профессиональными советами для разработчиков .NET и .NET Core. Рассказывает о том, на что обращать внимание при профилировании и отладке приложений и какими инструментами пользоваться.
Отчет Bank of America: 5 трендов, которые изменят глобальную экономику в следующие десять лет
4 min
Recovery Mode

Изображение: Unsplash
Прошедшее десятилетие оказалось насыщенным на различные экономические события, среди которых оказались последствия мирового финансового кризиса и восстановление рынков после него. Следующие десять лет обещают быть не менее интересными и сложными, на мировую экономику будут оказывать влияние самые разные факторы от дефляции во многих странах, низких процентных ставках, до увеличения населения и его старения.
Портал Investopedia опубликовал список из пяти главных экономических трендов следующих десяти лет, составленный аналитиками Bank of America Merrill Lynch Global Research. Мы подготовили адаптированную версию этого материала.
Логические поля в базах данных, есть ли противоядие
9 min

Часто в таблицах содержится большое количество логических полей, проиндексировать все из них нет возможности, да и эффективность такой индексации низка. Тем не менее, для работы с произвольными логическими выражениями в SQL пригоден механизм многомерной индексации о чем и пойдёт речь под катом.
ЗА и ПРОТИВ A/B-тестов: опыт крупных компаний
8 min
Привет, хабровчане. Уже завтра мы запускаем курс «Product Manager IT-проектов». В преддверии старта курса спешим поделиться с вами опытом наших действующих преподавателей.

Один из самых популярных инструментов продакт-менеджера — A/B-тесты, и именно этой теме был посвящён очередной вебинар в OTUS. В нём приняли участие сразу три специалиста:
Сергей Колосков — Product Manager в OZON.
Александр Поваров — Product Manager в TransferWise.
Андрей Менде — Product Owner в Booking.com.
Дискуссия получилась содержательной и жаркой. Обсудили:
Что интересно — действительно сошлись во мнениях по поводу границ применения А/В-тестов. Но давайте обо всём по порядку.
Один из самых популярных инструментов продакт-менеджера — A/B-тесты, и именно этой теме был посвящён очередной вебинар в OTUS. В нём приняли участие сразу три специалиста:
Сергей Колосков — Product Manager в OZON.
Александр Поваров — Product Manager в TransferWise.
Андрей Менде — Product Owner в Booking.com.
Дискуссия получилась содержательной и жаркой. Обсудили:
- в каких случаях лучше всего применять A/B-тесты?
- как определять метрики и правильно интерпретировать результаты?
- как можно навредить A/B-тестами?
- какие могут быть альтернативы А/В-тестов?
- чем лучше проводить тестирование?
- кейсы финтеха, e-commerce и маркетплейсов.
Что интересно — действительно сошлись во мнениях по поводу границ применения А/В-тестов. Но давайте обо всём по порядку.
Витамин D. Краткий экскурс
8 min
Приветствую всех Хаброжителей!
Это мой первый пост, так что, возможно он будет несколько сумбурным – прошу не очень строго судить, но конструктивным замечаниям буду рад. Картинок не будет.
Если мой пост что называется «зайдёт», я планирую осветить ещё некоторые интересные, на мой взгляд, темы, связанные с медициной, фармацией и здоровьем.
Пишу простым языком, с минимумом медицинской и фармацевтической терминологии.
Это мой первый пост, так что, возможно он будет несколько сумбурным – прошу не очень строго судить, но конструктивным замечаниям буду рад. Картинок не будет.
Если мой пост что называется «зайдёт», я планирую осветить ещё некоторые интересные, на мой взгляд, темы, связанные с медициной, фармацией и здоровьем.
Пишу простым языком, с минимумом медицинской и фармацевтической терминологии.
Как с tcpserver и netcat открыть туннель в Kubernetes pod или контейнер
4 min
Translation
Прим. перев.: Эта практическая заметка от создателя LayerCI — отличная иллюстрация так называемых tips & tricks для Kubernetes (и не только). Предлагаемое здесь решение — лишь одно из немногих и, пожалуй, не самое очевидное (для некоторых случаев может подойти уже упомянутый в комментариях «родной» для K8s

Представьте типичную ситуацию: вы хотите, чтобы порт на локальном компьютере волшебным образом перенаправлял трафик в pod/контейнер (или наоборот).
kubectl port-forward). Однако оно позволяет как минимум посмотреть на проблему с позиции применения классических утилит и их дальнейшего комбинирования — одновременно простого, гибкого и мощного (см. «другие идеи» в конце для вдохновения).Представьте типичную ситуацию: вы хотите, чтобы порт на локальном компьютере волшебным образом перенаправлял трафик в pod/контейнер (или наоборот).