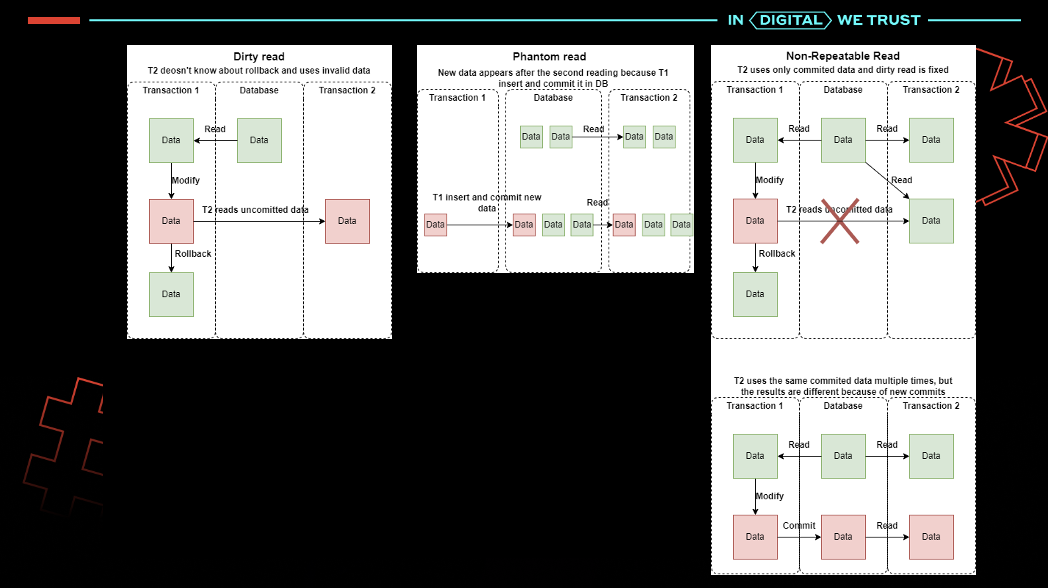
Различные СУБД предлагают широкий набор разновидностей операторов JOIN для таблиц. Если Вам встретилась проблема с производительностью CROSS JOIN, - например, декартово произведение таблицы с миллионом записей самой на себя, - добро пожаловать, в этой статье перечислены простейшие способы избавиться от CROSS JOIN.
Конечно, можно пересмотреть и упростить саму бизнес-логику или способы расчетов, в данной статье рассмотрены некоторые базовые случаи, про которые не стоит забывать и имеет смысл проверять первыми. Надеюсь, они окажутся релевантными или смогут помочь найти другие SQL оптимизации.
Примеры в статье рассматриваются на основе CROSS JOIN из ClickHouse. Текущая версия ClickHouse не оптимизирует CROSS JOIN автоматически. Также стоит отметить, что поскольку часто SQL запросы не пишутся вручную, а, например, собираются по частям программно, то перечисленные далее случаи вполне реальны.