Внимание! Реклама! Пост оплачен Капитаном Очевидность!
Ниже под катом вы найдёте 15 пунктов, описывающих правильную организацию ресурсов, доступных по протоколу HTTP — веб-сайтов, «ручек» бэкенда, API и прочая. «Правильный» здесь означает «соответствующий рекомендациям и спецификациям». Большая часть ниженаписанного почти дословно переведена из официальных стандартов, рекомендаций и best practices от IETF и W3C.

Вы не найдёте здесь абсолютно ничего неочевидного. Нет, серьёзно, каждый веб-разработчик теоретически эти 15 пунктов должен освоить где-то в районе junior developer-а и/или второго-третьего курса университета.
Однако на практике оказывается, что великое множество веб-разработчиков эти азы таки не усвоило. Читаешь документацию к иным API и рыдаешь. Уверен, что каждый читатель таки найдёт в этом списке что-то новое для себя.
Ниже под катом вы найдёте 15 пунктов, описывающих правильную организацию ресурсов, доступных по протоколу HTTP — веб-сайтов, «ручек» бэкенда, API и прочая. «Правильный» здесь означает «соответствующий рекомендациям и спецификациям». Большая часть ниженаписанного почти дословно переведена из официальных стандартов, рекомендаций и best practices от IETF и W3C.
Вы не найдёте здесь абсолютно ничего неочевидного. Нет, серьёзно, каждый веб-разработчик теоретически эти 15 пунктов должен освоить где-то в районе junior developer-а и/или второго-третьего курса университета.
Однако на практике оказывается, что великое множество веб-разработчиков эти азы таки не усвоило. Читаешь документацию к иным API и рыдаешь. Уверен, что каждый читатель таки найдёт в этом списке что-то новое для себя.

 Недавно мы в Voximplant улучшали авторизацию в SDK. Посмотрев на результаты, я несколько опечалился, что вместо простого и понятного токена их стало две штуки: access token и refresh token. Которые мало того что надо регулярно обновлять, так еще документировать и объяснять в
Недавно мы в Voximplant улучшали авторизацию в SDK. Посмотрев на результаты, я несколько опечалился, что вместо простого и понятного токена их стало две штуки: access token и refresh token. Которые мало того что надо регулярно обновлять, так еще документировать и объяснять в 


 (с) xkcd
(с) xkcd

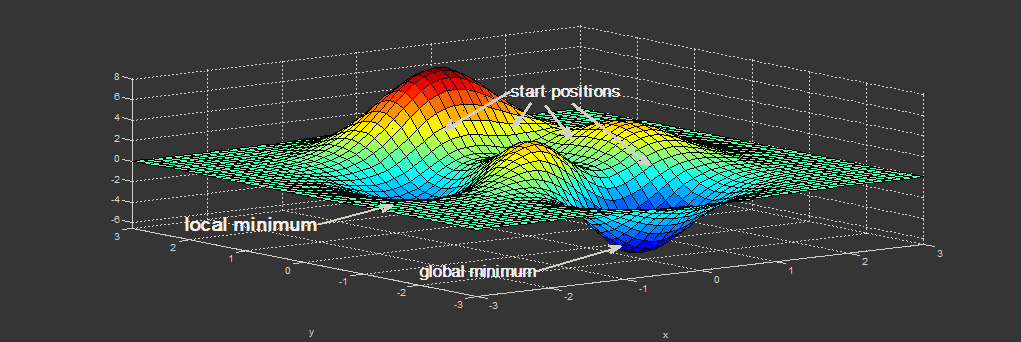
 Spark – проект Apache, предназначенный для кластерных вычислений, представляет собой быструю и универсальную среду для обработки данных, в том числе и для машинного обучения. Spark также имеет API и для R(пакет SparkR), который входит в сам дистрибутив Spark. Но, помимо работы с данным API, имеется еще два альтернативных способа работы со Spark в R. Итого, мы имеем три различных способа взаимодействия с кластером Spark. В данном посте приводиться обзор основных возможностей каждого из способов, а также, используя один из вариантов, построим простейшую модель машинного обучения на небольшом объеме текстовых файлов (3,5 ГБ, 14 млн. строк) на кластере Spark развернутого в Azure HDInsight.
Spark – проект Apache, предназначенный для кластерных вычислений, представляет собой быструю и универсальную среду для обработки данных, в том числе и для машинного обучения. Spark также имеет API и для R(пакет SparkR), который входит в сам дистрибутив Spark. Но, помимо работы с данным API, имеется еще два альтернативных способа работы со Spark в R. Итого, мы имеем три различных способа взаимодействия с кластером Spark. В данном посте приводиться обзор основных возможностей каждого из способов, а также, используя один из вариантов, построим простейшую модель машинного обучения на небольшом объеме текстовых файлов (3,5 ГБ, 14 млн. строк) на кластере Spark развернутого в Azure HDInsight.