Comments 102
Круто. Но я только не понял, почему только 6773 пары проанализированы? Где остальные десятки милионов? Если изначально не было задумки обработать все данные, зачем же тогда было изголяться с алгоритмами и хранилищами данных?
Гистограмма перестала меняться уже после 5000 пар. Может это и не совсем научно, но я на глазок понял, что горшочек-не-вари. Ежели есть подозрения в том, что результаты не показательны, могу рассчитать доверительные интервалы.
да думаю не надо, а хотя число ПИ ведь на спор считают)))
Если не сложно, я был бы признателен.
Можно кинуть на codeforces.ru/ они будут рады сделать что нибудь оптимальное)
доверительные интервалы для 95% доверительной вероятности, 30 экспериментов по 5000 пар:
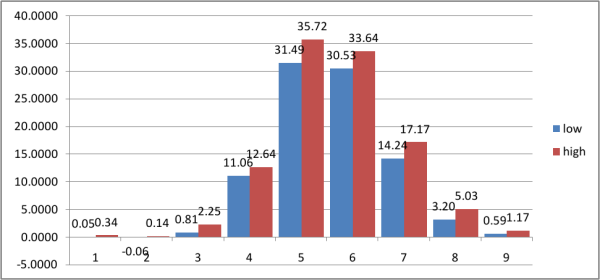

Вопрос в том, как выбирались эти 5000 пар пользователей.
Дело в том, что в самом начале на Вконтакте активно использовалась рассылка инвайтов, поэтому, если выбрать первые тысяч сто-двести пользователей, то связность у них будет очень высокая, поскольку они все (так или иначе, напрямую или опосредованно) друг друг пригласили в эту социальную сеть. Однако в дальнейшем сервис оказался «на слуху»: неоднократно был «отрекламирован» в популярных СМИ, ссылки на видео и аудио стали появляться где только не, и пользователи стали регистрироваться самостоятельно. Поэтому, если взять произвольных пользователей с идентификаторами из пятого-десятого миллиона и подсунуть к имеющимся данным, гистограмма может быстро поползти.
Дело в том, что в самом начале на Вконтакте активно использовалась рассылка инвайтов, поэтому, если выбрать первые тысяч сто-двести пользователей, то связность у них будет очень высокая, поскольку они все (так или иначе, напрямую или опосредованно) друг друг пригласили в эту социальную сеть. Однако в дальнейшем сервис оказался «на слуху»: неоднократно был «отрекламирован» в популярных СМИ, ссылки на видео и аудио стали появляться где только не, и пользователи стали регистрироваться самостоятельно. Поэтому, если взять произвольных пользователей с идентификаторами из пятого-десятого миллиона и подсунуть к имеющимся данным, гистограмма может быстро поползти.
UFO just landed and posted this here
Чтобы проверить одну пару пользователей, необходимо уметь быстро перемещаться по всему графу социальных связей. Ежели прикинуть на пальцах, в среднем, если у человека 100 друзей, а между двумя людьми 6 человек, то для расчета дистанции необходимо пересечь два множества в 100*100*100 = 1000000 друзей. Ежели на каждый пук слать запрос к API ВКонтакте, то я бы эту дистанцию считал несколько лет.
чел1-руки1-чел2-руки2-чел3-руки3-чел4-руки4-чел5-руки5-чел6
Получается 5 рукопожатий на 6 человек или 4 рукопожатия на 5 человек.
Что я понял не так?
Получается 5 рукопожатий на 6 человек или 4 рукопожатия на 5 человек.
Что я понял не так?
В горячке попутал. Спасибо за уточнение.
У нас есть два человека: A и B. Между ними 5 друзей:
А — руки1 — друг1 — руки2 — друг2 — руки3 — друг3 — руки4 — друг4 — руки5 — друг5 — руки6 — В.
Итого пять друзей, шесть рукопожатий.
А — руки1 — друг1 — руки2 — друг2 — руки3 — друг3 — руки4 — друг4 — руки5 — друг5 — руки6 — В.
Итого пять друзей, шесть рукопожатий.
«Шесть рукопожатий» — это группа в 7 человек.
Если условно пользоваться числом Эрдёша, то это №№ 0-1-2-3-4-5-6.
