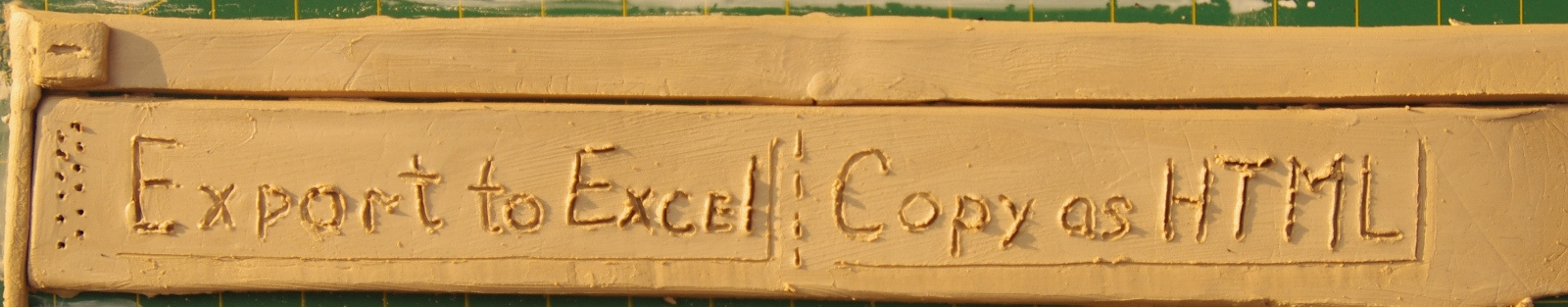Мне нужен был инструмент. Острый, практичный, универсальный. Отвечающий всем моим требованиям и расширяемый по моему желанию.

Но простой и удобный. Тут надо отметить, что на основной работе я не разработчик, поэтому постоянной среды программирования на рабочем компе не имею и, когда это требуется, пишу на чем придется — bat, JScript, VBA в MSOffice (да, это Windows, корпоративные системы, тут нет bash и perl «из коробки»), макросы в разном ПО и т.д. Все это помогает решить текущую задачу, но уровень и возможности маленько не те, что хотелось бы иметь.
Короче, мне нужна интегрированная среда со встроенным языком программирования, в которой я мог разбирать и конвертировать файлы, лазить в базы данных, получать отчеты, вызывать веб-сервисы, плодить запросы в джире и т.д., и т.п.
Вы скажете, что сейчас есть инструменты на любой вкус и цвет, только выбирай. Лягушка aka TOAD под Oracle, SoapUI для шины и продукты GNU и Apache для всего остального.
Но проблема в том, что все они они специализированы под одну какую-то деятельность, а с другой стороны слишком универсальны — можно сделать многое, но многими действиями. А если возможность в продукте отсутствует, то добавить ее нельзя. Либо продукт закрытый, либо нужно разрабатывать/покупать плагин, либо качать исходники и в них разбираться. А мне нужен был инструмент, в котором простые действия делаются просто, а на сложные сначала тратится немного времени и дальше опять все просто.



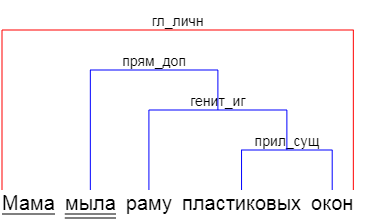



 Самая простая сеть нашлась в статье "
Самая простая сеть нашлась в статье "