
Цикл постов про Keycloak (часть 1): Внедрение.
О чем речь?
Это первая часть серии статей о переходе на Keycloak в качестве SSO в условиях кровавого enterprise.

Ведущий инженер по внедрению ПО
Цикл постов про Keycloak (часть 1): Внедрение.
О чем речь?
Это первая часть серии статей о переходе на Keycloak в качестве SSO в условиях кровавого enterprise.
В настоящее время тема миграции с СУБД Oracle на СУБД PostgreSQL (и разработанную на её основе СУБД Postgres Pro) является очень актуальной. В этой области у команды Postgres Professional накоплен многолетний опыт, которым мы решили поделиться. На основе наших материалов для внутреннего обучения мы подготовили серию статей для Хабра о миграции данных в PostgreSQL из «оракловой» базы.
Также на близкие темы можно посмотреть следующие доклады и мастер-классы.

Пример использования процессора JoltTransformJson в Apache NiFi. Можно рассматривать как небольшой туториал по использованию Jolt-спецификаций.

В прошлый раз я подробно рассказывал об особенностях компании-вендора. Теперь настало время поговорить о мифах и правде в работе компании-вендора. Если тема вам интересна, то давайте начнём.
Миф 1. Особые продуктовые специалисты
Один из наиболее стойких и распространенных мифов. Будто бы существует особый вид специалиста - продуктовый разработчик или продуктовый тестировщик. Очень редкий и ценный зверь. Мне кажется, что таких специальностей не бывает, но, что действительно существует, так это определенные особенности, присущие разработке продукта и как, следствие, продуктовая разработка может показаться скучной или тесной для некоторых людей.
Попробуем разобраться с качествами технического специалиста, которыми мы чаще всего оперируем для оценки в жизни:
Хороший vs Плохой
Соблазн применить эту категорию очень велик. «Хорошесть» или «плохость» не зависит от места работы, опыта работы, роста или цвета глаз. Это интегральная экспертная оценка ;-). Хорошего программиста видно по его коду, который компактен, понятен, легко поддерживается. Хорошего QA видно по въедливости, упорядоченности и понятности его кейсов. Видно его по вопросам, которые он задет до/при реализации/тестировании.
Это видно по скорости и уровню погружения в решаемую задачу и, в конце концов, по тому, к кому ходят задавать вопросы. И я не знаю, как это измерить в попугаях. Так вот, плотность хороших спецов в продуктах, аутсорсе, финтехе, abap, 1с, фронте и бэке одинаковая. И это качество точно не является специфичным для какой-то одной отрасли или направления.


Когда вы автоматизируете какую-либо задачу, например, упаковываете свое приложение для Docker, то часто сталкиваетесь с написанием shell-скриптов. У вас может быть bash-скрипт для управления процессом упаковки и другой скрипт в качестве точки входа в контейнер. По мере возрастающей сложности при упаковке меняется и ваш shell-скрипт.
Все работает хорошо.
И вот однажды shell-скрипт совершает что-то совсем неправильное.
Тогда вы осознаете свою ошибку: bash, и вообще shell-скрипты, в основном, по умолчанию не работают. Если с самого начала не проявить особую осторожность, любой shell-скрипт достигнув определенного уровня сложности почти гарантированно будет глючным... а доработка функций корректности будет довольно затруднительна.

