Чтобы обучать нейросети понимать и генерировать человеческие языки, нужно много качественных текстов на нужных языках. «Много» – не проблема в эпоху интернета, но с качеством бывают сложности. В этом посте я предлагаю использовать BERT-подобные модели для двух задач улучшения качества обучающих текстов: исправление ошибок распознавания текста из сканов и фильтрация параллельного корпуса предложений. Я испробовал их на башкирском, но и для других языков эти рецепты могут оказаться полезны.

Давид Дале @cointegrated
Разработчик / Аналитик / Data Scientist / NLPшник
Первый нейросетевой переводчик для эрзянского языка
10 min
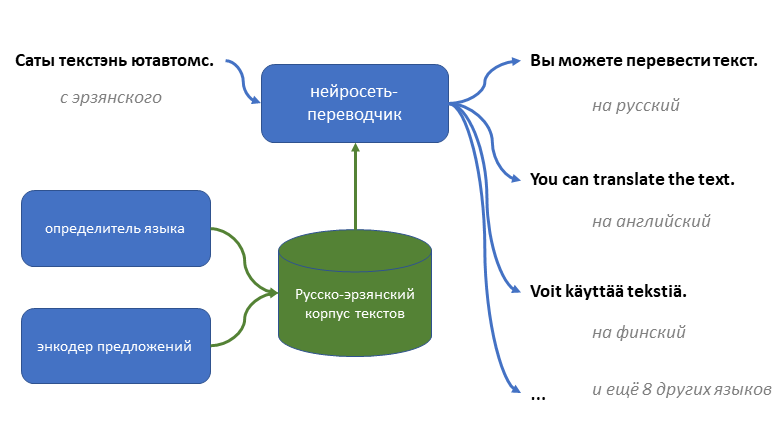
Эрзянский язык из финно-угорской семьи – один из официальных в республике Мордовия, и на нём говорят сотни тысяч людей, но для него до сих пор не было почти никаких технологий машинного перевода, кроме простых словарей.
Я попробовал создать первую нейросеть, способную переводить с эрзянского на русский (и с натяжкой ещё на 10 языков) и обратно не только слова, но и целые предложения.
Пока её качество оставляет желать лучшего, но пробовать пользоваться уже можно.
Как я собирал для этого тексты и обучал модели – под катом.
Восстанавливаем предложения из эмбеддингов LaBSE
8 min
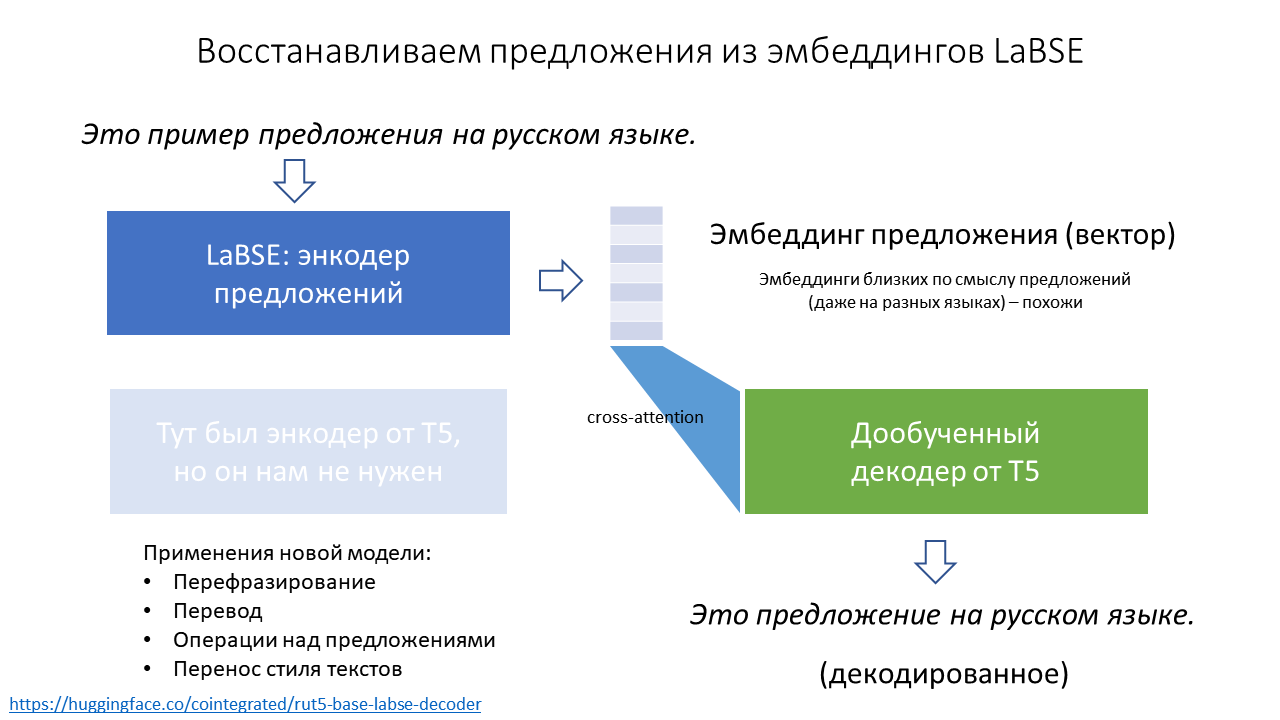
На прошлой неделе меня дважды спрашивали, как восстановить текст предложения из его LaBSE эмбеддинга. Я дважды отвечал, что никак. Но на самом деле, конечно, можно обучить декодер генерировать текст по его эмбеддингу. Зачем? Например, чтобы переводить с 100 языков на русский, перефразировать предложения, модифицировать их смысл или стиль.
