Как-то выдалась у меня пара выходных, и я набросал GraphQL сервер к нашей Docsvision платформе. Ниже расскажу, как все прошло.


Пользователь
Как-то выдалась у меня пара выходных, и я набросал GraphQL сервер к нашей Docsvision платформе. Ниже расскажу, как все прошло.


Изображение: Julien Dumont, Flickr
К сожалению, иногда случаются ситуации, когда система перестает работать или начинает безудержно потреблять ресурсы, а логи и системные метрики не могут помочь. Ситуация еще усугубляется тем, что на системе в продакшене нет Visual Studio или какого-либо отладчика, невозможно поотлаживаться удаленно. Чаще всего даже нет возможности получить доступ этой машине. В данном случае единственным решением является анализ дампа памяти процесса. Я хочу описать несколько общих сценариев поиска проблем на таких дампах. Это поиск взаимоблокировок, утечек памяти и высокого потребления процессорных ресурсов.
Уже продолжительное время я размышляю над паттерном RxPM и даже успешно применяю его в «продакшене». Я планировал сначала выступить с этой темой на Mobius, но программный комитет отказал, поэтому публикую статью сейчас, чтобы поделиться с Android-сообществом своим видением нового паттерна.
Все знакомы с MVP и MVVM, но мало кто знает, что MVVM является логическим развитием паттерна Presentation Model. Ведь единственное отличие MVVM от PM – это автоматическое связывание данных (databinding).
В этой статье речь пойдет о паттерне Presentation Model с реактивной реализацией биндинга. Некоторые ошибочно называют его RxMVVM, но корректно будет называть его RxPM, потому что это модификация шаблона Presentation Model.
Этот паттерн удобно использовать в проектах с Rx, так как он позволяет сделать приложение по-настоящему реактивным. Кроме того, он не имеет многих проблем других паттернов. На диаграмме ниже представлены различные варианты и классификации шаблонов представления:
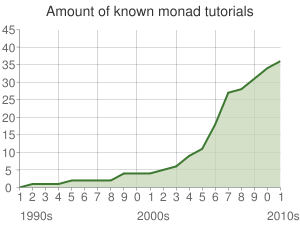
За последнее время мы очень многое узнали о монадах. Мы уже разобрались что это такое и даже знаем как их можно нарисовать, видели доклады, объясняющие их предназначение. Вот и я решил заскочить в уходящий монадный поезд и написать по этой теме, пока это окончательно не стало мейнстримом. Но я зайду с немного другой стороны: здесь не будет выкладок из теории категорий, не будет вставок на самом-лучшем-языке, и даже не будет scalaz/shapeless и библиотеки parser-combinators. Как известно, лучший способ разобраться как что-то устроено — сделать это самому. Сегодня мы с вами будем писать свою монаду.
Возьмем для примера банальную задачу: парсинг CSV-файла. Допустим нам требуется распарсить строки файла в case classes, чтобы потом отправить их в базу, сериализовать в json/protobuf и так далее. Забудем про escaping и кавычки, для еще большей простоты, считаем что символ разделителя в полях встречаться не может. Думаю, если кто-то решит затащить это решение в свой проект, докрутить эту фичу будет не трудно.


Определение Докера в Википедии звучит так:
программное обеспечение для автоматизации развёртывания и управления приложениями в среде виртуализации на уровне операционной системы; позволяет «упаковать» приложение со всем его окружением и зависимостями в контейнер, а также предоставляет среду по управлению контейнерами.
Ого! Как много информации.

Снова Чарли Чаплин на фабрике в фильме «Новые времена»
Продолжаем разговор про Azure Service Fabric. В предыдущей статье я упомянул о планах написать сначала про stateful сервисы, а затем уже перейти к модели акторов в ASF. Концепция изменилась — подумалось мне, что неплохо бы для примеров использовать если уж не production-решение, то что-то близкое, чтобы была теоретическая польза и практический смысл. Можно объединить все компоненты ASF в одном флаконе — чтобы и корованы набигали, и лунапарк, и Винни-Пух и все-все-все. Вот с такими мыслями я и пошел на кладбище домашних проектов в поисках кандидата на оживление.


