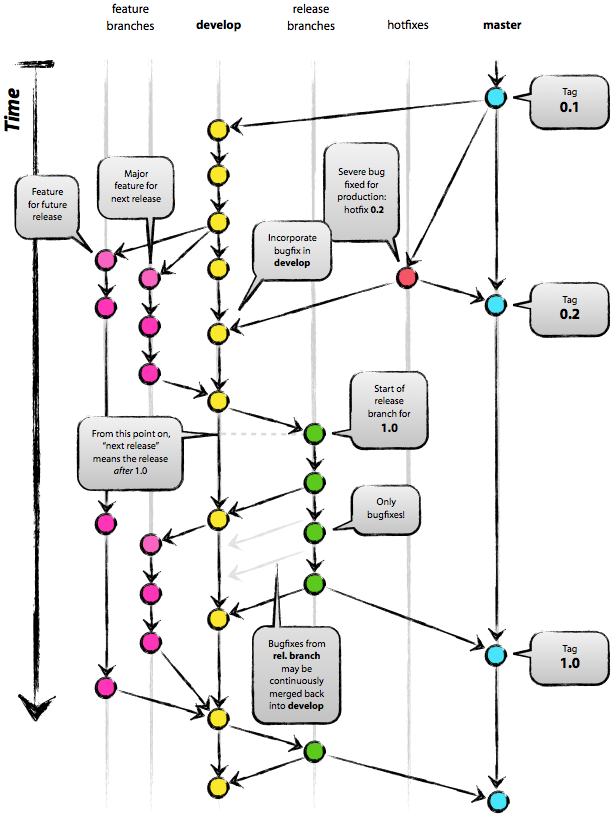
Всем привет! Вот и наша компания решила завести блог на Хабре (в конце концов, не вечно же читать чужие статьи). В профиле компании вы можете посмотреть, чем мы занимаемся. В ближайшее время мы предложим вашему вниманию цикл статей по широкому спектру тем: от сервисов дистрибуции и поддержки тестовых сборок iOS приложений до программного управления IIS. А первая наша публикация посвящена Atlassian Stash.
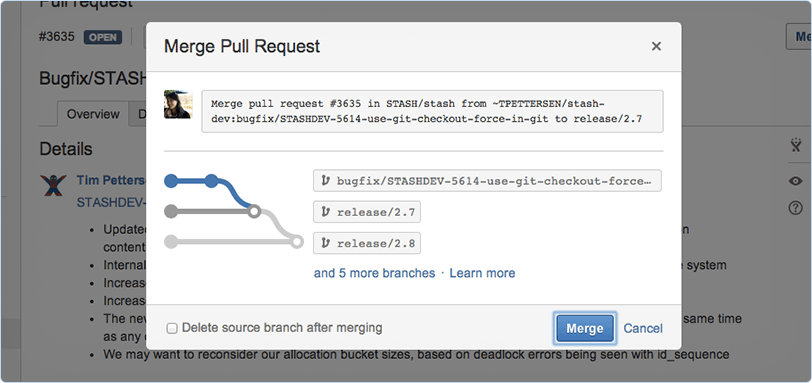
На текущий день на хабре практически отсутствует какая бы то ни было информация об Atlassian Stash (всего один анонс и одна статья на тему установки). Хотя инструмент, на самом деле, прекрасный, и определенно стоящий рассмотрения в случае использования всего стэка Atlassian. Я хочу рассказать что это такое и как эту штуку можно добавить в процесс разработки.




 Хочу поделиться историей, ну и заодно услышать мнения других участников хабрасообщества. Это небольшая история о том, как агрессивное внедрение методологии разработки Agile (Scrum) в отдельно взятой российской IT компании послужило началом исхода из компании лучших разработчиков. Обычно в статьях про Agile рассказывают, какая это классная и полезная методология, и вообще — это лучшее, что было придумано в этом направлении. Возможно, эта статья поможет взглянуть на Agile с другой стороны, ведь у любой монеты, как оказалось, есть две стороны.
Хочу поделиться историей, ну и заодно услышать мнения других участников хабрасообщества. Это небольшая история о том, как агрессивное внедрение методологии разработки Agile (Scrum) в отдельно взятой российской IT компании послужило началом исхода из компании лучших разработчиков. Обычно в статьях про Agile рассказывают, какая это классная и полезная методология, и вообще — это лучшее, что было придумано в этом направлении. Возможно, эта статья поможет взглянуть на Agile с другой стороны, ведь у любой монеты, как оказалось, есть две стороны.
 Борис Вольфсон. Технический директор компании HeadHunter.
Борис Вольфсон. Технический директор компании HeadHunter.  Андрей Ребров. Agile Engineering Coach компании ScrumTrek.
Андрей Ребров. Agile Engineering Coach компании ScrumTrek. 


 Qt является удобным и гибким средством для создания кросс-платформенного программного обеспечения. Входящий в его состав QML предоставляет полную свободу действий при создании пользовательского интерфейса.
Qt является удобным и гибким средством для создания кросс-платформенного программного обеспечения. Входящий в его состав QML предоставляет полную свободу действий при создании пользовательского интерфейса.  Смотришь новости: ну жизни нет без чат-ботов!
Смотришь новости: ну жизни нет без чат-ботов!