
В статье рассказываем о том, кому стоит задуматься о внедрении DWH, как сократить вероятность ошибок на этапе разработки проекта, выбрать стек, методологию и сэкономить ИТ-бюджеты.

Пользователь
В статье рассказываем о том, кому стоит задуматься о внедрении DWH, как сократить вероятность ошибок на этапе разработки проекта, выбрать стек, методологию и сэкономить ИТ-бюджеты.
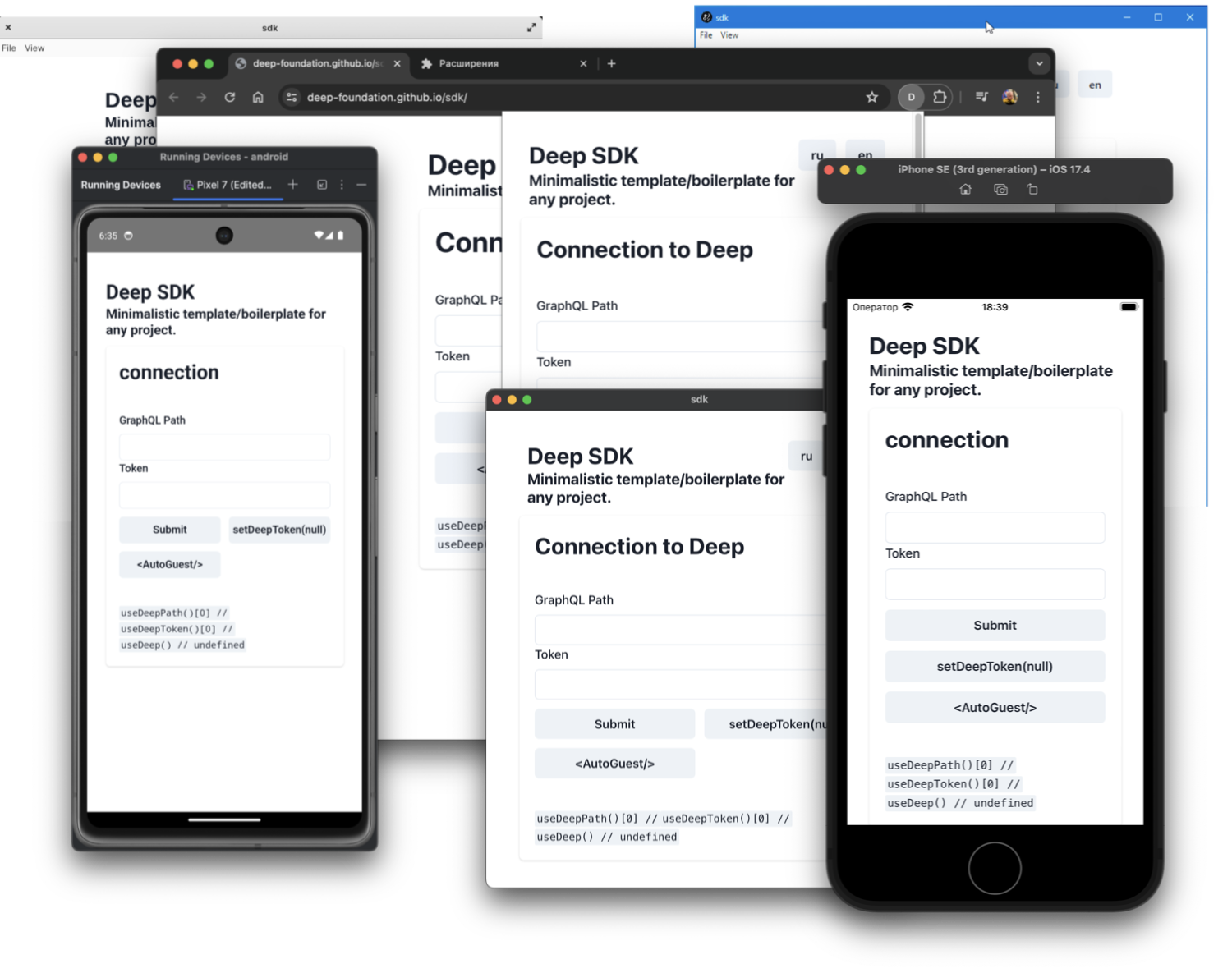
Собираем кроссплатформенное (server-client, static-client, gh-pages, Android, iOS, macOS, Linux, Windows, Chrome extension, Docker, Kubernetes, ...) React приложение. В этой статье я почти не затрону Deep backend, только чуть-чуть в конце. Но рассмотрю Open Source шаблон/заготовку для сборки кроссплатформенных React приложений который мы используем в Deep.Foundation.