То есть на 6 рукопожатий либо 6, либо 7 друзей — зависит от нумерации
Но не наоборот «на 6 рукопожатий 5 человек».
Если условно пользоваться числом Эрдёша, то это №№ 0-1-2-3-4-5-6.
То есть на 6 рукопожатий либо 6, либо 7 друзей — зависит от нумерации
Но не наоборот «на 6 рукопожатий 5 человек».
Я-то с Вами согласен, но это всего лишь разная терминология. Я опирался на вот эту статью и не пытался ей сильно противоречить.
UFO just landed and posted this here
Моя любимая теория :) Очень красивая.
Спасибо!
Спасибо!
Спасибо, очень интересная статья.
Где-то в самом ВКонтакте есть такое приложение: vkontakte.ru/fchain.
А как вам удалось выделить «абсолютно независимые кластеры, в которых нет внешних связей»? В статье об этом ни слова.
Дейкстра дает изолированные кластеры.
Я просто решил не вдаваться в подробности. Алгоритм довольно простой:
1. Завести два пустых битовых поля «extracted» и «friends».
2. В extracted отметить единицей начального пользователя.
3. В friends отметить единицей всех друзей начального пользователя.
4. Для каждого отмеченного пользователя в поле friends, но не состоящего в поле extracted:
4.1. выгрузить всех друзей, поставить им единицы в поле friends.
4.2. отметить этого пользователя единицей в поле extracted.
5. Если поле friends состоит из одних нулей, значит мы поймали оторванный ото всех кластер.
6. Пункты 4-5 повторять N раз (в моем случае порогом стояло 6).
Могу в чем-нибудь ошибаться, но смысл примерно такой.
1. Завести два пустых битовых поля «extracted» и «friends».
2. В extracted отметить единицей начального пользователя.
3. В friends отметить единицей всех друзей начального пользователя.
4. Для каждого отмеченного пользователя в поле friends, но не состоящего в поле extracted:
4.1. выгрузить всех друзей, поставить им единицы в поле friends.
4.2. отметить этого пользователя единицей в поле extracted.
5. Если поле friends состоит из одних нулей, значит мы поймали оторванный ото всех кластер.
6. Пункты 4-5 повторять N раз (в моем случае порогом стояло 6).
Могу в чем-нибудь ошибаться, но смысл примерно такой.
мм, поясните пожалуйста по пункту 6. То есть если два человека связаны через 7 своих друзей, они попадут в боты или я туплю?
Некоторые поправки в алгоритм:
5. Если поле friends совпадает с полем extracted (т.е., несмотря ни на что, новых друзей для обработки вообще не нашлось), значит мы поймали оторванный ото всех кластер.
Я описал алгоритм поиска оторванных кластеров, который является частью большого алгоритма поиска кратчайшего пути. Фактически, большой алгоритм прогоняет пункты 1-6 одновременно с двух сторон (т.е. для пользователей А и В, для которых строится кратчайший путь) и на каждой итерации пересекает поля A.friends и B.friends.
Таким образом, моя реализация не пыталась найти цепочки длиннее 12 человек — по гистограмме видно, что цепочек больше 9 не так уж и много.
5. Если поле friends совпадает с полем extracted (т.е., несмотря ни на что, новых друзей для обработки вообще не нашлось), значит мы поймали оторванный ото всех кластер.
Я описал алгоритм поиска оторванных кластеров, который является частью большого алгоритма поиска кратчайшего пути. Фактически, большой алгоритм прогоняет пункты 1-6 одновременно с двух сторон (т.е. для пользователей А и В, для которых строится кратчайший путь) и на каждой итерации пересекает поля A.friends и B.friends.
Таким образом, моя реализация не пыталась найти цепочки длиннее 12 человек — по гистограмме видно, что цепочек больше 9 не так уж и много.
Теория 6 рукопожатий всё же ещё далека от того, чтобы стать аксиомой.
Например, в изначальном эксперименте Стэнли Милгрэма, из 160 отправленных писем обратно дошло лишь 24 (!). 16 из этих 24 пришли от одного человека (!!). Более того, значение «6» было лишь средним, т.е. часть писем дошла быстрее, часть — медленнее (увы, стандартного отклонения не знаю).