 Еще я веду канал в Telegram: GameDEVils, делюсь там клевыми материалами (про геймдизайн, разработку и историю игр).
Еще я веду канал в Telegram: GameDEVils, делюсь там клевыми материалами (про геймдизайн, разработку и историю игр).
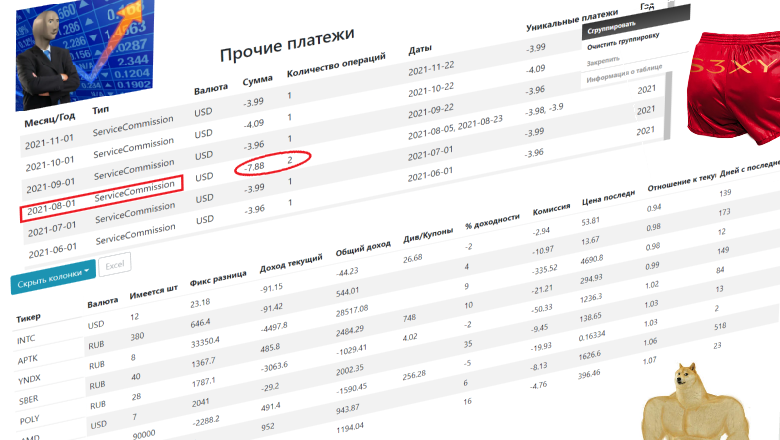
У меня, как у пользователя Тинькофф Инвестиций, часто возникали вопросы: какие акции за весь период торговли принесли мне наибольший доход; сколько всего я заплатил за обслуживание тарифа и прочие комиссии; какие акции в портфеле давно лежат и не приносят мне доход; как отсортировать акции в своем портфеле по какому-либо критерию.
Текущая аналитика брокера показывает только открытые позиции, а профиль в "пульсе" подсчитывает лишь общий процент, без конкретики. Это не дает возможность увидеть «настоящую» картину своего портфеля.
К примеру, покупаем 1 акцию по 1000, после падения до 900 усредняем еще одной акцией. Затем при отскоке до 950 продаем 1 акцию. В итоге оставшаяся акция в портфеле "горит зеленым" (образуется плюс +50 по правилу fifo), хотя фактический результат бумаги на данный момент будет 0 (без учета комиссий). Такое отображение бумаг в приложении может сбить с толку, и привести к неправильным решениям и большим потерям, при совершении множества сделок.
Идея вести дневник сделок в excel, или периодически копаться в налоговом/брокерском отчете, мне не понравилась. Зато приглянулась мысль - обрабатывать данные полученные из официального API.
Результатом стал онлайн-инструмент, в который легко загрузить историю операций. После чего она отображается в табличном виде, с которыми удобно работать.
В статье я продемонстрирую, как пользоваться созданным инструментом, и какие задачи решаются. Подсвечу некоторые особенности данных полученных из API.
Продолжение публикации: "Что недоговаривают Тинькофф Инвестиции. Вытаскиваем все данные по портфелю через API в большую таблицу Excel".
