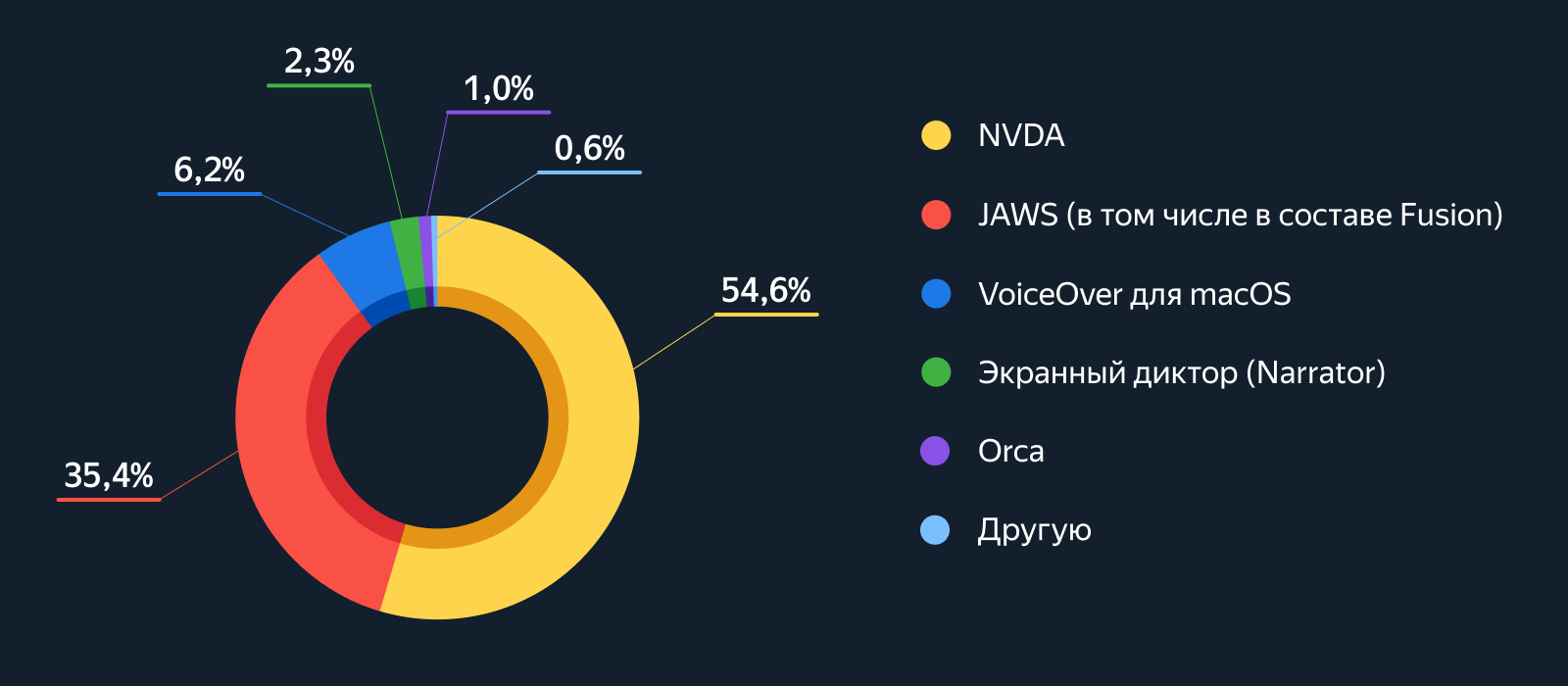
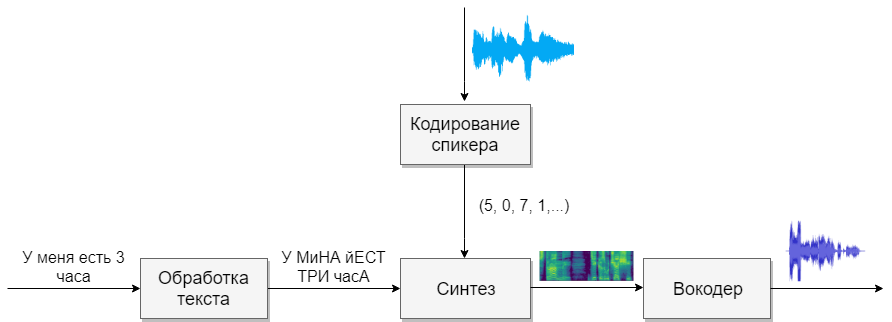
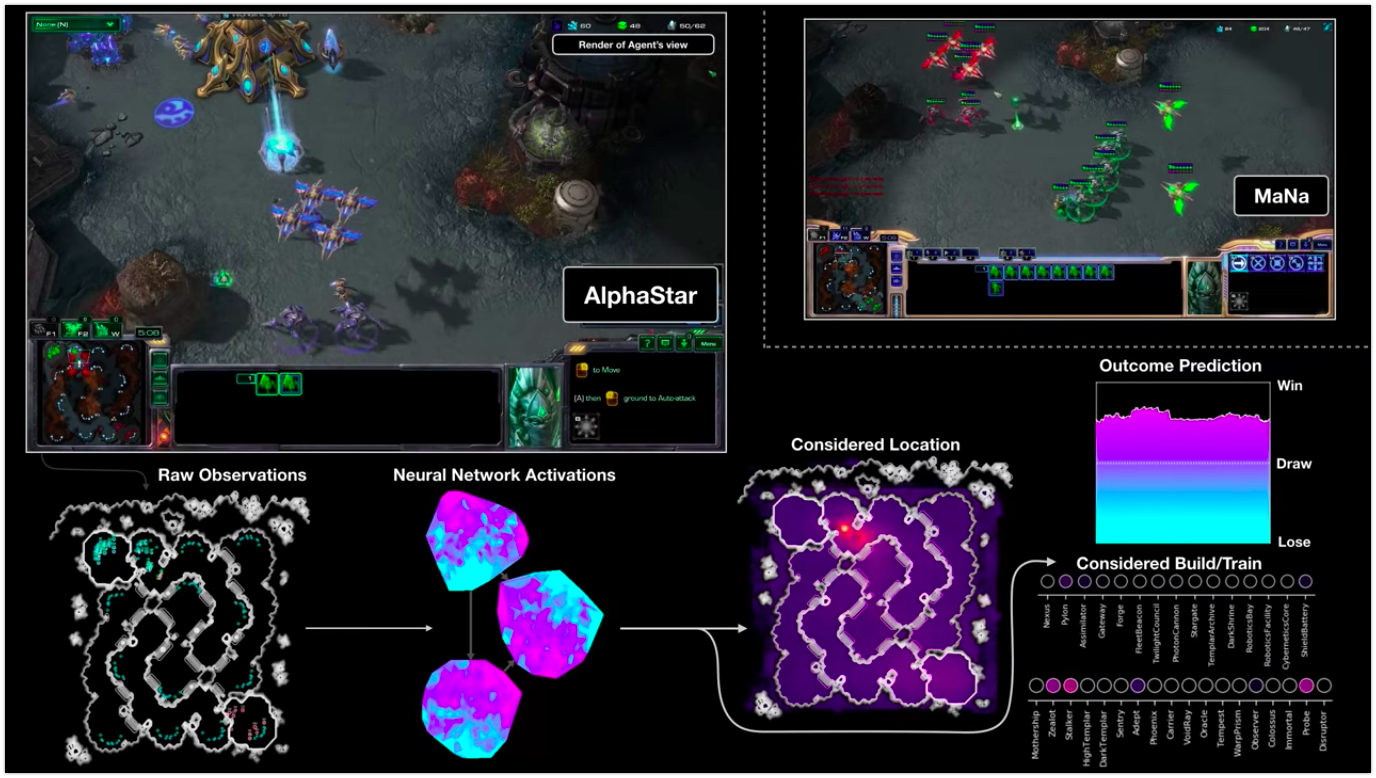
Нейросетевые модели уже несколько лет успешно применяются в Альфа-Банке для решения ключевых задач, таких как кредитный скоринг, прогнозирование склонности клиентов к продуктам и определение оттока. Модели глубокого обучения демонстрируют высокое качество и стабильно улучшают метрики при добавлении к традиционным бустинговым моделям, что приносит Банку сотни миллионов рублей ежегодно.
Однако со временем процесс переобучения моделей под новые целевые переменные становится рутиной: используемые архитектуры почти не меняются, данные собираются по стандартным алгоритмам, по стандартным же алгоритмам обучаются модели и внедряются в продакшен.
Как продолжать успешно внедрять нейросетевые модели в основные бизнес-задачи, не тратя время на неэффективные рутинные процессы – в нашей новой статье.