
Собственно, сабж.
На это указывает ряд моментов в существующих решениях.
Прежде всего, давайте вспомним, какими важными характеристиками обладает файл?
Собственно, сабж.
На это указывает ряд моментов в существующих решениях.
Прежде всего, давайте вспомним, какими важными характеристиками обладает файл?

Меня зовут Виталий Киреев, я руководитель R&D в SpaceWeb. В начале прошлого года мы внедрили IPFS-технологию в работу своего хостинга, и все наши клиенты получили возможность размещать контент в IPFS-сети. Решились на такой шаг не сразу: IPFS — технология пока еще экспериментальная, к ней и у R&D-команды полно вопросов.
В статье расскажем об основных принципах устройства IPFS, обсудим преимущества и недостатки. А еще поделимся, зачем вообще классическому хостинг-провайдеру было внедрять IPFS-технологию и с какими трудностями мы столкнулись в процессе. Статья будет полезна тем, кто только начинает знакомиться с IPFS или планирует использовать технологию для своих проектов.

Есть много причин почему доступ научным статьям и книгам должен быть свободным:
Во-первых, это прекрасно

Протоколу давно пророчат светлое будущее в качестве замены HTTP. Об этом мы говорили в одном из прошлых материалов. И сегодня решили взглянуть, как обстоят дела с внедрением IPFS и какие факторы замедляют распространение.
Основная задача:
Изучить, как хранить данные IoT на комбинации on-chain (Ethereum Blockchain) и off-chain хранилищ (IPFS и Ethereum Swarm) в зашифрованном виде и использовать их в модели публикации-подписки в режиме реального времени без использования каких-либо протоколов M2M, таких как MQTT или CoAP. Оценить производительность этой системы с точки зрения количества транзакций, которые могут быть выполнены в секунду и оптимизировать ее работу.
Предыдущие части статьи:
Безопасное хранение данных IoT в частном блокчейне Ethereum. Часть 1
Безопасное хранение данных IoT в частном блокчейне Ethereum. Часть 2
В этой части статьи в главе 6 мы проводим эксперименты по хранению данных с использованием традиционных баз данных, а также предложенной системы с использованием Ethereum Blockchain, IPFS и Swarm. Чтобы понять стоимость безопасности IoT, мы проводим эксперименты по оценке производительности предложенной системы.
В главе 7 мы попытаемся обобщить выводы, сделанные в данной статье, и завершим ее ретроспективным обзором 2 измерений производительности этих систем хранения данных вместе с блокчейном.

Напомним про основную задачу:
Изучить, как хранить данные IoT на комбинации on-chain (Ethereum Blockchain) и off-chain хранилищ (IPFS и Ethereum Swarm) в зашифрованном виде и использовать их в модели публикации-подписки в режиме реального времени без использования каких-либо протоколов M2M, таких как MQTT или CoAP. Оценить производительность этой системы с точки зрения количества транзакций, которые могут быть выполнены в секунду и оптимизировать ее работу.
Краткое содержание данной части статьи:
В главе 4 мы описываем терминологию, протоколы и устройства IoT, рассматриваемые для использования в нашей статье. Мы также рассмотрим, как установить корень доверия для этих устройств и обеспечить функции безопасности с помощью внешнего оборудования.
В главе 5 мы описываем предложенную систему хранения данных в блокчейн и вне блокчейн для децентрализованного хранения данных с датчиков. Мы также описываем смарт-контракт, используемый для регистрации IoT-устройств и хранения данных.