В этот раз поговорим о совершённых доработках, всплывших подводных камнях, исправленных ошибках, участии сообщества, подсчитаем XIRR и попробуем сравнить доходность портфеля за 3 года с другими видами инвестиций.
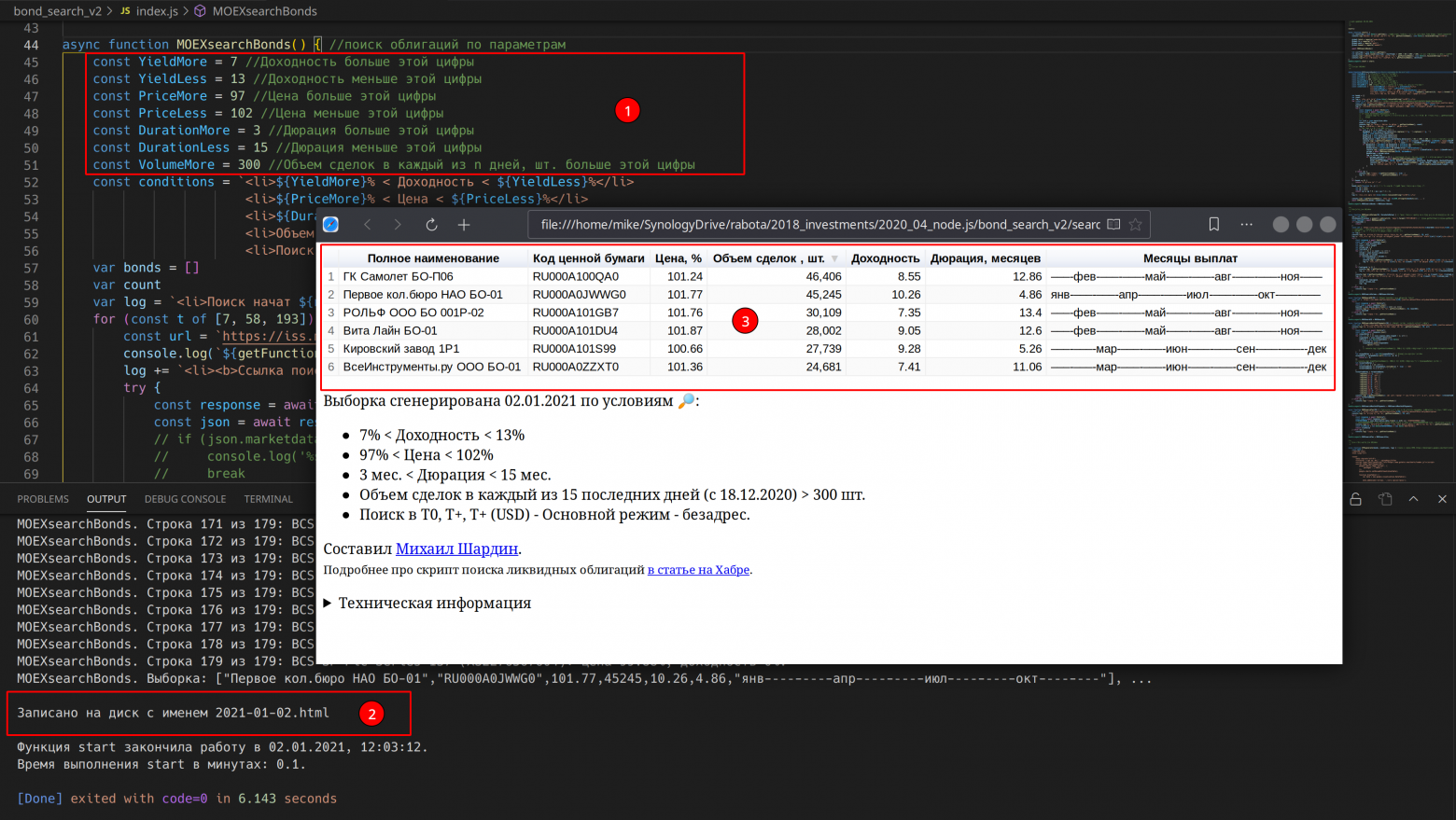
Полгода назад, летом 2020 года я написал скрипт поиска ликвидных облигаций на Мосбирже (статья в закладках у 194 человек, рейтинг +45). Скрипт нужен для поиска облигаций, которые можно купить прямо сейчас с доходностью гораздо выше банковского вклада.
Сейчас, в начале 2021 года модифицировал прошлогодний скрипт, потому что проценты по вкладам так и остаются на очень низких уровнях, а с началом 2021 года ещё и изменения в налоговом кодексе РФ подоспели.
Переписал код, убрав неактуальные данные о налоговых льготах, которые сейчас уже не работают и добавил возможность создавать облигационные лесенки. Под лесенкой имеется ввиду получение дохода как можно в большом числе месяцев, за счёт подбора облигаций с разными месяцами выплат.

Вы вряд ли найдете в интернете что-то про разработку ботов, кроме документаций к библиотекам, историй "как я создал такого-то бота" и туториалов вроде "как создать бота, который будет говорить hello world". При этом многие неочевидные моменты просто нигде не описаны.
Как вообще устроены боты? Как они взаимодействуют с пользователями? Что с их помощью можно реализовать, а что нельзя?
Подробный гайд о том, как работать с ботами — под катом.






Определение Докера в Википедии звучит так:
программное обеспечение для автоматизации развёртывания и управления приложениями в среде виртуализации на уровне операционной системы; позволяет «упаковать» приложение со всем его окружением и зависимостями в контейнер, а также предоставляет среду по управлению контейнерами.
Ого! Как много информации.