Английская википедия также говорит (правда без ссылки) о том, что в Университете Карнеги-Меллон повторяли этот эксперимент «using popular social networking sites». До конечной цели в этом эксперименте добралось очень малое число запросов. Впрочем, без ссылки на статью судить об этом сложно.
В настоящее время наиболее активно данным феноменом (особенно его проявлением в социальных медиа) занимается Duncan Watts. В 2003 году он с коллегами повторил классический дизайн эксперимента Милгрэма на электронной почте, отправив 24,163 сообщения 18 целям по всему миру. В результате медианное значение также равнялось 6.
Кстати, сейчас он в сотрудничестве с Facebook (сам он работает в Yahoo) планирует повторить данный эксперимент на данных самой глобальной «социальной сети» (700 млн. если я не ошибаюсь). Посмотрим, что из этого выйдет.
Например, в изначальном эксперименте Стэнли Милгрэма, из 160 отправленных писем обратно дошло лишь 24 (!). 16 из этих 24 пришли от одного человека (!!). Более того, значение «6» было лишь средним, т.е. часть писем дошла быстрее, часть — медленнее (увы, стандартного отклонения не знаю).
Английская википедия также говорит (правда без ссылки) о том, что в Университете Карнеги-Меллон повторяли этот эксперимент «using popular social networking sites». До конечной цели в этом эксперименте добралось очень малое число запросов. Впрочем, без ссылки на статью судить об этом сложно.
В настоящее время наиболее активно данным феноменом (особенно его проявлением в социальных медиа) занимается Duncan Watts. В 2003 году он с коллегами повторил классический дизайн эксперимента Милгрэма на электронной почте, отправив 24,163 сообщения 18 целям по всему миру. В результате медианное значение также равнялось 6.
Кстати, сейчас он в сотрудничестве с Facebook (сам он работает в Yahoo) планирует повторить данный эксперимент на данных самой глобальной «социальной сети» (700 млн. если я не ошибаюсь). Посмотрим, что из этого выйдет.
Грубо говоря, 50 человек зафрендили друг друга и больше никого. Довольно странное поведение, не так ли?
Вот эта вещь во всех теориях рукопожатий меня и смущала всегда. Неудивительно, что оставив только «качественных» пользователей, вовлеченных во множество кластеров, мы получим разумное значение порядка единиц или нескольких десятков. Поэтому в реальности заявления о шести рукопожатиях слишком громкие.
Дада, меня этот вопрос тоже занимает. У теории есть неявная предпосылка, что «все люди на планете хоть как-то, да связаны между собой». Но каково число вот таких вот замкнутых, не связанных с остальным миром кластеров? И это ведь совсем необязательно «боты», как в случае с обсуждаемым вычислением. Это могут быть деревни, племена, китайцы (шучу).
И потом, даже если кластер не является полностью автономным, наверняка же у каждого их них своя степень связности с остальным миром. Например, я более чем уверен, англоязычные народы гораздо сильнее связаны с современным миром, чем те же самые русскоговорящие. Т.е. американцу проще добраться до любого другого человека на земле, чем русскому, тупо говоря.
Что в этом случае значит «среднее число рукопожатий»?
И потом, даже если кластер не является полностью автономным, наверняка же у каждого их них своя степень связности с остальным миром. Например, я более чем уверен, англоязычные народы гораздо сильнее связаны с современным миром, чем те же самые русскоговорящие. Т.е. американцу проще добраться до любого другого человека на земле, чем русскому, тупо говоря.
Что в этом случае значит «среднее число рукопожатий»?
Вконтактовские друзья — неважная база для проверки этих теорий, т.к. там много сугубо виртуальных знакомых. Причем даже не тех, с кем общаешься дистанционно, а и вовсе незнакомых людей — по принципу «наткнулся-заинтересовался-добавил-забыл».
Кроме того, в такой базе слабо отражены «вертикальные» связи через людей с очень высоким положением. Например, реальная цепочка от меня до убитого ныне Усамы Бен Ладена: я — мой начальник отдела — директор предприятия — Путин — Буш — Бен-Ладен.
Если же проследить между нами цепочку «бытовых» знакомств, то боюсь, не хватит и 15-и рукопожатий…
Кроме того, в такой базе слабо отражены «вертикальные» связи через людей с очень высоким положением. Например, реальная цепочка от меня до убитого ныне Усамы Бен Ладена: я — мой начальник отдела — директор предприятия — Путин — Буш — Бен-Ладен.
