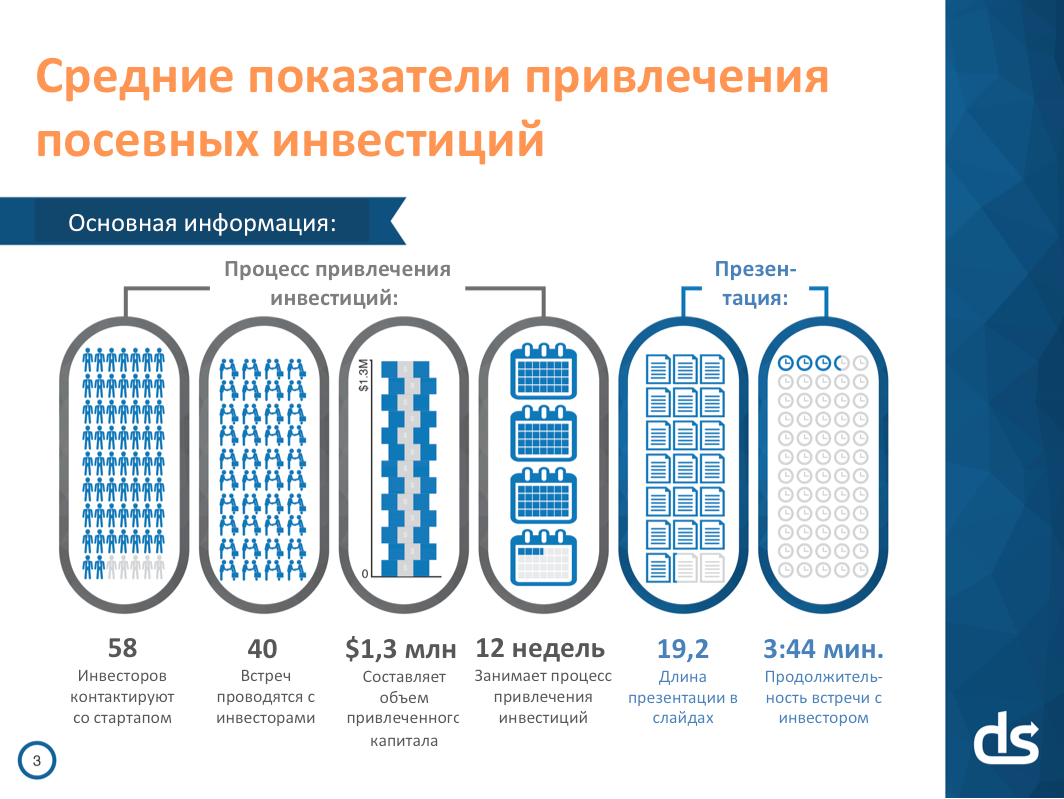
Случается, что вы выводите стартап на рынок, которого еще нет. Люди пока не знают о проблеме, которую вы решаете или не считают её серьезной. Рекламировать продукт в такой обстановке — зря тратить время. Маловероятно, что все вдруг осознают важность проблемы, с которой ваш стартап справляется, наверняка, лучше всех и побегут к вам покупать решение.
Процесс будет постепенным. Со временем образуется понятный рынок, появятся основные игроки, устоятся цены. Но нельзя ждать, пока все сложится само собой. Ведь если даже имея лучшее на сегодня решение сидеть неподвижно — чуда не случится и вы останетесь у обочины нового рынка.
Наступает время занимать стратегическую позицию на будущем рынке. Задача, которую вам придется для этого решить крайне сложна, но предельно понятна. Нужно донести до людей осознание серьезности проблемы, с которой работает ваш стартап. Для этого есть всего два пути: либо потратить миллионы на работу со СМИ, либо попробовать найти поддержку ваших идей в лице известной и авторитетной компании. Давайте смотреть правде в глаза. Маловероятно, что вы сможете привлечь сотни миллионов инвестиций в ваш стартап для глобальной PR-кампании и создания нового рынка. Остается только надежда на партнера, который сможет донести серьезность и значимость решаемой вами проблемы до людей.
Я расскажу, что вы сами можете сделать уже сейчас, чтобы занять выгодную стратегическую позицию на будущем рынке. И покажу это на примере того, как у нас, еще молодого стартапа, получилось создать совместный с Mail.Ru Group
сервис по проверке сайтов на вирусы, который сейчас работает с более чем 1 миллионом сайтов. Итак, пора действовать.