Интернет вещей (IoT) — это набор технологий, которые позволяют подключенным к сети устройствам выполнять действия или обмениваться данными между несколькими подключенными устройствами или с общей базой данных. Действия могут могут быть любыми: от дистанционного включения кондиционера воздуха до включения зажигания автомобиля с помощью команды, поданной из удаленного места, или попросить Alexa или Google Assistant найти информацию о погодных условиях в том или ином районе. IoT доказал свою эффективность во многих отраслях промышленности таких как цепочки поставок, доставка и транспортировка, предоставляя информацию о состоянии грузов в режиме реального времени. Это привело к появлению огромного количества данных, создаваемых множеством таких устройств. которые необходимо обрабатывать в режиме реального времени.
В данной статье мы предлагаем метод сбора информации с датчиков устройств IoT и использования блокчейна для хранения и получения собранных данных для безопасного и децентрализованного хранения и извлечения собранных данных в рамках закрытой системы, подходящей для одного предприятия или группы компаний в таких отраслях как, например, судоходство, где требуется обмен данных друг с другом. Подобно блокчейну, мы представляем себе будущее, в котором устройства IoT смогут подключаться и отключаться к распределенным системам, не вызывая простоя в сборе и хранении данных или не полагаясь на облачные технологии хранения или полагаться на облачную систему хранения для синхронизации данных между устройствами. Мы также рассмотрим производительность некоторых из этих распределенных систем, таких как Inter Planetary File System (IPFS) и Ethereum Swarm на маломощных устройствах, таких как raspberry pi.
Перевод статьи начального уровня в блоге проекта Textile от 12 декабря 2019 г.
В предыдущей статье мы начали с вопроса: «Как подойти к своему первому p2p-приложению?» После недолгих размышлений мы быстро пришли к выводу, что решение не полагаться на централизованный сервер и сосредоточиться на том, чтобы сделать приложение для равноправных узлов, сопряжено с множеством дополнительных сложностей. Две основные группы «проблем» - это состояние приложения и инфраструктурное разнообразие протоколов. К счастью, мы обнаружили, что нам не нужно изобретать велосипед, заново решая груду инфраструктурных задач - вместо того мы можем использовать великолепный сетевой p2p-стек: библиотеку libp2p.
В сегодняшнем посте мы пойдем немного дальше и представим «игрушечное» приложение, чтобы почувствовать, как на самом деле можно что-то разрабатывать с помощью libp2p, и, надеюсь, мотивировать вас создать собственное p2p-приложение. Серьезно, вы удивитесь, насколько это просто!
Приложение
Сразу оговоримся, наша программа нынче будет написана на языке Go, с использованием библиотеки go-libp2p. Если вы ещё не знакомы с этим языком, настоятельно рекомендуем ознакомиться. Он действительно хорош для приложений, имеющих дело с параллелизмом и сетевыми взаимодействиями (такими, как например, обработка множества p2p-соединений). Большинство библиотек IPFS/libp2p имеют свои базовые реализации, написанные на Go. Прекрасным введением в Go является тур на golang.org.
Итак, наша программка будет простым приложением для пинг-понга с некоторыми добавочными настройками, чтобы сделать её более интересной, в отличие от обычных безыскусных примеров. Вот некоторые особенности нашего приложения (не волнуйтесь, мы расскажем подробней об этих пунктах позже):
Перевод статьи начального уровня в блоге проекта Textile от 19 ноября 2019 г.
Первые шаги к созданию децентрализованного приложения могут быть трудными. Изменить привычный при разработке централизованных приложений образ мышления не легко, поскольку распределённый дизайн ломает большинство допущений, устоявшихся в наших мозгах (и программных инструментов, которые мы используем). Чтобы проиллюстрировать то, как наша команда представляет себе одноранговую коммуникацию, мы выпускаем серию из двух статей, посвященную стеку протоколов libp2p. В этой первой статье мы размышляем о некоторых сложностях, связанных с созданием децентрализованных приложений, и выясняем, как абстракция уровня сетевого протокола, такая как libp2p, может нам помочь. В следующей статье (которая скоро появится) мы будем использовать эти же концепции для создания простого примера, написанного на языке Go, чтобы понять, как различные компоненты, о которых мы здесь говорим, связаны друг с другом.
Стремительно нарастающая сложность
Внедрить распределённое (p2p) взаимодействие в какое бы то ни было приложение - задача не из простых. Попредставляйте лишь пару минут, как должно работать ваше творение - и всё начинает усложняться прямо на глазах. Рассмотрим две основные проблемы для p2p-приложений: состояние приложения и инфраструктура взаимодействия. Управление текущим состоянием системы не тривиально. Нет центрального органа, который бы его определял. Состояние системы - производное от состояний множества других узлов, которое имеет взрывную сложность в ненадежных сетях и сложных протоколах. Что касается инфраструктуры связи, ваше приложение должно взаимодействовать со многими равноправными узлами, поэтому вам придется столкнуться с изрядным количеством проблем.