Если же проследить между нами цепочку «бытовых» знакомств, то боюсь, не хватит и 15-и рукопожатий…
Но вы же можете «передать письмо» и этому «незнакомому» другу, если вы поймёте, что он ближе всего к адресату.
Поэтому когда я на хабре пару лет назад проводил цепочки от каждого о Дурова и до себя, отсеивал крупные и фейковые аккаунты (с 2500 друзьями или просто со знаменитостями). Всегда получалось 6-7 альтернативных цепочек. Так что виртуальные знакомые не сильно влияют на результат. Я прослеживал некоторые цепочки, некоторые из них реальные личные знакомства от и до.
Буш — Бен-Ладен?
а они что, встречались?
а они что, встречались?
Почитайте исследование Майкрософта, о котором я говорил в начале статьи. Ни там, ни здесь никто не пытается доказать, что цепочки из 15 рукопожатий невозможны — они есть, и их много, но мы тут вычисляем среднюю длину цепочки.
Рукопожатие и френд на фейсбуке — несколько разные вещи, не находите?
Интересно было бы проверить теорию используя именно личные знакомства и для всего мира, а не части одного континента.
Интересно было бы проверить теорию используя именно личные знакомства и для всего мира, а не части одного континента.
А есть приложение вконтакте, показывающее всех моих друзей 3, 4, 5 и 6 «уровня»? Что-то а-ля «друзя друзей Друзя»
«Почти 50% всех пользователей с ненулевым количеством друзей входило в абсолютно независимые кластеры, в которых нет внешних связей (или таких связей полторы штуки на весь кластер). Грубо говоря, 50 человек зафрендили друг друга и больше никого. Довольно странное поведение, не так ли?»
Есть лож, есть большая лож, а есть статистика.
А как же с одноклассниками начальной школы, жителями маленьких деревень, кружками пенсионеров, которых учат работе в интернете? У всех этих групп есть обособленные кластеры вконтакте. И именно за счёт этих «обособившихся» личностей может изменится полученный результат. Да и тем более, получив результат X в этой стране странно обобщать его на весь мир. Тот же Майкрософт тоже не по всему миру получал статистику, а по пользователям MSN, который основное распространение имеет в западном мире: Россия Китай и.т.д. в таком исследовании не учитывались очень слабо.
Но как пример для тренировки при работе со API различных систем эта работа, конечно, впечатляет. Реализация задачи «выкачать огромную базу» сделана хорошо и заслуживает отдельной статьи…
Есть лож, есть большая лож, а есть статистика.
А как же с одноклассниками начальной школы, жителями маленьких деревень, кружками пенсионеров, которых учат работе в интернете? У всех этих групп есть обособленные кластеры вконтакте. И именно за счёт этих «обособившихся» личностей может изменится полученный результат. Да и тем более, получив результат X в этой стране странно обобщать его на весь мир. Тот же Майкрософт тоже не по всему миру получал статистику, а по пользователям MSN, который основное распространение имеет в западном мире: Россия Китай и.т.д. в таком исследовании не учитывались очень слабо.
Но как пример для тренировки при работе со API различных систем эта работа, конечно, впечатляет. Реализация задачи «выкачать огромную базу» сделана хорошо и заслуживает отдельной статьи…
Мне кажется — тут есть такой фактор, как публичная персона…
Например Медведев недавно завел себе страницу ВКонтакте — его добавило куча людей… Если я его тоже к себе добавлю — то со всеми теми людьми я буду знаком через 2 рукопожатия — автоматически… Так что цепочка сокращается… Надо выявлять такие персоны и исключать из уравнения…
Например Медведев недавно завел себе страницу ВКонтакте — его добавило куча людей… Если я его тоже к себе добавлю — то со всеми теми людьми я буду знаком через 2 рукопожатия — автоматически… Так что цепочка сокращается… Надо выявлять такие персоны и исключать из уравнения…
Подписчики и друзья ВКонтакте — разные вещи. Я анализировал именно друзей, т.е. двусторонние связи, а вы говорите про односторонние. Или Дмитрий Анатолич лично вас зафрендил?
В конкретно этом случае — да… но я знаю несколько персон, которые добавляют…
Вот пруф: vkontakte.ru/epidemiya
Медведев не добавляет в друзья. На него можно только подписаться. Подписки и друзья не одно и то же.