Примеры кода на Python для работы с Apache Spark для «самых маленьких» (и немного «картинок»).
Данная статья представляет собой обзор основных функций Apache Spark и рассматривает способы их применения в реальных задачах обработки данных. Apache Spark — это мощная и гибкая система для обработки больших объёмов данных, предлагающая широкий спектр возможностей для аналитики и машинного обучения. В нашем обзоре мы сфокусируемся на ключевых функциях чтения, обработки и сохранения данных, демонстрируя примеры кода, которые помогут новичкам быстро включиться в работу и начать использовать эти возможности в своих проектах.

Привет! Мы – Екатерина и Виктория, middle-разработчик и старший разработчик в БФТ-Холдинге. В статье кратко расскажем об основах DGS фреймворка, его преимуществах, проблемах, с которыми мы столкнулись при работе с ним, а также покажем создание простого сервиса с поддержкой WebFlux.
Привет, Хабр.
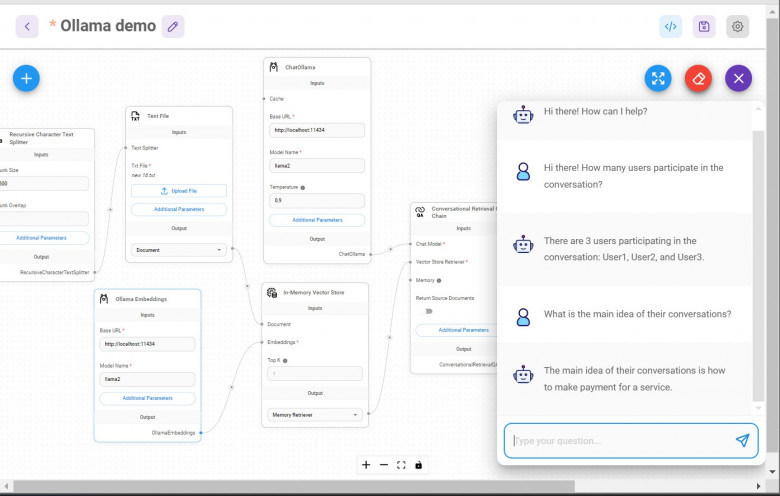
В этой статье о том, как без написания кода поставить себе локально и использовать LLM без подключения к сети. Для меня это удобный способ использования в самолёте или in the middle of nowhere. Заранее выгрузив себе нужные файлы, можно делать анализ бесед саппорта с клиентами, или получить саммарайз отзывов из стора на приложение, или оценить резюме/тестовое задание кандидата...


Это четвертая часть серии мега-учебника по Flask, в которой я собираюсь рассказать вам, как работать с базами данных. Тема этой главы чрезвычайно важна. Для большинства приложений потребуется поддерживать постоянные данные, которые можно эффективно извлекать, и это именно то, для чего созданы базы данных.

Понимаем полностью useMemo и useCallback
Экскурсия по двум самым известным хукам в React
Если вы изо всех сил пытались разобраться в useMemo и useCallback, вы не одиноки! Я разговаривал со многими разработчиками React, которые cломали голову над этими двумя хуками.
Моя цель в этом здесь — прояснить всю эту путаницу. Мы узнаем, что они делают, почему они полезны и как получить от них максимальную пользу.
Погнали!

Привет, Хабр!
В Kubernetes принято разделение хранилищ на два основных типа: постоянные и временные.
Постоянные хранилища (PV) представляют собой сегменты дискового пространства, которые могут быть подключены к подам и сохранять данные даже после перезапуска или удаления контейнеров. Эти объемы предоставляются через механизм Persistent Volume Claims, который позволяет юзерам и приложениям запрашивать хранилище определенного размера и класса, абстрагируясь от физической реализации хранилища.
А вот временные хранилища связаны с жизненным циклом контейнера и используются для хранения данных, актуальных только во время работы контейнера.
Классификация хранилищ в Kubernetes не ограничивается только этим разделением. Существуют различные StorageClasses, которые позволяют определять классы хранилищ с разными характеристиками.
Также в Kubernetes реализован контейнерный интерфейс хранения.
Основы всего из этого рассмотрим в этой статье.

Привет, Хабр!
При работе с PostgreSQL (да и в целом с любой БД) важно правильно настраивать и управлять ресурсами, такими как память, процессорное время и дисковые операции, и так далее для обеспечения лучшей производительности и стабильности работы БД.
В этой статье мы как раз и рассмотрим кратко о том, как управлять ресурсами в PostgreSQL.