Модель для восстановления предложений из эмбеддингов опубликована как cointegrated/rut5-base-labse-decoder, а подробности – под катом.
Рейтинг русскоязычных энкодеров предложений
9 min

Энкодер предложений (sentence encoder) – это модель, которая сопоставляет коротким текстам векторы в многомерном пространстве, причём так, что у текстов, похожих по смыслу, и векторы тоже похожи. Обычно для этой цели используются нейросети, а полученные векторы называются эмбеддингами. Они полезны для кучи задач, например, few-shot классификации текстов, семантического поиска, или оценки качества перефразирования.
Но некоторые из таких полезных моделей занимают очень много памяти или работают медленно, особенно на обычных CPU. Можно ли выбрать наилучший энкодер предложений с учётом качества, быстродействия, и памяти? Я сравнил 25 энкодеров на 10 задачах и составил их рейтинг. Самой качественной моделью оказался mUSE, самой быстрой из предобученных – FastText, а по балансу скорости и качества победил rubert-tiny2. Код бенчмарка выложен в репозитории encodechka, а подробности – под катом.
Нейросети для Natural Language Inference (NLI): логические умозаключения на русском языке
9 min
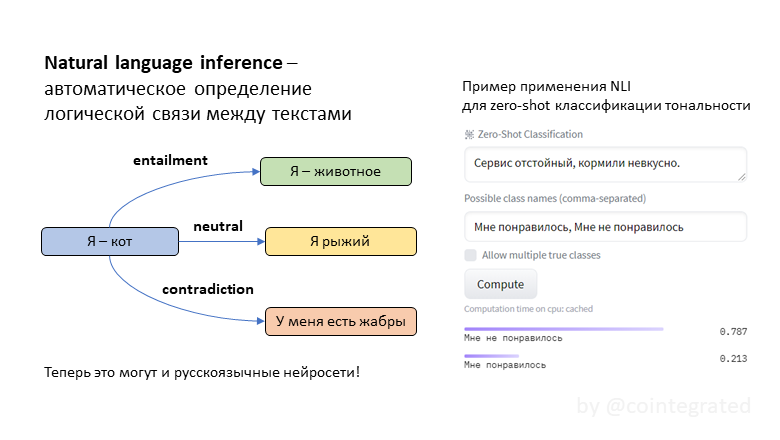
NLI (natural language inference) – это задача автоматического определения логической связи между текстами. Обычно она формулируется так: для двух утверждений A и B надо выяснить, следует ли B из A. Эта задача сложная, потому что она требует хорошо понимать смысл текстов. Эта задача полезная, потому что "понимательную" способность модели можно эксплуатировать для прикладных задач типа классификации текстов. Иногда такая классификация неплохо работает даже без обучающей выборки!
До сих пор в открытом доступе не было нейросетей, специализированных на задаче NLI для русского языка, но теперь я обучил целых три: tiny, twoway и threeway. Зачем эти модели нужны, как они обучались, и в чём между ними разница – под катом.