>> Грубо говоря, 50 человек зафрендили друг друга и больше никого. Довольно странное поведение, не так ли?
Странное предположение. Вы верите что все жители россии зарегистрированы вконтакте? =)
Интернет — не подходящее место для таких исследований.
Люди, связывающих кластеры могут быть не зарегистрированы, а может их и нет вообще.
Хотел бы я посмотреть на цепочку между сборщиком риса в богом забытой северокорейской деревушке и урюпинским стритрейсером.
Странное предположение. Вы верите что все жители россии зарегистрированы вконтакте? =)
Интернет — не подходящее место для таких исследований.
Люди, связывающих кластеры могут быть не зарегистрированы, а может их и нет вообще.
Хотел бы я посмотреть на цепочку между сборщиком риса в богом забытой северокорейской деревушке и урюпинским стритрейсером.
* в смысле «социальные сети — не подходящее место для таких исследований.»
Вероятная цепочка из 6 рукопожатий:
1. Урюпинский стритрейсер.
[В городе c населением 40 тыс. человек, велика вероятность личного, пусть неблизкого знакомства
с мэром. Но быть стритрейсером в Урюпинске это… Может отец и есть мэр?]
2. Мэр Урюпинска Сергей Горняков.
[Встречался с Путиным недавно, дажелизнул шарф тому подарил.]
3. Владимир Путин.
[Принимал не единожды Яркую звезду Пэктусана, Солнце нации, Великого Руководителя Ким Чжон Ира.]
4. Ким Чен Ир.
[На съезде или конференции ТПК видел или даже пожал руку рядовому члену партии, например, Ким Ы.]
5. Ким Ы, член Трудовой партии Кореи.
[Ким Ы рассказывал на местном собрании о встрече с Великим Руководителем Ким Чжон Иром.
Его слушал, раскрыв рот, инминбанчжан Ким Чо.]
6. Ким Чо, инминбанчжан в деревушке.
[По долгу службы знает всё о сборщике риса.]
7. Сборщик риса в деревушке Северной Кореи.
8. PROFIT
1. Урюпинский стритрейсер.
[В городе c населением 40 тыс. человек, велика вероятность личного, пусть неблизкого знакомства
с мэром. Но быть стритрейсером в Урюпинске это… Может отец и есть мэр?]
2. Мэр Урюпинска Сергей Горняков.
[Встречался с Путиным недавно, даже
3. Владимир Путин.
[Принимал не единожды Яркую звезду Пэктусана, Солнце нации, Великого Руководителя Ким Чжон Ира.]
4. Ким Чен Ир.
[На съезде или конференции ТПК видел или даже пожал руку рядовому члену партии, например, Ким Ы.]
5. Ким Ы, член Трудовой партии Кореи.
[Ким Ы рассказывал на местном собрании о встрече с Великим Руководителем Ким Чжон Иром.
Его слушал, раскрыв рот, инминбанчжан Ким Чо.]
6. Ким Чо, инминбанчжан в деревушке.
[По долгу службы знает всё о сборщике риса.]
7. Сборщик риса в деревушке Северной Кореи.
> Мой взгляд был устремлен на ВКонтакте. Да, он охватывает только Россию и СНГ (причем неравномерно — в одноклассниках, к примеру, публика постарше). Да, там огромное количество ботов. ВКонтакте неидеален, но зато умеет раздавать список друзей в json-формате через запрос к al_friends.php.
Почему-то вспомнилось одно исследование качества бронирования самолетов, когда изучались самолеты, _вернувшиеся_ на аэродром. Материал доступен, можно вволю любоваться дырками от пуль, красота. Но слабость подхода в том, что если самолет вернулся, значит, он уже достаточно бронирован и выдерживает те повреждения, которые получил. Самое интересное — там, в полях.
Будет ли ваш результат репрезентативным, если мы для обсчета берем те данные, которые ближе? Можно ли составить впечатление об окружающей реальности, исключительно смотря телевизор?
Почему-то вспомнилось одно исследование качества бронирования самолетов, когда изучались самолеты, _вернувшиеся_ на аэродром. Материал доступен, можно вволю любоваться дырками от пуль, красота. Но слабость подхода в том, что если самолет вернулся, значит, он уже достаточно бронирован и выдерживает те повреждения, которые получил. Самое интересное — там, в полях.