Предлагаю вашему вниманию перевод статьи What are Docker none:none images? из блога Project Atomic.
Последние несколько дней я потратил на упражнения с образами Docker <none>:<none>. Чтобы объяснить, что они собой представляют, и что могут натворить, я пишу этот пост, в котором ставлю вопросы:
<none>:<none> ?<none>:<none>, когда делаю docker images -a ?docker images и docker images -a ?Прежде чем я начну отвечать на вопросы, запомните, что есть два вида образов <none>:<none>: хорошие и плохие.
 Все будет быстро. Это выступление Анатолия Левенчука, в последнее время не дает мне покоя. Успехи глубинного обучения в последний год говорят о том, что все очень быстро изменится. Слишком долго
Все будет быстро. Это выступление Анатолия Левенчука, в последнее время не дает мне покоя. Успехи глубинного обучения в последний год говорят о том, что все очень быстро изменится. Слишком долго 
«Очень нравится сайт, потому что он не боится нарушать одно из первых правил шрифта – не использовать слишком много разных гарнитур. Используется четыре шрифта, два из семейства sans-serif и два из serif — Galaxie Copernicus, Interstate, Harriet и Nimbus Sans. Основной момент такого дизайна – последовательность, и сайт Бетани Хек последовательно использует каждый из шрифтов для своей цели.»
— Джеремия Шоаф, Typewolf


Продолжаю рассказывать про жизнь Inception architecture — архитеткуры Гугла для convnets.
(первая часть — вот тут)
Итак, проходит год, мужики публикуют успехи развития со времени GoogLeNet.
Вот страшная картинка как выглядит финальная сеть:
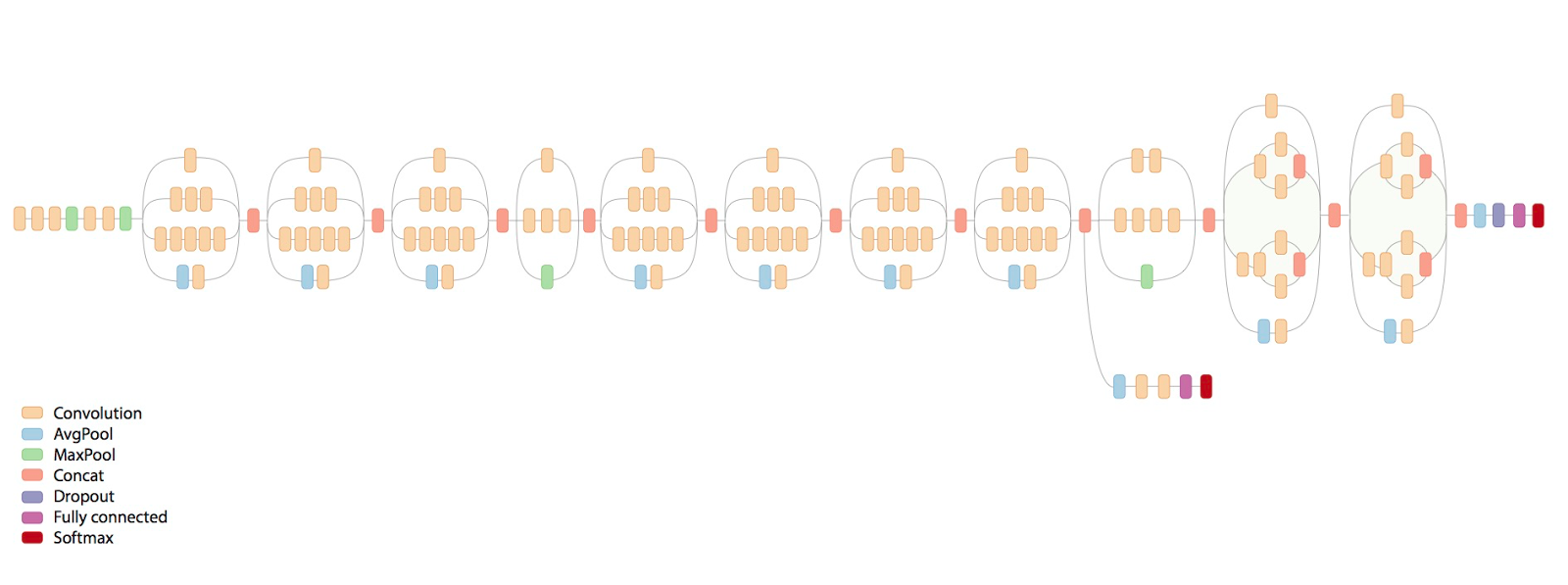
Что же за ужас там происходит?
