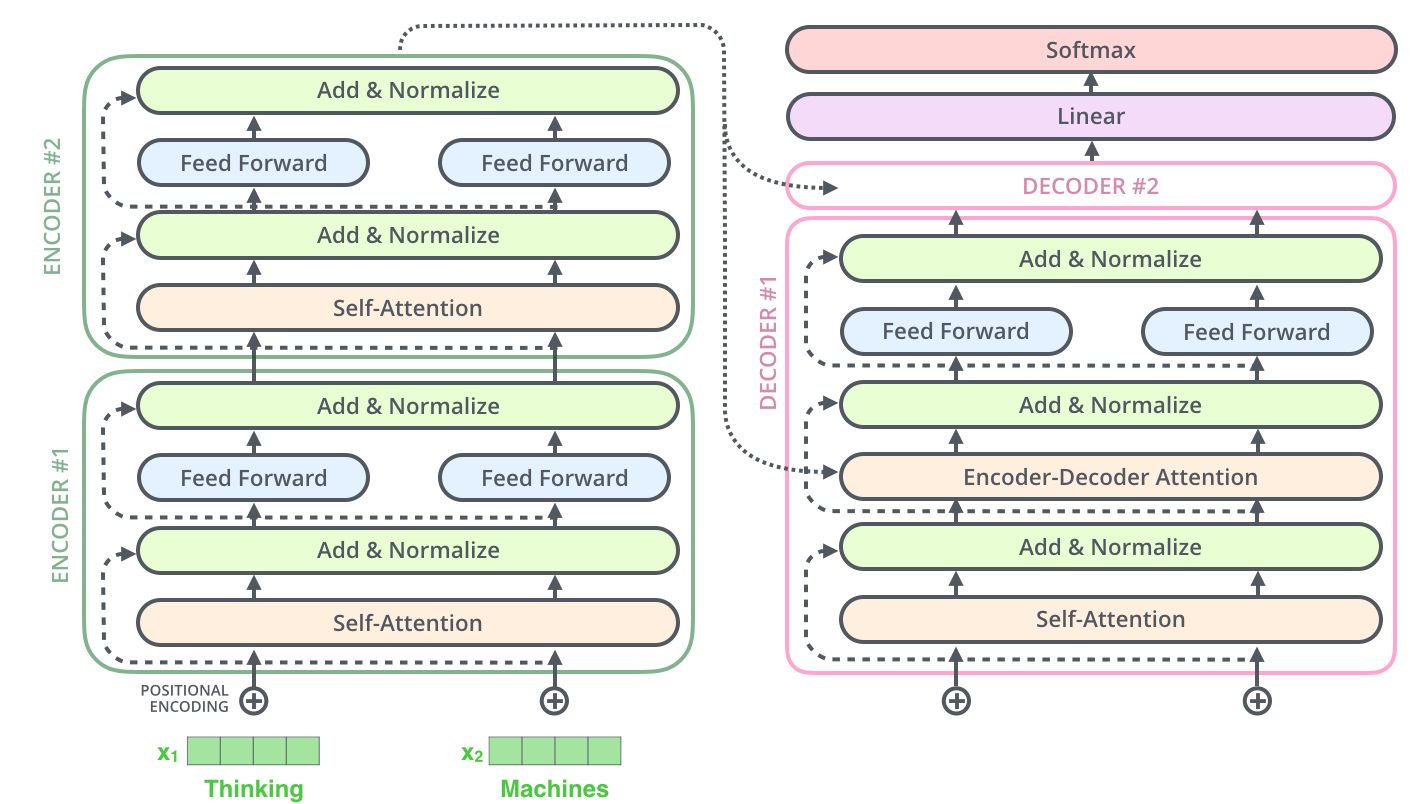
Всем привет!
Для написания кандидатской диссертации я недавно составил обзор различных методов автоматического реферирования, суммаризации. Обзор получился субъективно хорошим, поэтому я публикую его и здесь. Он очень объёмный, и я разбил его на несколько частей, которые и буду постепенно выкладывать. По мере публикации ниже будут появляться ссылки на остальные части цикла.
Статьи цикла:
1) Постановка задачи автоматического реферирования и методы без учителя ⬅️
2) Извлекающие методы автоматического реферирования
3) Секреты генерирующего реферирования текстов
Это первая статья цикла, посвящённая самой задаче и методам без учителя, которым не нужен эталонный корпус рефератов: методу Луна, TextRank, LexRank, LSA и MMR.