Будет ли ваш результат репрезентативным, если мы для обсчета берем те данные, которые ближе? Можно ли составить впечатление об окружающей реальности, исключительно смотря телевизор?
Как интересно! У меня тут была идея прогнать один алгоритм на базе пользователей вконтакте, но я боялся, что если я попробую скачать полный граф друзей, меня быстро забанят. Хотите, кстати, обсудить идею? Возможно она Вас заинтересует.
новая постоянная константа, нужно придумать символ и присвоить
drugan = 6.6.6
drugan = 6.6.6
А можете ли базу где-нибудь выложить?
Во второй половине 90-х, когда я зарегистрировался в ICQ и узнал про теорию шести рукопожатий, возникла идея: вот бы сделать такой сайт, где люди будут указывать свои места работы и учебы, добавлять друзей, чтобы можно было находить общих знакомых, общаться и т.д. Много чего нафантазировал тогда. Есть свидетели )) Но идеи, говоря прямо, ничего без реализации не стоят.
А вот и линк на мой подобный эксперимент habrahabr.ru/blogs/crowdsourcing/39506/
Тогда АПИ ещё не было.
Тогда АПИ ещё не было.
> Грубо говоря, 50 человек зафрендили друг друга и больше никого. Довольно странное поведение, не так ли?
Ничего странного. Наверное учёт этих пользователей опровергнет теорию рукопожаний. Но вы ведь их выкинули.
Ничего странного. Наверное учёт этих пользователей опровергнет теорию рукопожаний. Но вы ведь их выкинули.
Ну так вот и опровергните, вас все расцелуют. Я просто не представляю то, как их можно было бы учесть.
Ты взялся доказывать, вот и доказывай! Я тебе говорю при доказательстве допускают одни и теже ошибки:
1. Нельзя выкидывать подмножества пользователей, только лишь из-за того что тебе они кажутся странными и не попадают под теорию.
2. Вытягивая только друзей и их их друзей, то фактически вытягиваешь только пользователей соединённых рукопожатиями и игнорируя остальных.
А то сначала выдвигаю теорию что любые два человека соединены рукопожатиями, в процессе проверки выкидывают все факты не подходящие под это условие, потом показывают цифру шесть и говорят что теория верна.
1. Нельзя выкидывать подмножества пользователей, только лишь из-за того что тебе они кажутся странными и не попадают под теорию.
2. Вытягивая только друзей и их их друзей, то фактически вытягиваешь только пользователей соединённых рукопожатиями и игнорируя остальных.
А то сначала выдвигаю теорию что любые два человека соединены рукопожатиями, в процессе проверки выкидывают все факты не подходящие под это условие, потом показывают цифру шесть и говорят что теория верна.
Использовали бы лучше API, получали бы по 1000 друзей, чем насиловать al_friends.php
Читали бы вы лучше документацию к API. Я не могу для случайного пользователя (т.е. который не разрешил мне вытягивать его друзей) вытянуть его контакты.
К тому же ограничение на 3 запроса в секунду никак не радует.
К тому же ограничение на 3 запроса в секунду никак не радует.
Читали бы вы лучше документацию к API. Лично я так и собирал. И этот лимит тоже обходится.
>т.е. который не разрешил мне вытягивать его друзей
Вот это главное ваше заблуждение.
Вот это главное ваше заблуждение.
Статистика по таким соц. сетям должна получиться очень смазанной и недостоверной. Сами прикиньте, какой процент друзей ВКонтакте реальные друзья человека, а не результаты случайных и одноразовых встреч? Для реальной проверки теории нужны более достоверные данные, чем данные соц. сетей по «друзьям».
Какие, если не секрет? Я на данный момент послал запрос данных в ZOG, обещали выгрузить все контакты всех людей на планете, в том числе и Ваши. Но пока у меня данных нет.
У меня таких данных тоже нет :) Если всерьез озадачиться проверкой данной теории, нужно тщательно планировать статистическое исследование. Хотя бы фильтровать публичные данные из тех же соц.сетей.
А что такое ZOG?
А что такое ZOG?
Меня уже били по голове на защите диссера за мои вольности со статистическими исследованиями. Каюсь, такая уж у меня привычка, хочется побыстрее увидеть результат.
