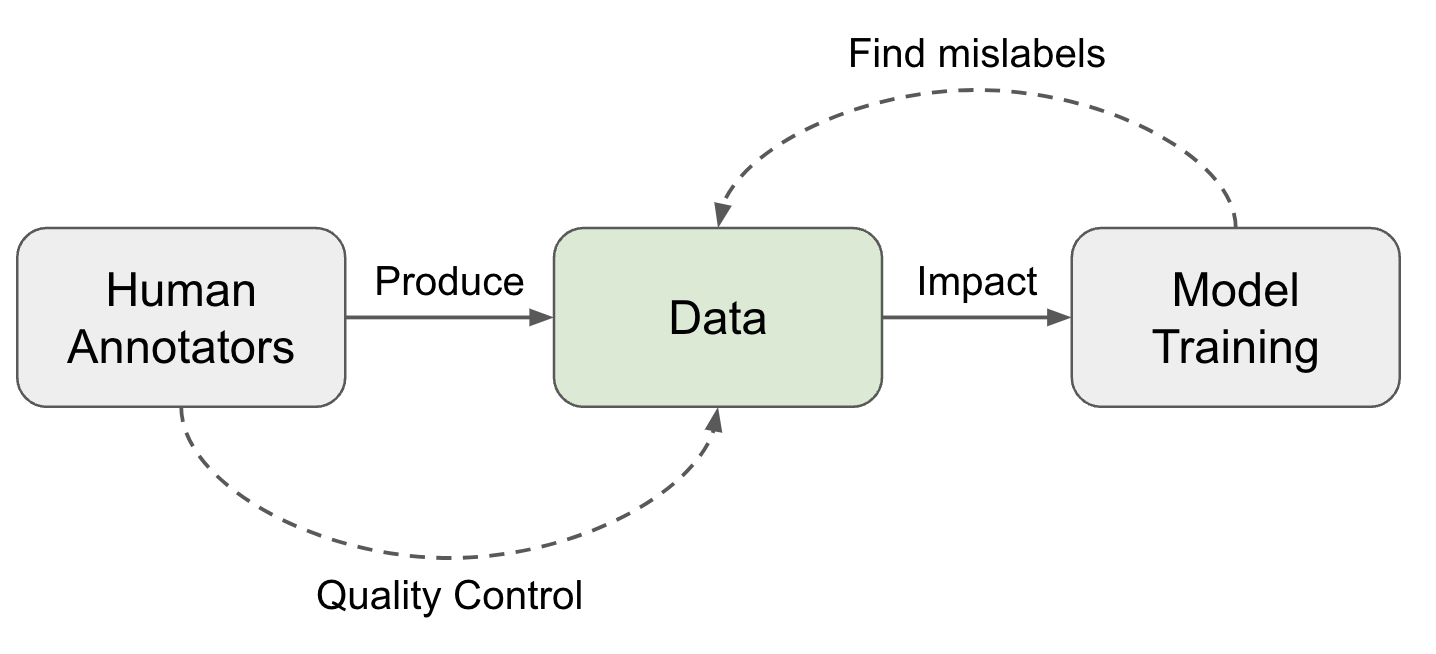
Высококачественные данные — это «топливо» для современных моделей глубокого обучения. Большая часть данных, размеченных под конкретные задачи, создается живыми людьми — аннотаторами, которые занимаются классификацией или проводят RLHF-разметку для LLM alignment. Многие из представленных в этой публикации методов машинного обучения могут помочь улучшить качество данных, но главным остается внимание к деталям и скрупулёзность.
Сообщество разработчиков машинного обучения осознает ценность высококачественных данных, но почему-то складывается впечатление, что «все хотят работать над моделями, а не над данными» (Sambasivan et al. 2021).