Не секрет, что я ❤️ React Query за то, как он упрощает взаимодействие с асинхронным состоянием в приложениях React. И я знаю, что многие коллеги-разработчики согласятся с этим.
Однако иногда я встречаю сообщения, в которых утверждается, что он вам не нужен для чего-то столь «простого», как получение данных с сервера.
BPMN — это язык визуального моделирования бизнес-процессов, использующий графические блок-схемы. Это открытый стандарт, созданный консорциумом Object Management Group (OMG).
Процессный движок Flowable позволяет разворачивать процессы в соответствии с международным отраслевым стандартом BPMN 2.0. Каждый процесс BPM представляет собой последовательность объектов, связанных с действиями и имеющих стартовое и конечное события.
BPMN используется для автоматизации бизнеса — например, в управлении пользовательским/клиентским опытом или управлении мероприятиями. Он упрощает и ускоряет разработку, уменьшая количество ошибок.
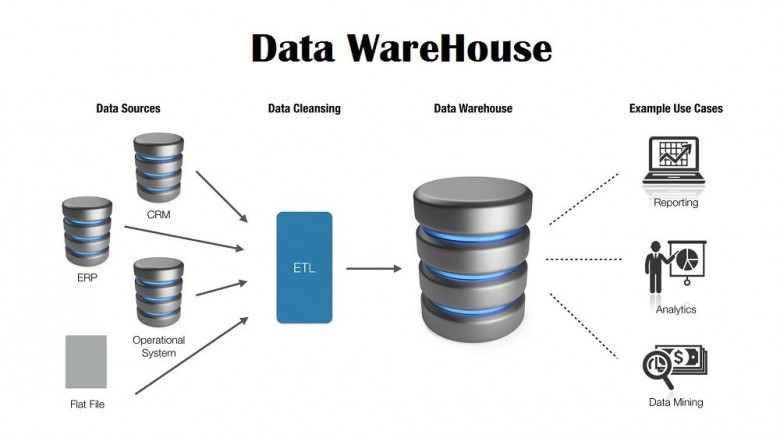
Хранилище данных — это информационная система, в которой хранятся исторические и коммутативные данные из одного или нескольких источников. Он предназначен для анализа, составления отчетов и интеграции данных транзакций из разных источников.
Рассмотрим сильные и слабые стороны самых популярных методологий.