А ZOG — это моя аллегория к тайному мировому правительству. В википедии об этом есть.
А ZOG — это моя аллегория к тайному мировому правительству. В википедии об этом есть.
Элементарно. Другом считается человек:
а) имеющий меньше тысячи друзей.
б) имеющий как минимум одного общего друга.
а) имеющий меньше тысячи друзей.
б) имеющий как минимум одного общего друга.
Не пойдет. Есть (и много) социально гиперактивные персоны, у которых много «друзей», больше тысячи, большая часть из которых — так, ни о чем, но есть и настоящие друзья. Причем таким гиперактивным псевдодругом связано огромное количество незнакомцев. Такие кадры и есть основной источник шума, но исключить их полностью нельзя, это нарушит чистоту эксперимента.
Не нарушит, а подтвердит. Если есть 6 рукопожатий в обход таких личностей, то напрямую уж точно теория будет подтверждена. Практика показывает, что их можно выкидывать безболезненно. Ну и самое главное — неличиче человека с 1000 друзьями нарушает чистоту эксперимента, т.к. любой критик может спросить: а правда, что все 1000 человек — его знакомые?
Т.е. если мы считаем, что знакомый — это запись в БД сайта — да, согласен, теория подтверждена, эксперимент чист.
Если мы считаем, что знакомый — реальный знакомый, то таких любей нужно удалять для чистоты эксперимента.
Длина цепочек, кстати, не уменьшится. Я наугад удалял с десяток человек в серединах цепочек, и всегда находился новый путь.
Т.е. если мы считаем, что знакомый — это запись в БД сайта — да, согласен, теория подтверждена, эксперимент чист.
Если мы считаем, что знакомый — реальный знакомый, то таких любей нужно удалять для чистоты эксперимента.
Длина цепочек, кстати, не уменьшится. Я наугад удалял с десяток человек в серединах цепочек, и всегда находился новый путь.
Отнюдь. Конечно, 1000 друзей вызывает вопросы о достоверности этих данных. А 500? А 200? Не вызывает? И исключать их тоже нельзя — это безосновательно, Вы не можете исключить возможность, что это действительно крайне социально активная личность и лично знаком со всеми этими людьми. То есть у Вас нет оснований устанавливать какой-либо верхний предел количества друзей. Проблема не в количестве связей, а в том, как отделить реальные связи от суррогатных. Вы либо удаляете всех социально активных людей из исследуемой выборки — это создаст наименьшую возможную выборку, если на ней теория подтвердится, то можно сделать более сильный вывод об истинности теории в целом, а если нет, то никаких выводов сделать нельзя. Либо сохраняете всех таких людей и получаете противоположную ситуацию (что получилось у автора). Либо определяете и, главное, обосновываете критерий выборки связей. Меньше тысячи — это слабый и совершенно необоснованный критерий.
тоже «Ёлки» посмотрели, да?
Кстати, есть одна мысль. Базу ведь можно выкачивать периодически и делать оценки по динамике.
Как пример, банально:
— акк, который за месяц не набрал ни одного друга, быстрее всего бот.
— акк, который набирает друзей со скоростью пылесоса (установить порог) — врядли знает их в реале.
Как пример, банально:
— акк, который за месяц не набрал ни одного друга, быстрее всего бот.
— акк, который набирает друзей со скоростью пылесоса (установить порог) — врядли знает их в реале.
Ну у меня некоторые знакомые-слоупоки, которые проспали эру социальных сетей, но неожиданно проснулись, как раз на первых порах насасывают какое-то бешеное количество друзей, штук по 50 в день. И, черт возьми, знают всех лично. Так что отсеивать ботов лучше комбинацией нескольких алгоритмов на основе скоринга.
Моему аккаунту года 3, но всего 38 друзей. Соответственно добавляются они сильно реже раза в месяц. Чесслово, я не бот, всего лишь держу во френдах узкий круг действительно друзей.
А еще меня смущает вот какой момент: неужели из 6773 пар людей не нашлось знакомых, которые в друзьях друг у друга или у них есть общий знакомый? В смысле вот есть гистограмма и в ней над цифрами 1 и 2 стоят нули — как такое может быть?
