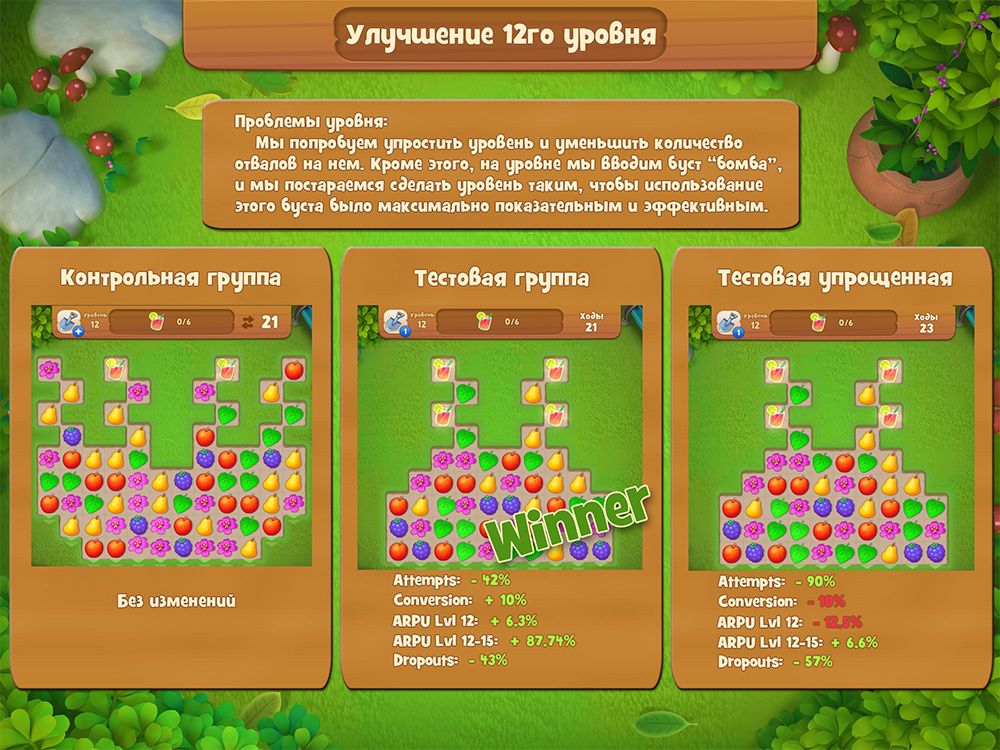
Сеть обучалась последние 12 часов. Всё выглядело хорошо: градиенты стабильные, функция потерь уменьшалась. Но потом пришёл результат: все нули, один фон, ничего не распознано. «Что я сделал не так?», — спросил я у компьютера, который промолчал в ответ.
Почему нейросеть выдаёт мусор (например, среднее всех результатов или у неё реально слабая точность)? С чего начать проверку?
Сеть может не обучаться по ряду причин. По итогу многих отладочных сессий я заметил, что часто делаю одни и те же проверки. Здесь я собрал в удобный список свой опыт вместе с лучшими идеями коллег. Надеюсь, этот список будет полезен и вам.
Почему нейросеть выдаёт мусор (например, среднее всех результатов или у неё реально слабая точность)? С чего начать проверку?
Сеть может не обучаться по ряду причин. По итогу многих отладочных сессий я заметил, что часто делаю одни и те же проверки. Здесь я собрал в удобный список свой опыт вместе с лучшими идеями коллег. Надеюсь, этот список будет полезен и вам.