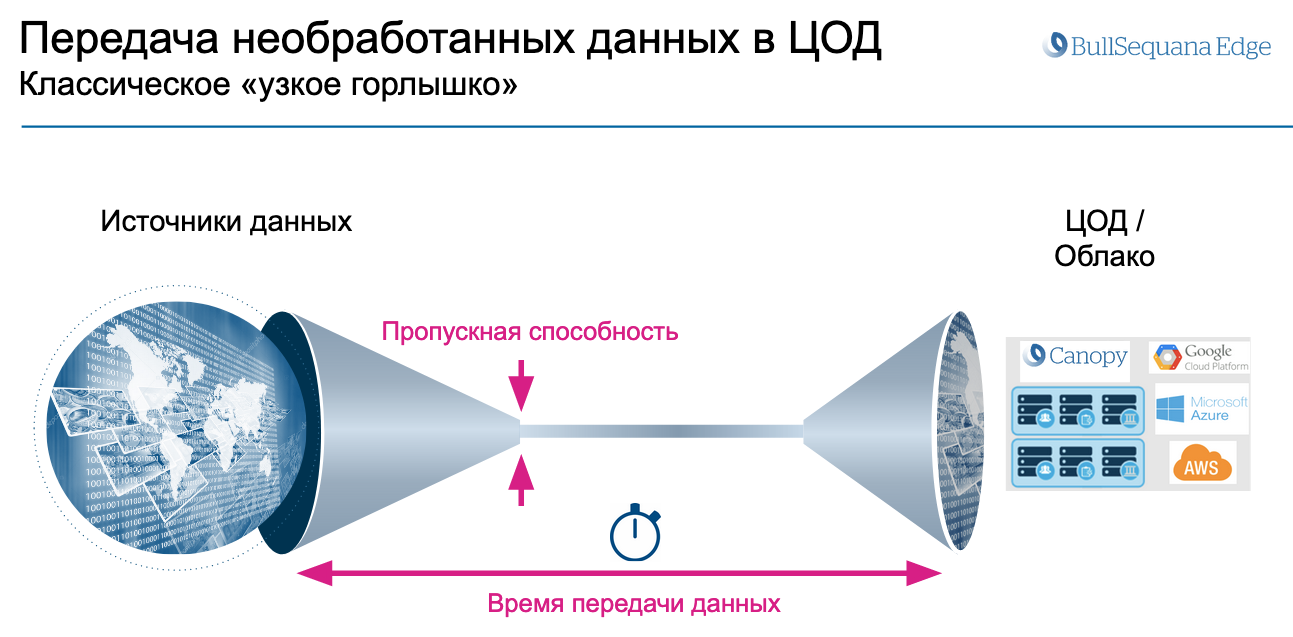
При разработке сетевой инфраструктуры обычно рассматривают либо локальные вычисления, либо облачные. Но этих двух вариантов и их комбинаций мало. Например, что делать, если от облачных вычислений отказаться нельзя, а пропускной способности не хватает или трафик стоит слишком дорого?
Добавить промежуточное звено, которое выполнит часть вычислений на границе локальной сети или производственного процесса. Эта периферийная концепция называется Edge Computing — «граничные вычисления». Концепция дополняет текущую облачную модель использования данных, и в этой статье мы рассмотрим необходимое оборудование и примеры задач для него.
SAP HANA — популярная in-memory СУБД, включающая сервисы хранилищ (Data Warehouse) и аналитики, встроенное промежуточное ПО, сервер приложений, платформу для настройки или разработки новых утилит. За счет устранения задержек традиционных СУБД с SAP HANA можно сильно увеличить производительность систем, обработку транзакции (OLTP) и бизнес-аналитику (OLAP).
Развернуть SAP HANA можно в режимах Appliance и TDI (если говорить о продуктивных средах). Для каждого варианта у производителя есть свои требования. В этом посте мы расскажем о преимуществах и недостатках разных вариантов, а также для наглядности — о наших реальных проектах с SAP HANA.
Если вы занимаетесь выращиванием больших баз данных и вдруг упираетесь в потолок производительности — пришло время расширяться. Со scale-out расширением понятно: серверы добавляете и горя не знаете. Со scale-up все не так весело. Согласно стандартной glueless-архитектуре, мы берем два процессора, потом добавляем к ним еще два… так доходим до восьми и все. Больше Intel не предусмотрел, копите на новый сервер.
Но есть и альтернатива — glued-архитектура. В ней двухпроцессорные вычислительные блоки соединяются между собой через нод-контроллеры. С их помощью верхний порог на один сервер поднимается до 16 и более процессоров. В этом посте подробней расскажем о glued-архитектуре вообще и о том, как она реализована в наших серверах.