Многозадачная модель T5 для русского языка
7 min
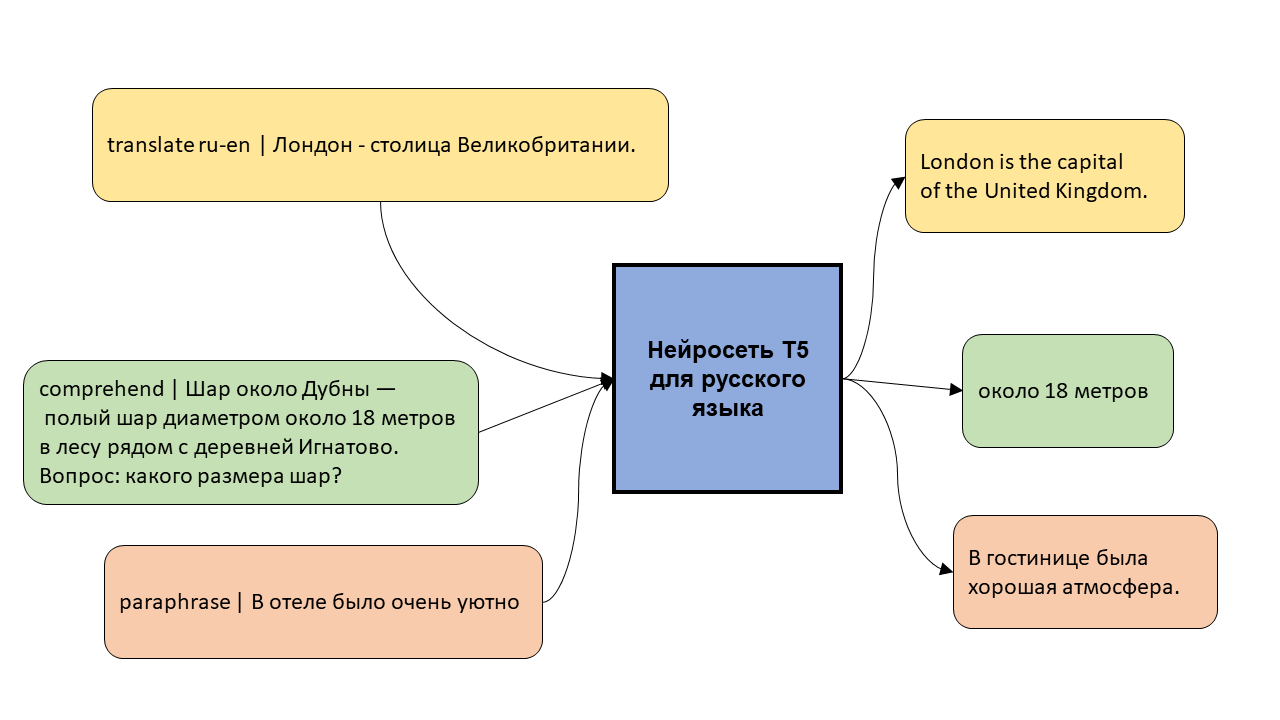
Модель T5 – это нейросеть, которая уже обучена хорошо понимать и генерировать текст, и которую можно дообучить на собственную задачу, будь то перевод, суммаризация текстов, или генерация ответа чат-бота.
В этом посте я рассказываю про первую многозадачную модель T5 для русского языка и показываю, как её можно обучить на новой задаче.
Лучшие навыки Алисы и советы от их разработчиков
8 min
Я уже довольно давно разрабатываю навыки для Яндекс.Алисы, но пока не создал ни одного популярного. Недавно мне стало интересно: а какие навыки становятся самыми популярными, и кто те люди, которые их создают? Чтобы ответить на этот вопрос, я проанализировал каталог Алисы и опросил 20 разработчиков, чьи навыки набрали наибольшее количество оценок "пять". Похоже, что к их советам стоит прислушаться.
Перефразирование русских текстов: корпуса, модели, метрики
13 min
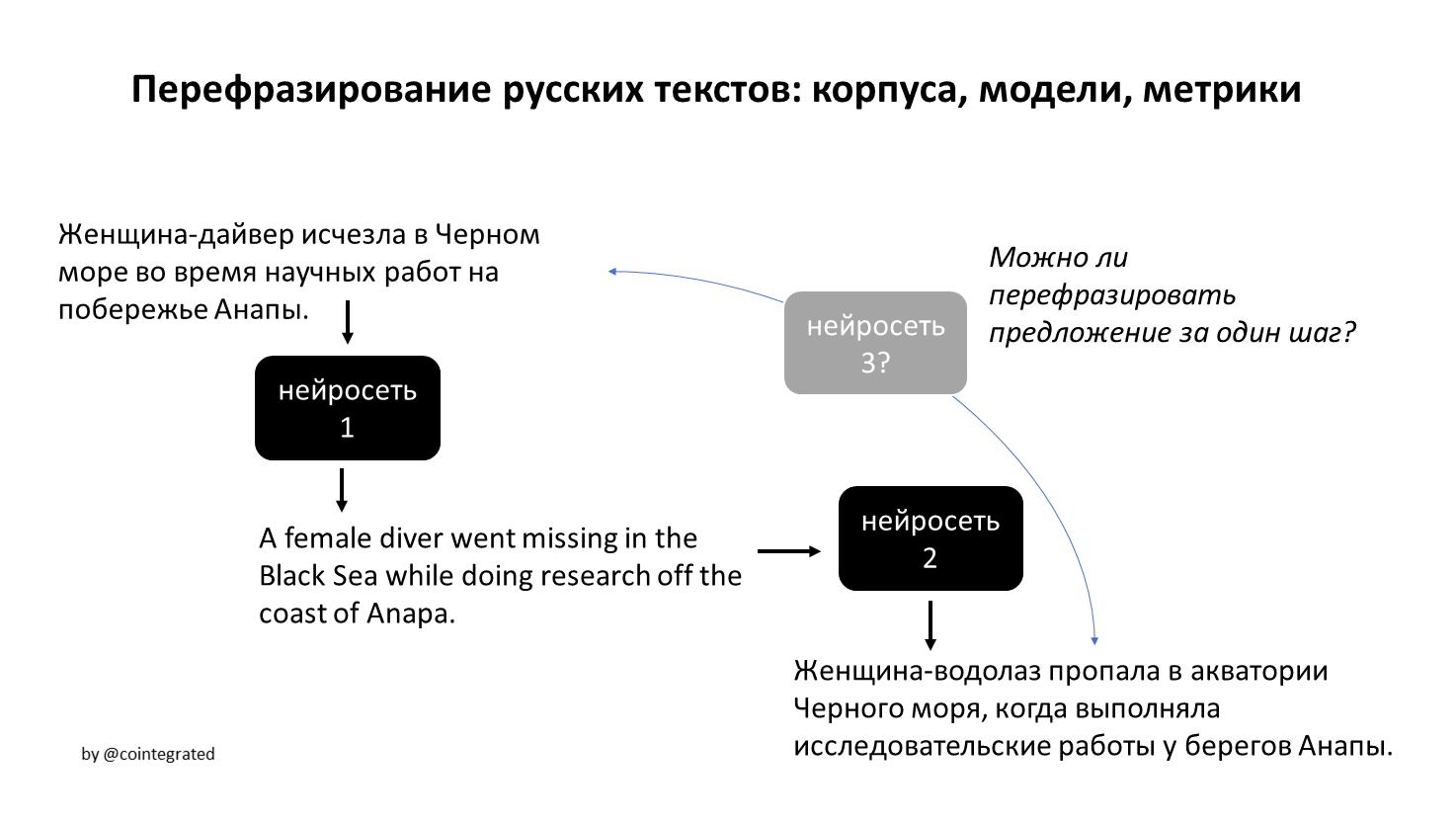