Допустим, Вы разрабатываете несколько приложений или микросервисов на Java. Каждое из них уникальное, и содержит свою собственную бизнес логику. Однако, в каждом из них может быть необходимость использовать общую логику. Например, логику аутентификации, как это часто бывает в мире микросервисов.
Spring Boot starter'ы - отличный способ управлять созданием, развитием и поставкой общей кодовой базы. О том как создать свой Spring Boot 3 стартер и поговорим в этой статье.
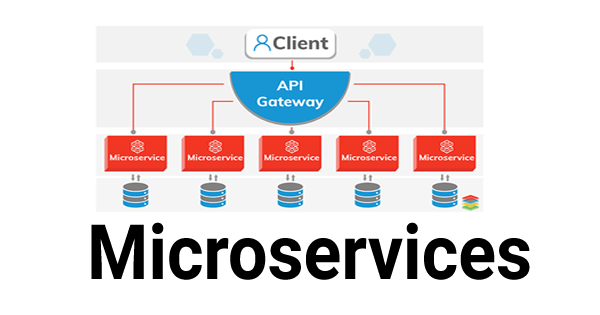
Микросервис — это подход к разбиению большого монолитного приложения на отдельные приложения, специализирующиеся на конкретной услуге/функции. Этот подход часто называют сервис-ориентированной архитектурой или SOA.
В монолитной архитектуре каждая бизнес-логика находится в одном приложении. Службы приложений, такие как управление пользователями, аутентификация и другие функции, используют одну и ту же базу данных.
В микросервисной архитектуре приложение разбивается на несколько отдельных служб, которые выполняются в отдельных процессах. Существует другая база данных для разных функций приложения, и службы взаимодействуют друг с другом с использованием HTTP, AMQP или двоичного протокола, такого как TCP, в зависимости от характера каждой службы. Межсервисное взаимодействие также может осуществляться с использованием очередей сообщений, таких как RabbitMQ , Kafka или Redis .
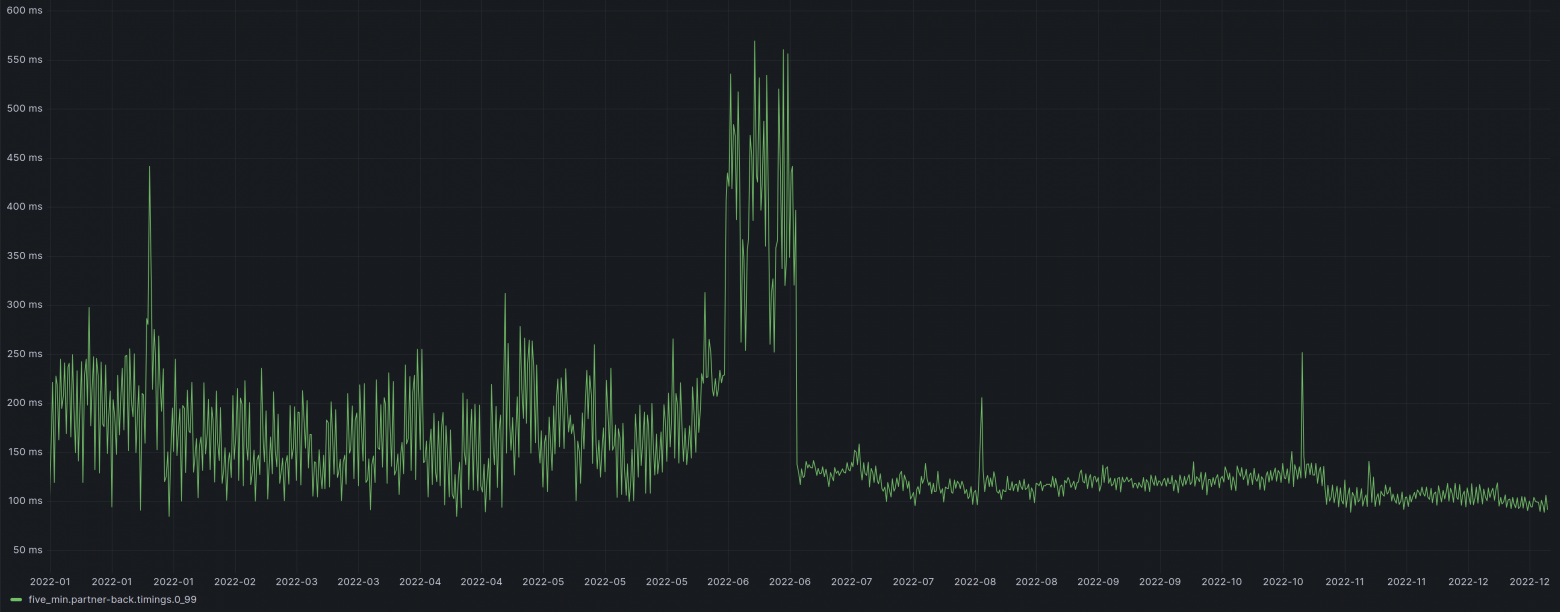
Всем привет! Я Сергей, работаю в B2B-команде Яндекс Маркета последние 3,5 года. Как уже понятно из заголовка, сейчас я вам расскажу про yet-another-миграцию с базы на базу, которая началась в середине 2021 года и заняла почти год. Получается, мемуары.
Вас ждёт рассказ о том, как мы:
- несколько месяцев чинили тесты и делали трансформер;
- десятки раз переливали данные;
- чинили баги незаметно для пользователей;
- заставили сервис работать на PostgreSQL быстрее, чем он работал на Oracle.
В этой статье я расскажу о том что такое docker compose, как его написать и разобраться во всех возможных конфигурациях этого файла!
В этой статье я расскажу об инструкциях Docker, о том как написать Dockerfile и о существующих best practice для этого!

Я Александр Таношкин, ведущий инженер-программист сервиса Циан.Ипотека. В статье я поделюсь некоторыми экземплярами коллекции «ловушек» интеграционного тестирования — падений тестов, расследование которых может быть увлекательно, но крайне затратно. А также предложу практические рекомендации, как их избежать, чтобы сосредоточиться на главной задаче — обеспечении качества.

Метод опорных векторов (Support Vector Machines или просто SVM) — мощный и универсальный набор алгоритмов для работы с данными любой формы, применяемый не только для задач классификации и регрессии, но и также для выявления аномалий. В данной статье будут рассмотрены основные подходы к созданию SVM, принцип работы, а также реализации с нуля его наиболее популярных разновидностей.