Там округление до второго знака после запятой:
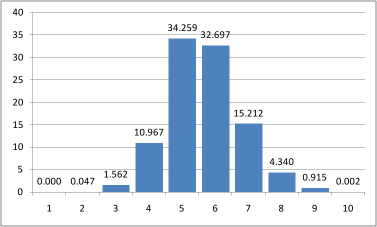
Прямых друзей не нашлось. Вероятность того, что два случайных пользователя друзья довольно мала:
всего живых идентификаторов вконтакте — 80М, в среднем 100 друзей, значит вероятность примерно равна 1/800000 или 0.000125%. Для 6700 пар вероятность того, что хотя бы одна пара будет друг у друга в друзьях — 0.83%, что тоже немного.

Прямых друзей не нашлось. Вероятность того, что два случайных пользователя друзья довольно мала:
всего живых идентификаторов вконтакте — 80М, в среднем 100 друзей, значит вероятность примерно равна 1/800000 или 0.000125%. Для 6700 пар вероятность того, что хотя бы одна пара будет друг у друга в друзьях — 0.83%, что тоже немного.
Предложение автору статьи по применению его расчетов: 6,6 рукопожатий для facebook, 5,6 рукопожатий для ВКонтакте — а что если отклонение в большую или меньшую сторону по рукопожатиям отображает силу связей, которые строит соцсеть?
То есть связи ВКонтакте намного прочнее, чем связи в facebook.
Рукопожатия в качестве ключевого показателя оценки соцсетей могли бы измерять качество связей, динамику этого качества, стоимость рекламы в зависимости от этого качества и другие производные показатели.
Такие исследования было бы интересно видеть в разрезе соцсетей и на постоянной основе.
То есть связи ВКонтакте намного прочнее, чем связи в facebook.
Рукопожатия в качестве ключевого показателя оценки соцсетей могли бы измерять качество связей, динамику этого качества, стоимость рекламы в зависимости от этого качества и другие производные показатели.
Такие исследования было бы интересно видеть в разрезе соцсетей и на постоянной основе.
Это не свидетельствует в пользу силы связей. Не забывайте, что Facebook имеет мировую аудиторию, а ВКонтакте — только жителей стран СНГ
Вы не совсем правильно поняли. Про Facebook я вообще ничего не писал, я писал про MSN/Microsoft, и у них ситуация получилась примерно такая же, между двумя случайными пользователями 6.6 рукопожатий.
Расскажите про LevelDB, как раз ею интересуюсь. Оно хорошо работает? Если хорошо, то в сравнении с чем?
Стабильно?
Спасибо.
Стабильно?
Спасибо.
Зависит от задач. Сравнивалось оно с Kyoto Cabinet.
1. После 4М вставок Kyoto Cabinet начинал жестоко тормозить (100% cpu usage), не особенно реагируя на какой-либо тюнинг настроек. Количество вставок в секунду упало раз в 10-15.
2. LevelDB стойко перенес базу в 22Гб, скорость вставки, конечно упала, но не сильно значительно.
3. LevelDB несколько раз бил базу при некорректном завершении программы. Он же ее, к тому же, в read-only не умеет открывать, всегда норовит что-то в ней поменять.
4. Может я криворук, может это глюк, но при агрессивном чтении из базы она почему-то понемногу пухнет, где-то на 5Гб в час. Аномалия какая-то.
Вообще, это был мой первый опыт с LevelDB, и боюсь что последний. В дальнейшем вернусь на Redis.
1. После 4М вставок Kyoto Cabinet начинал жестоко тормозить (100% cpu usage), не особенно реагируя на какой-либо тюнинг настроек. Количество вставок в секунду упало раз в 10-15.
2. LevelDB стойко перенес базу в 22Гб, скорость вставки, конечно упала, но не сильно значительно.
3. LevelDB несколько раз бил базу при некорректном завершении программы. Он же ее, к тому же, в read-only не умеет открывать, всегда норовит что-то в ней поменять.
4. Может я криворук, может это глюк, но при агрессивном чтении из базы она почему-то понемногу пухнет, где-то на 5Гб в час. Аномалия какая-то.
Вообще, это был мой первый опыт с LevelDB, и боюсь что последний. В дальнейшем вернусь на Redis.
Sign up to leave a comment.
Теория шести рукопожатий: еще одно подтверждение