Автоматическое перефразирование текстов может быть полезно в куче задач, от рерайтинга текстов до аугментации данных. В этой статье я собрал русскоязычные корпуса и модели парафраз, а также попробовал создать собственный корпус, обучить свою модель для перефразирования, и собрать набор автоматических метрик для оценки их качества.
В итоге оказалось, что модель для перевода перефразирует лучше, чем специализированные модели. Но, по крайней мере, стало более понятно, чего вообще от автоматического перефразирования можно хотеть и ожидать.
Маленький и быстрый BERT для русского языка
9 min
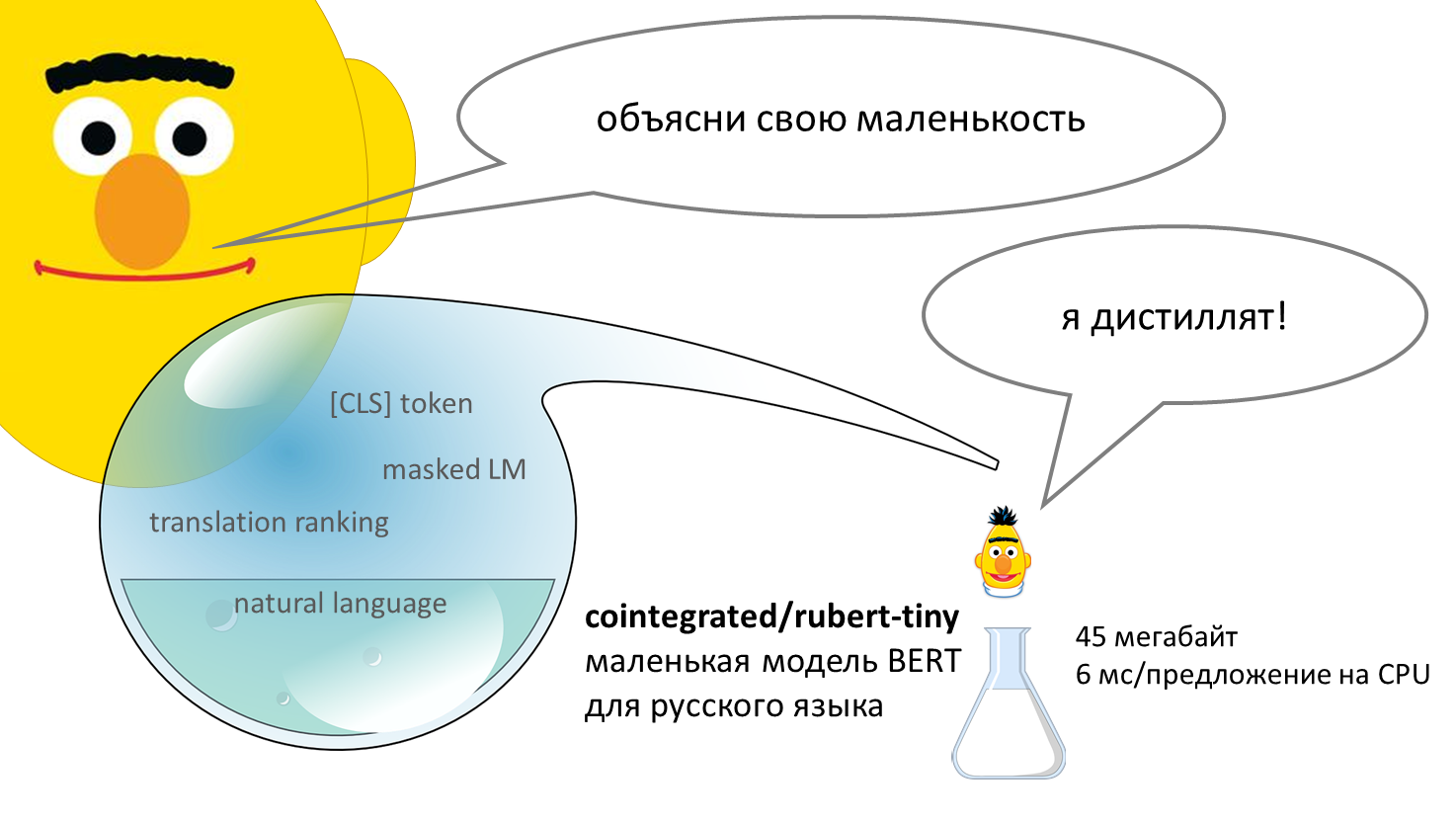
BERT – нейросеть, способная неплохо понимать смысл текстов на человеческом языке. Впервые появившись в 2018 году, эта модель совершила переворот в компьютерной лингвистике. Базовая версия модели долго предобучается, читая миллионы текстов и постепенно осваивая язык, а потом её можно дообучить на собственной прикладной задаче, например, классификации комментариев или выделении в тексте имён, названий и адресов. Стандартная версия BERT довольно толстая: весит больше 600 мегабайт, обрабатывает предложение