Эта статья о следующем эволюционном шаге в развитии систем обработки данных. Тема амбициозная, поэтому расскажу сначала немного о себе. Вот уже больше 10 лет я работаю над проектами в области CRDT и синхронизации данных. За это время успел поработать на университеты, стартапы YCombinator и известные международные компании. Мой проект последние три года – Replicated Object Notation, новый формат представления данных, сочетающий возможности объектной нотации (как JSON или YAML), сетевого протокола и оплога/бинлога. Вы могли слышать про другие проекты, работающие в том же направлении, например, Datanet, Automerge и другие. Также вы могли читать Local-first software, это наиболее полный манифест данного направления Computer Science. Авторы - замечательный коллектив Ink&Switch, включая широко нам известного по "Книге с Кабанчиком" М.Клеппманна. Или вы, возможно, слушали мои выступления по этой теме на различных конференциях.
Идеи этой статьи перекликаются с тем, что пишет последние годы Pat Helland: Immutability Changes Everything и др. Они смежны с проектами IPFS и DAT, к которым я имею отношение.
Итак. Классические БД выстроены на линейном логе операций (WAL). От этого лога выстроены транзакции, от него же выстроена репликация master-slave. Теория репликации с линейным логом написана ещё в начале 1980-х с участием небезызвестного Л. Лампорта. В классических legacy системах с одной большой центральной базой данных всё это работает хорошо. Так работают Oracle, Postresql, MySQL, DB2 и прочие классические SQL БД. Так работают и многие key-value БД, например, LevelDB/RocksDB.
Но линеаризация не масштабируется. Когда система становится распределённой, всё это начинает ломаться. Образно говоря, линейная система – это что-то вроде греческой фаланги. Нужно, чтобы все шли ровно, а для этого хорошо, чтобы земля была везде ровной. Так получается не всегда: где-то электричество отключили, а где-то сеть медленная. Хотя в системе Google Spanner и было показано, что с достаточно большим бюджетом землю можно сделать ровной абсолютно везде, мы всё же отметим, что Google тоже бывает отключается целиком по совершенно смешным причинам.
Существует проблема: У сайта в IPFS нет возможности использовать серверные скрипты для формирования страницы. Если использовать генерацию страниц перед загрузкой то добавив новый пункт меню в каждую страницу мы изменим хеш этих страниц. Так что всю сборку страниц нужно производить силами браузера.
Обычно формируют содержание страниц при помощи JavaScript. Это знакомая технология но у неё есть свои недостатки.
Я буду использовать XSLT. Это древняя технология шаблонов которая давно встроена в браузеры но мало кто ей пользуется. Возможно потому что шаблоны заставляют писать много текста и из за путаницы с пространствами имён и множества ошибок без внятного объяснения. Также не смотря на то что есть уже XSLT 3.0 в браузерах по прежнему доступен только XSLT 1.0.
XSLT работает так:
<?xml-stylesheet href="xslt/запись.xslt" type="text/xsl" ?>Привязав множество страниц к одному шаблону можно менять отображаемый xHTML документ не меняя XML документы. Таким образом при смене дизайна не будет меняться хеш XML документов а значит старые их копии будут источниками для новых в IPFS.
Для поисковиков в данном способе тоже есть плюсы. Они ограничиваются обработкой XML документа получая только уникальный контент страницы без элементов навигации и остальных блоков которые повторяются на каждой странице.
