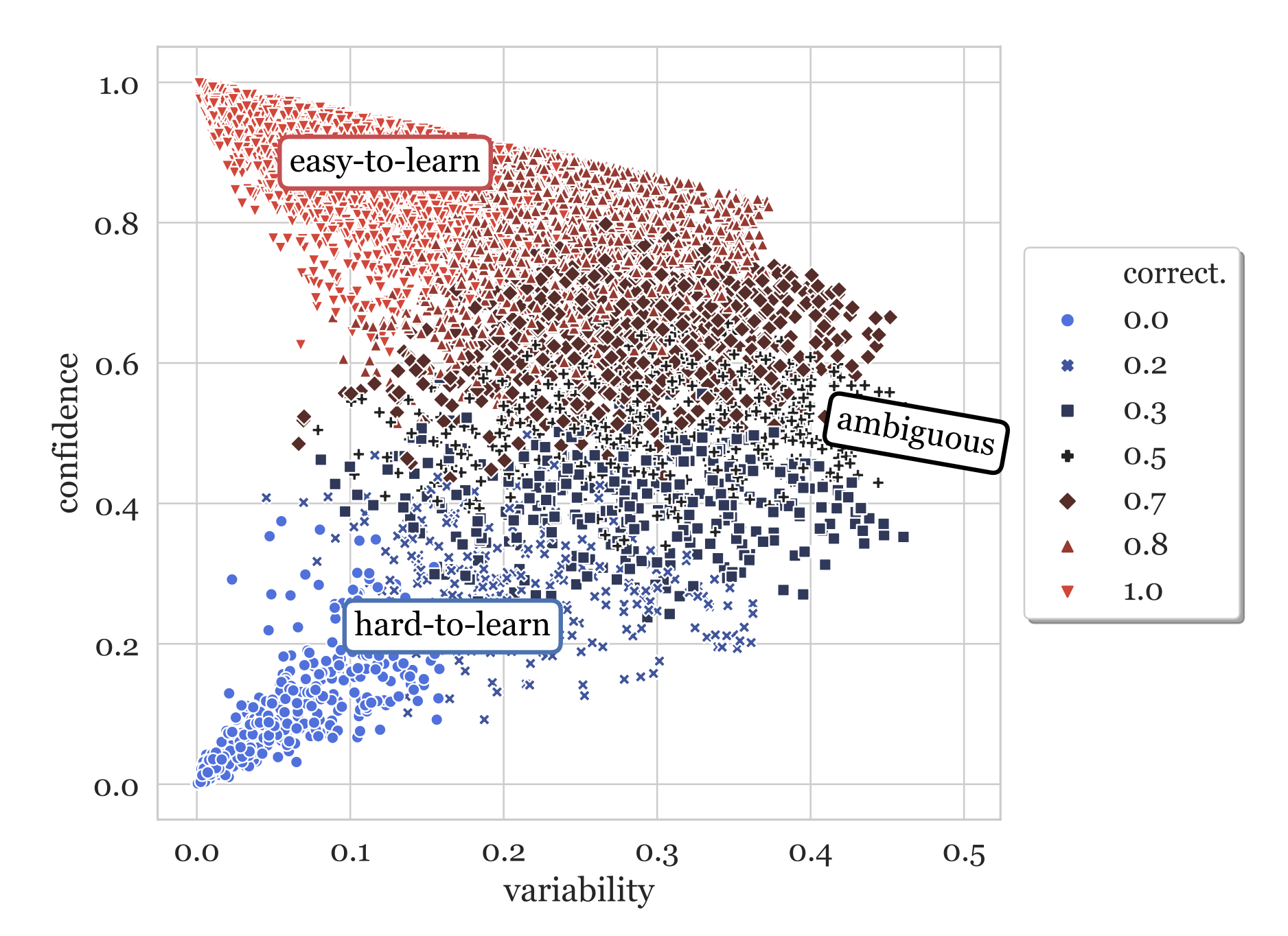
Рисунок 1. Два направления обеспечения высокого качества данных.
Десятилетия исследований в сферах когнитивной психологии, образования и программирования дали нам глубокие знания о том, как мы учимся. В следующих десяти разделах статьи мы представим научно доказанные факты об обучении, которые касаются и разработчиков ПО, а также поговорим об их практической значимости. Эта информация может помочь в самообразовании, обучении джунов и подборе персонала.
Растущие зарплаты, рекордно низкая безработица — в структуре занятости происходят тектонические сдвиги. Чтобы приводить в команду новых крутых разрабов, мы просто обязаны подмечать тенденции, анализировать рынок труда и выделять большие тренды.
Последние годы здорово изменили правила игры в IT-найме. Эта статья — попытка зафиксировать, обобщить наши наблюдения и сделать выводы, которые будут полезны и рекрутерам, и соискателям.