около 120 миллисекунд (на CPU). В этом посте я предлагаю уменьшенную версию BERT для русского языка – 45 мегабайт, 6 миллисекунд на предложение. Она была получена в результате дистилляции нескольких больших моделей. Уже есть tinybert для английского от Хуавея, есть моя уменьшалка FastText'а, а вот маленький (англо-)русский BERT, кажется, появился впервые. Но насколько он хорош?
Cross-nested ordered probit: мой первый разработческий проект, ML и эконометрика
13 min
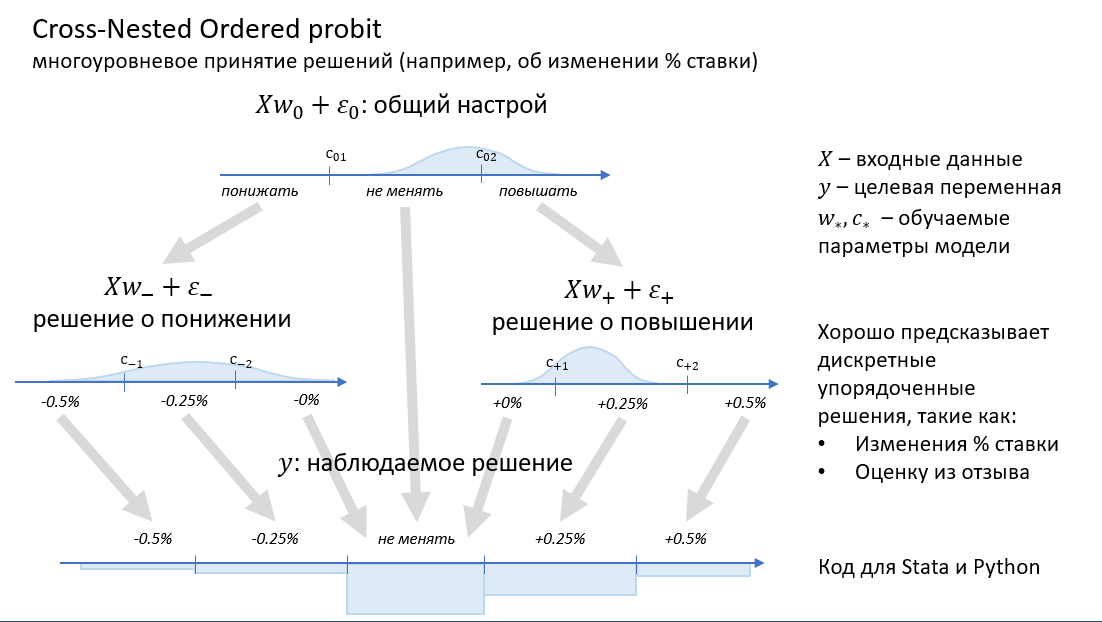
В далёком 2014 я ещё учился на экономиста, но уже очень мечтал уйти в анализ данных. И когда мне предложили выполнить мой первый платный разработческий проект для моего университета, я был счастлив. Проект заключался в написании кода эконометрической модели для пакета Stata. Стату я с тех пор люто возненавидел, но сам проект научил меня многому.
В этом посте я расскажу про Cross-Nested Ordered Probit, забавную модель для предсказания порядковых величин, покажу её код на PyTorch, и порассуждаю о различиях и сходствах машинного обучения и эконометрики.
