
Доводилось ли вам сталкиваться с системами искусственного интеллекта? Полагаем, ответ большинства хабравчан будет положительным. Ведь ИИ уже перестал быть «чем-то за гранью фантастики». Системы распознавания речи Siri, IBM Watson, ViaVoice, виртуальные игроки Deep Blue, AlphaGo и даже такие ранние системы, как MYCIN, разработанная в 1970-х годах в Стэнфордском университете и предназначенная для диагностирования бактерий, вызывающих тяжелые инфекции, а также для рекомендации необходимого количества антибиотиков — все это вариации на тему ИИ. Но, несмотря на то, что технологии стремительно набирают ход, современные системы все еще весьма «угловаты», и главная проблема, с которой сталкиваются исследователи, — это языковое обучение. Заставить систему говорить не сложно, но объяснить ей «физику» окружающего мира — то, что человек понимает на интуитивном уровне — пока не удавалось никому.
Тема языковой проблемы искусственного интеллекта широко раскрывается в статье Уилла Найта, главного редактора AI MIT Technology Review, которую специалисты
PayOnline, системы автоматизации приема онлайн-платежей, старательно перевели для пользователей Хабрахабра. Ниже представляем сам перевод.
Примерно в середине крайне напряженной игры в
Го, проходившей в южнокорейском Сеуле, участниками которой были один из лучших игроков всех времен Ли Седоль и созданный Google искусственный интеллект под названием AlphaGo, программа сделала загадочный шаг, продемонстрировавший пугающее преимущество над своим человеческим оппонентом.


 В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.
В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.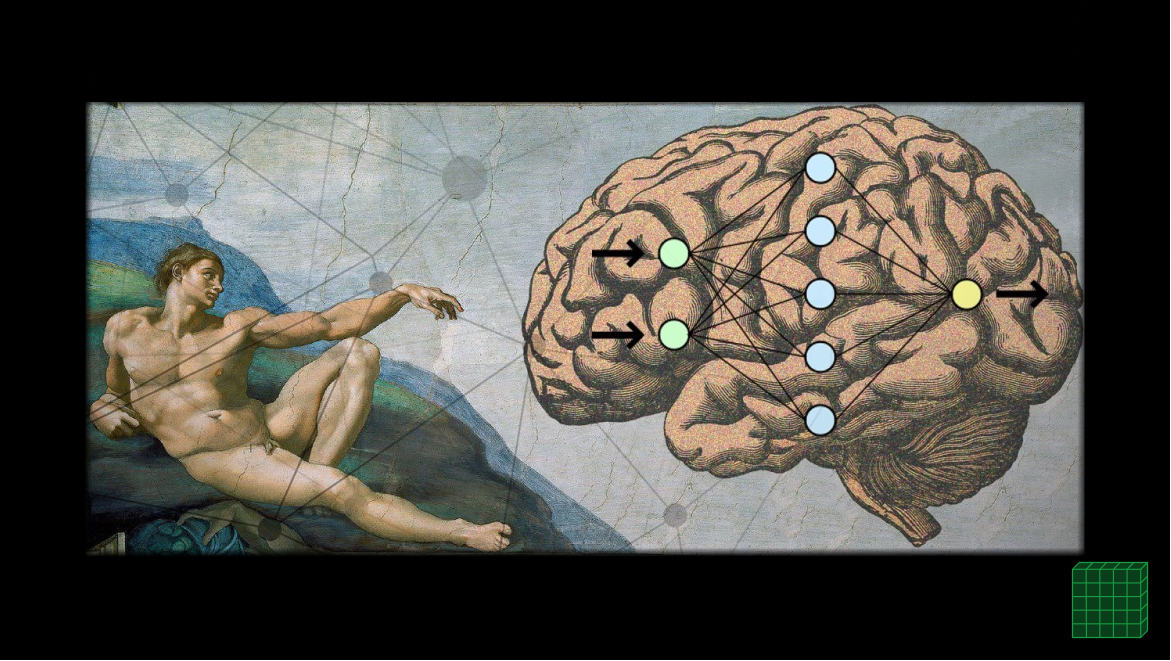



 Источник
Источник


 Цель этой статьи — поделиться опытом и идеями реализации проекта, основанного на полном преобразовании текстов в семантическое представление и организации семантического (смыслового) поиска по полученной базе знаний. Речь пойдет об основных принципах функционирования этой системы, используемых технологиях, и проблемах, возникающих при ее реализации.
Цель этой статьи — поделиться опытом и идеями реализации проекта, основанного на полном преобразовании текстов в семантическое представление и организации семантического (смыслового) поиска по полученной базе знаний. Речь пойдет об основных принципах функционирования этой системы, используемых технологиях, и проблемах, возникающих при ее реализации.