Недавно в IPFS добавили поддержу тривиального (identity) хеша. В своей статье я расскажу о нём и покажу как его можно использовать.
Напомню: InterPlanetary File System — это новая децентрализованная сеть обмена файлами (HTTP-сервер, Content Delivery Network). О ней я начал рассказ в статье "Межпланетная файловая система IPFS".
Обычно при хешировании проходя через хеш-функцию данные необратимо "сжимаются" и в результате получается короткий идентификатор. Этот идентификатор позволяет найти данные в сети и проверить их целостность.
Тривиальный хеш — это сами данные. Данные никак не изменяются и соответственно размер "хеша" равен размеру данных.
Тривиальный хеш выполняет ту же функцию что и Data: URL. Идентификатор контента в этом случае содержит сами данные вместо хеша. Это позволяет вкладывать дочерние блоки в родительский делая их доступными сразу после получения родительского. Также можно включать данные сайта непосредственно в DNS запись.
Для примера закодируем текстовую строку "Привет мир" в идентификатор контета(CID) с тривиальным хешем.
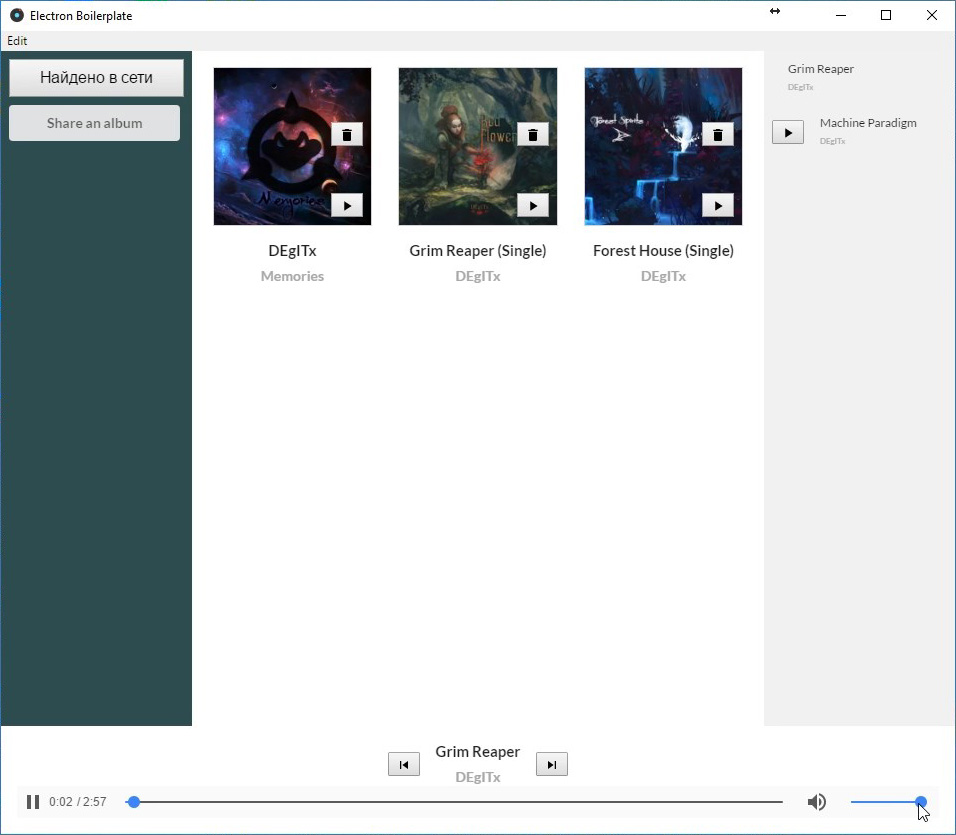
В этой статье описаны результаты двухмесячных экспериментов с IPFS. Главным итогом этих экспериментов стало создание proof-of-concept стримингового аудио плеера, способного формировать фонотеку исключительно на основе информации, публикуемой в распределённой сети IPFS, начиная с метаданных (название альбома, треклист, обложка), заканчивая непосредственно аудио-файлами.
Таким образом, будучи десктопным electron-приложением, плеер не зависит ни от одного централизованного ресурса.
Мало смысла в IPFS, если использовать его только как бесплатный хостинг для сайта в сети интернет. Поэтому мы научимся здесь загружать наш сайт через локальный IPFS шлюз пользователя.
Пользователю это даст быстрый доступ к его локальной копии нашего сайта.
Напомню: InterPlanetary File System — это новая децентрализованная сеть обмена файлами (HTTP-сервер, Content Delivery Network). О ней я начал рассказ в статье "Межпланетная файловая система IPFS".
Мы научимся переключать на свой локальный шлюз IPFS сайты, которые этого ещё не делают сами автоматически. Создадим им общий SSL сертификат при помощи OpenSSL в комплекте со Stunnel.
Напоминаю: InterPlanetary File System — это новая децентрализованная сеть обмена файлами (HTTP-сервер, Content Delivery Network). О ней я рассказывал в статье "Межпланетная файловая система IPFS".

Всем хороша идея IPFS но вот только был один недостаток у неё. Данные загружаемые в сеть копировались в хранилище блоков удваивая занимаемое ими место. Более того файл резался на блоки которые мало пригодны для повторного использования.
Появилась экспериментальная опция --nocopy, которая избавляет от этого недостатка. Для того чтобы пользоваться ей необходимо выполнить несколько условий.
Также появился новый тип идентификаторов. Его мы тоже разберём.
Напомню: InterPlanetary File System — это новая децентрализованная сеть обмена файлами (HTTP-сервер, Content Delivery Network). О ней я начал рассказ в статье "Межпланетная файловая система IPFS".
 Я вспомнил что не рассказал важную часть для обеспечения возможности общения и обновления контента в P2P сетях.
Я вспомнил что не рассказал важную часть для обеспечения возможности общения и обновления контента в P2P сетях.
Не все P2P сети имеют возможность отправки и приёма личных сообщений. Также не всегда сообщение можно оставить в оффлайн. Мы исправим этот недостаток используя три возможности P2P сетей: поиск файла, просмотр шары(списка опубликованных файлов) или комментарии к файлу.
Шаблон маяка создаётся однократно и используется для создания маяков для связи с автором.
Наше сообщение и маяк свободно могут копировать другие участники сети. Так как оно зашифровано они не смогут его прочитать но помогут его держать онлайн пока его не получит адресат.