Культурные рекомендации: опыт московского хакатона
5 min
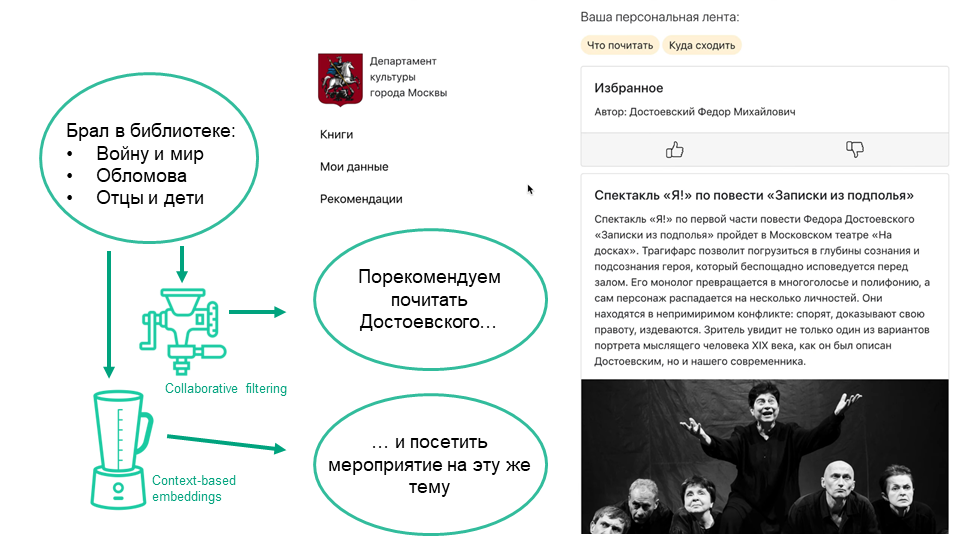
В конце прошлого года я поучаствовал в хакатоне "Лидеры цифровой трансформации" при поддержке Правительства Москвы. Мы решали задачу от Департамента культуры - рекомендательную систему для его услуг, то есть книг в библиотеках, а также кружков и мероприятий в культурных центрах. Особая пикантность в том, что по одним из этих сервисов нужно было рекомендовать другие. Наше решение заняло только второе место, но делать его было познавательно.
Как предсказать гипероним слова (и зачем). Моё участие в соревновании по пополнению таксономии
8 min
Как может машина понимать смысл слов и понятий, и вообще, что значит — понимать? Понимаете ли вы, например, что такое спаржа? Если вы скажете мне, что спаржа — это (1) травянистое растение, (2) съедобный овощ, и (3) сельскохозяйственная культура, то, наверное, я останусь убеждён, что вы действительно знакомы со спаржей. Лингвисты называют такие более общие понятия гиперонимами, и они довольно полезны для ИИ. Например, зная, что я не люблю овощи, робот-официант не стал бы предлагать мне блюда из спаржи. Но чтобы использовать подобные знания, надо сначала откуда-то их добыть.
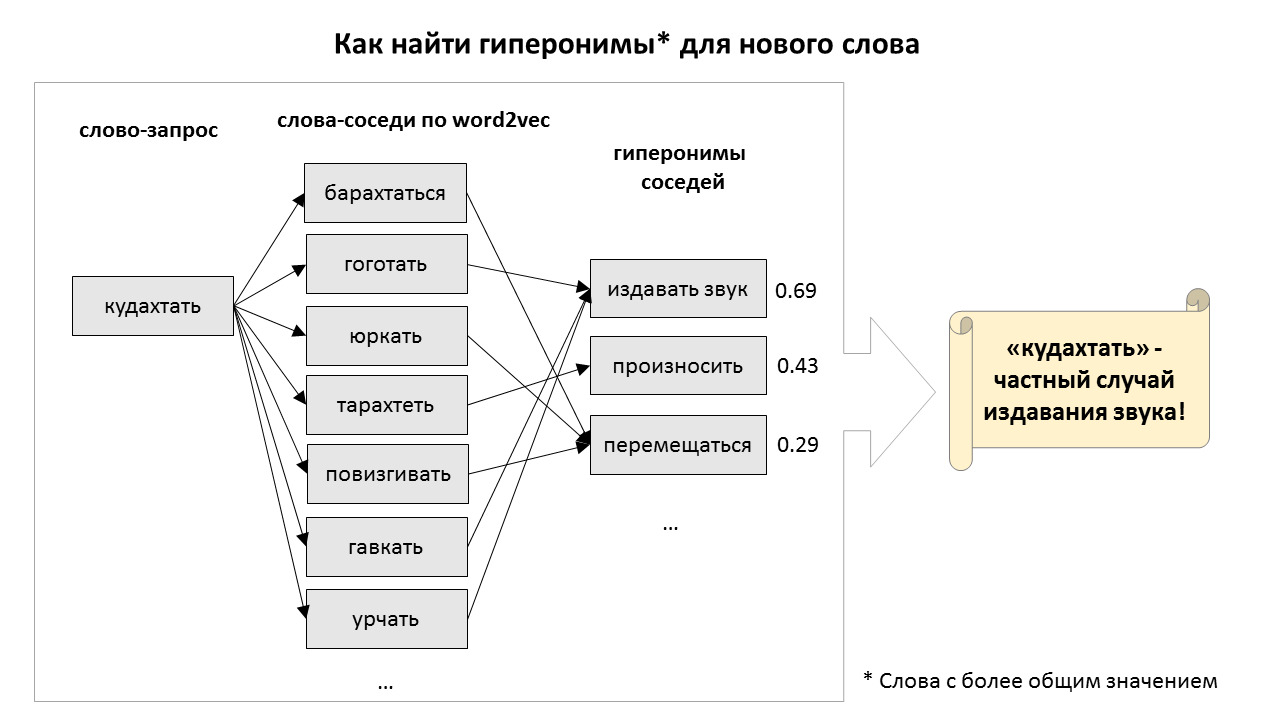
В этом году компьютерные лингвисты организовали соревнование по поиску гиперонимов для новых слов. Я тоже попробовал в нём поучаствовать. Нормально получилось собрать только довольно примитивный алгоритм, основанный на поиске ближайших соседей по эмбеддингам из word2vec. Однако этот простой алгоритм каким-то образом оказался наилучшим решением для поиска гиперонимов для глаголов. Послушать про него можно в записи моего выступления, а если вы предпочитаете читать, то добро пожаловать под кат.
