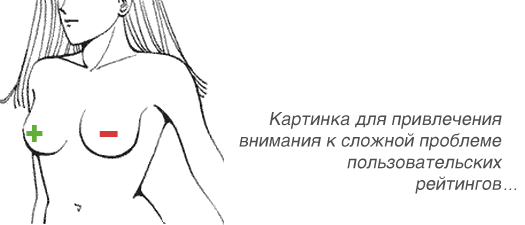
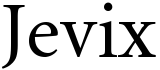Число подписчиков блога. Число опубликованных постов пользователя. Число положительных и отрицательных голосов за комментарий. Число оплаченных заказов товара. Вам приходилось считать что-то подобное? Тогда, готов поспорить, что оно у вас периодически сбивалось. Да ладно, даже у вконтакта сбивалось:
Не знаю как у вас, но в моей жизни счётчики — едва ли не первая проблема после инвалидации кеша и нейминга. Не стану утверждать, что решил её окончательно. Просто хочу поделиться с сообществом подходом, к которому я пришёл в процессе работы над Хабром, Дару~даром, Дёрти, Трипстером и другими проектами. Надеюсь это поможет кому-то сэкономить время и нервные клетки.
В оригинале название звучит как «How Not To Sort By Average Rating». Я подумал, что дословный перевод «Как не сортировать по усреднённому рейтингу» будет малопонятен и хуже отражает содержание статьи.
Постановка проблемы
Вы занимаетесь веб программированием. У вас есть пользователи, которые оценивают контент на вашем сайте. Вы хотите разместить высоко оцененный контент наверху, а низко оцененный — внизу. Для этого на основе пользовательских оценок вам нужно вычислить некий «рейтинг».
Нашим коллективным умом давно завладела хабрастатистика и эти выходные были проведены в прелюбопытнейшем изучении интересов хабрапользователей. Обо всём в одном посте рассказать трудно, но для тех, кому интересно, вот небольшая выжимка:
UPD Добавлена статистика использования социальных сервисов и messenger-ов
Уважаемые Хабражители!
Сегодня особенный день для Хабра — день рождения принципиально новой, интеллектуальной «Хабраленты 3.0».
В чём же её принципиальное новшество?
Вам больше не требуется подписываться на блоги/теги/авторов и так далее. За вас всё сделает НЛО :) Оно пристально следит за вашими действиями (голосованием, добавлением в избранное и т.д.) и составляет список персональных рекомендаций. На самом деле термин «персональные рекомендации» тут не совсем верный. Это скорее «персональный фильтр». Его основная функция не в том, чтобы предложить только самое интересное, а в том, чтобы отсеять то, что вам с большой вероятностью будет неинтересно. Тут можно провести аналогию с почтовым фильтром, скрывающим спам, но не предлагающим «самые интересные письма». С другой стороны, эта аналогия не совсем верна: посты в Хабраленте ранжируются по предполагаемой релевантности.
Теперь алгоритм учитывает «избранное» пользователя (спасибо MKrivosheev за идею)
Немного снизили порог попадания тегов в профиль внимания
P.S. Кто не в теме — пост является продолжением этого. Нововведения о которых идёт речь можно увидеть в профиле пользователя (в том числе в вашем собственном профиле).
В профиле наиболее активных пользователей Хабра появился блок отражающий интерес человека к определённым авторам публикаций. Чем больше ник — тем больше интерес (всё как в стандартном облаке тегов).
Одновременно с этой замечательной штуковиной претерпел изменения блок «Профиль внимания». Помимо укороченного названия (раньше оно было столь длинно, что я его даже не смог запомнить) был усовершенствован алгоритм построения.
Процесс работы над этими двумя блоками оказался очень интересным, и, ниже я бы хотел поделиться с общественностью некоторыми любопытными наблюдениями.
Jevix — система автоматического применения правил набора текстов (типографика) разработанная в ТМ™ для собственных проектов (Хабр, Кадабра, Дрибблер), с открытым исходным кодом, наделённая способностью унифицировать разметку HTML/XML документов, контролировать перечень допустимых тегов и атрибутов и предотвращать возможные XSS-атаки в коде документов.
В связи с катастрофической нехваткой времени, не смотря на мои обещания, код версии 1.0 выложен только сегодня. Но зато он всё же вышел! Причём вместе с исправлением вчерашнего хабрабага с перечёркиванием текста.
Теперь Jevix доступен на google code. Я не поссорился с Juks — автором perl-версии (если кто что подумал) — просто с google code мне работать проще.
Недавно мне позвонила мама (она учитель в обычной среднеобразовательной гос. школе) и с плачем начала объяснять что опять не может заполнить отчёт о контрольной по алгебре для 8-х классов. То, что я увидел на её компьютере, по приезду, настолько повергло меня в шок, что я не удержался от написания злобного поста про наше образование.
Сегодня обновился наш парсер Jevix.
Пока его нельзя скачать с официального сайта но, скоро, честное слово он появится там.
Полный список изменений можно будет найти в коде, а вкратце:
На Хабрахабре и других проектах ТМ внедрена долгожданная технология объединения тегов.
Один «тег-оригинал» теперь может иметь несколько «синонимов».
Например: Веб 2.0 и Web 2.0, Yandex и Яндекс или Хабр, Habrahabr и Хабрахабр.
Появилась возможность вставки кода. Чтобы всё получилось, код необходимо вставлять в тег
<code>
ваш код должен быть тут
</code>
Иначе, теги съест парсер
Пример:
// Добавляем возможность подсветки синтаксиса с помощью <font color> в теге code
$jevix->cfgAllowTags(array('font'));
$jevix->cfgSetTagChilds('code', array('font'), false, true);
$jevix->cfgAllowTagParams('font', array('color'));
* This source code was highlighted with Source Code Highlighter.
Этот пост меня сподвигли написать две вещи. Автокадабра и некто под ником napisal, кто активно не соглашался с моим постом…
Дело было так: я зашёл в карту клубов Автокадабры и понял что она мне ни о чём не говорит. Создавалось впечатление, что пишут всего в трёх клубах. После изучения облака я пришёл к выводу что линейная зависимость размера тега (в данном случае блога) от количества публикаций совершенно не информативна. Клубы с одной публикацией выглядят так же как и с 15-ю.
Некоторое время назад мой любимый Last.fm открыл для всеобщего доступа свой API. Означает это, что теперь кто угодно (даже Вы) может пользоваться базой данных самого популярного в мире музыкального сервиса.
Jevix — средство применения правил набора текстов (типографики), фильтрации тегов и аттрибутов, предотвращения XSS-атак. Jevix предназначен для использования в составе интернет-проектов, публикующих пользовательские материалы, будь то крупная социальная сеть или авторский блог.
Jevix способен полностью взять на себя все возможные проблемы с обработкой пользовательского материала в формате простого текста или HTML.