Хакатон в Симферополе, Яндекс.Диалоги и законы чат-бото-техники
6 min
1 февраля в Симферополе прошёл хакатон по разработке навыков для Алисы. Местные фронтенд-разработчики взялись его организовать, а Яндекс предоставил место. Несмотря на то, что участники создавали голосовые интерфейсы впервые, за день было создано больше десятка работающих прототипов, и некоторые из них даже опубликовались.
В этом посте мы приводим примеры навыков, которые можно сделать за несколько часов, и рассказываем какой подход лежит в их основе. Хотим, чтобы было больше навыков полезных и разных. Погнали.

На фотографии пара участников хакатона и затылок Сегаловича
Как сжать модель fastText в 100 раз
12 min
Модель fastText — одно из самых эффективных векторных представлений слов для русского языка. Однако её прикладная польза страдает из-за внушительных (несколько гигабайт) размеров модели. В этой статье мы показываем, как можно уменьшить модель fastText с 2.7 гигабайт до 28 мегабайт, не слишком потеряв в её качестве (3-4%). Спойлер: квантизация и отбор признаков работают хорошо, а матричные разложения — не очень. Также мы публикуем пакет на Python для этого сжатия и примеры компактной модели для русских слов.

Создание stateful навыка для Алисы на serverless функциях Яндекс.Облака и Питоне
7 min
Tutorial
Начнём с новостей. Вчера Яндекс.Облако анонсировало запуск сервиса бессерверных вычислений Yandex Cloud Functions. Это значит: ты пишешь только код своего сервиса (например, веб-приложения или чатбота), а Облако само создаёт и обслуживает виртуальные машины, где он запускается, и даже реплицирует их, если возрастает нагрузка. Думать вообще не надо, очень удобно. И плата идёт только за время вычислений.
Впрочем, кое-кто может вообще не платить. Это — разработчики внешних навыков Алисы, то есть встроенных в неё чатботов. Написать, захостить и зарегистрировать такой навык может любой разработчик, а с сегодняшнего дня навыки даже не надо хостить — достаточно залить их код в облако в виде той самой бессерверной функции.
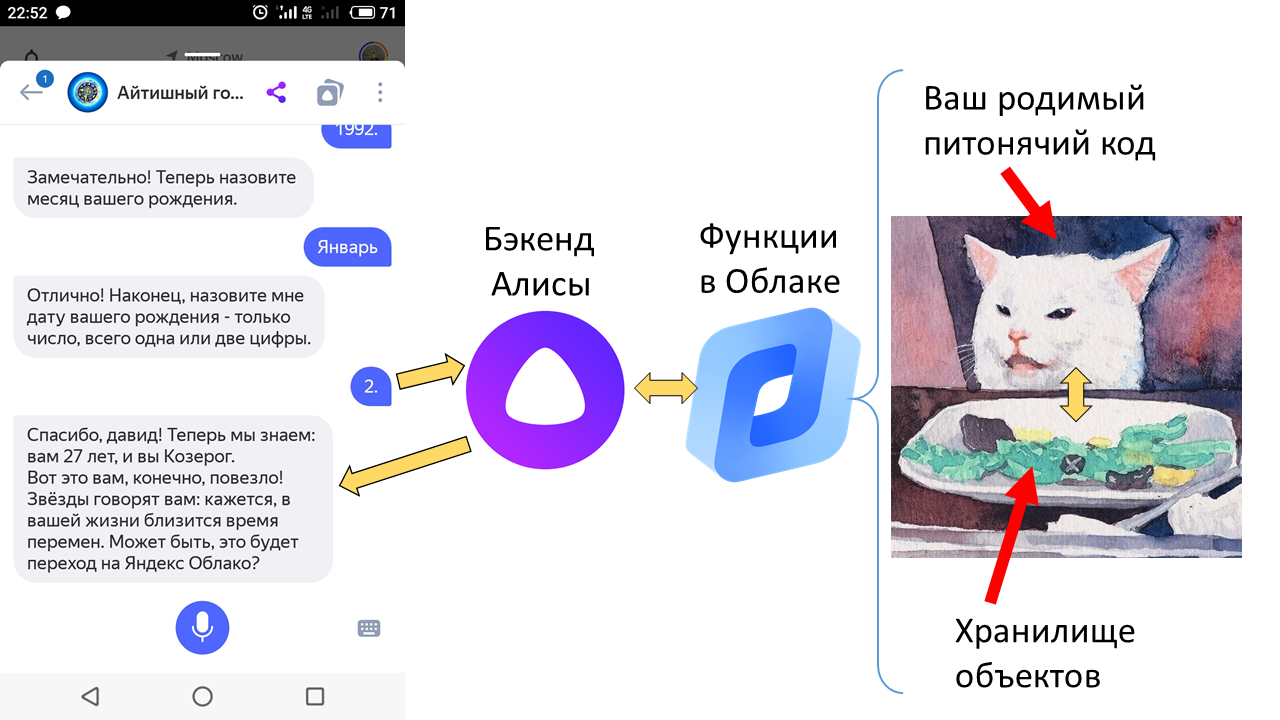
Но есть пара нюансов. Во-первых, ваш питонячий код может требовать каких-то зависимостей, и затаскивать их в Облако — нетривиально. Во-вторых, любому нормальному чатботу нужно хранить где-то состояние диалога (stateful поэтому); как сделать это в бессерверной функции проще всего? В третьих, а как вообще можно быстро-грязно написать навык для Алисы или вообще какого-то бота с ненулевым сюжетом? Об этих нюансах, собственно, статья.
Сэмплирование с температурой
3 min
Недавно натолкнулся на вопрос в чате ODS: почему алгоритм, генерирующий текст буква-за-буквой, сэмплит буквы не из p (вектор вероятностей следующей буквы, предсказанный языковой моделью), а из p'=softmax(log(p)/t) (где t — это ещё какой-то непонятный положительный скаляр)?
Быстрый и непонятный ответ: t — это "температура", и она позволяет управлять разнообразием генерируемых текстов. А ради длинного и детального ответа, собственно, и написан этот пост.

Создание простого разговорного чатбота в python
7 min
Tutorial
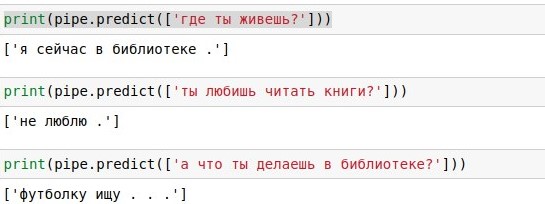
Как вы думаете, сложно ли написать на Python собственного чатбота, способного поддержать беседу? Оказалось, очень легко, если найти хороший набор данных. Причём это можно сделать даже без нейросетей, хотя немного математической магии всё-таки понадобится.
Идти будем маленькими шагами: сначала вспомним, как загружать данные в Python, затем научимся считать слова, постепенно подключим линейную алгебру и теорвер, и под конец сделаем из получившегося болтательного алгоритма бота для Телеграм.
Этот туториал подойдёт тем, кто уже немножко трогал пальцем Python, но не особо знаком с машинным обучением. Я намеренно не пользовался никакими nlp-шными библиотеками, чтобы показать, что нечто работающее можно собрать и на голом sklearn.
Идти будем маленькими шагами: сначала вспомним, как загружать данные в Python, затем научимся считать слова, постепенно подключим линейную алгебру и теорвер, и под конец сделаем из получившегося болтательного алгоритма бота для Телеграм.
Этот туториал подойдёт тем, кто уже немножко трогал пальцем Python, но не особо знаком с машинным обучением. Я намеренно не пользовался никакими nlp-шными библиотеками, чтобы показать, что нечто работающее можно собрать и на голом sklearn.
How linear algebra is applied in machine learning
5 min
When you study an abstract subject like linear algebra, you may wonder: why do you need all these vectors and matrices? How are you going to apply all this inversions, transpositions, eigenvector and eigenvalues for practical purposes?
Well, if you study linear algebra with the purpose of doing machine learning, this is the answer for you.
In brief, you can use linear algebra for machine learning on 3 different levels:
- application of a model to data;
- training the model;
- understanding how it works or why it does not work.

Машинное обучение и экструдер полипропилена: история 3 места на хакатоне Сибура
7 min
Хакатон "Цифровой завод", организованный Сибуром и AI Community, состоялся на прошлых выходных. Одна из двух задач хакатона была на тему predictive maintenance — нужно было предсказывать проблемы в работе экструдера. Её мы и решили. Рассказ сосредоточен в основном на data science'ной части решения, и о том, как нам удалось научиться неплохо прогнозировать довольно редкие события.

Нужно ли бояться несбалансированности классов?
3 min
В сети есть множество постов и ресурсов, которые учат нас бороться с несбалансированностью классов (class imbalance) в задаче классификации. Обычно они предлагают методы сэмплирования: искусственно дублировать наблюдения из редкого класса, или выкинуть часть наблюдений из популярного класса. Этим постом я хочу прояснить, что «проклятие» дисбаланса классов – это миф, важный лишь для отдельных типов задач.
