В СУБД InterSystems Caché есть встроенная технология работы с неструктурированных данными iKnow, а также технология полнотекстового поиска iFind. Решили разобраться с технологией и заодно сделать что-то полезное. В итоге получился DocSearch — Веб приложение для поиска по документации InterSystems, с использованием технологий iKnow и iFind.
Многие из вас, кому довелось отвечать за небольшую подсеть, сталкивались с проблемой учёта работоспособности пары десятков машин. Либо Вам просто захотелось иметь возможность в любой момент времени из любой точки планеты узнать как себя чувствует ваша торрент-качалка, оставленная включенной дома.
Лично я разрабатывал эту систему для решения проблемы скрытого удаленного наблюдения за вверенными мне компами. На этапе реализации мне предложили получить некоторый профит с этого проекта и сделать все на BASH как проект для некоторой конференции.
… и вот, разгребая хлам, я нашел исходники. Время работы веб-программистом не прошло даром, было решено полностью переверстать и расширить функционал. Собственно, начнем…
Описание платформы, зависимости
Не так давно я обновился до 12.10й версии всеми любимой Kubuntu (Ubuntu с KDE в качестве WM, GNOME не переношу). Система девственно чиста, никаких манипуляций с ней не производилось, так что в ней не будет пакетов, которых нет у Вас.
Ядро 3.5.0-21, KDE. Для работы самой системы нам понадобятся дополнительные пакеты, которые можно найти в стандартном репозитории. Набираем следующее:
Все отлично знают, что из класса обменных сортировок самый быстрый метод – это так называемая быстрая сортировка. О ней пишут диссертации, её посвящено немало статей на Хабре, на её основе придумывают сложные гибридные алгоритмы. Но сегодня речь пойдёт не про quick sort, а про другой обменный способ – старую добрую пузырьковую сортировку и её улучшения, модификации, мутации и разновидности.
Практический выхлоп от данных методов не ахти какой и многие хабрапользователи всё это проходили ещё в первом классе. Поэтому статья адресована тем, кто только-только заинтересовался теорией алгоритмов и делает в этом направлении первые шаги.
Мы уже писали о том, какой замечательный инструмент как LLD есть в Zabbix.
Тогда же мы посетовали, что составные индексы в SNMP-таблицах в системе не поддерживаются, что несколько ограничивает возможности по применению. Например, если вам нужно сделать Discovery двух RAID-контроллеров на одном сервере и всех физических и логических дисков за ними, то, увы, мы этого сделать не могли без костылей. Работало только для первого RAID-контролера в списке. Но, как говорится, все течет, все меняется! И вот долгожданный релиз 2.2 убрал это связывающее нас по рукам ограничение.
Рассказать о нововведении я бы хотел на примере шаблона для HP серверов. Но сначала немножко вспомним про SNMP.
Мониторинг большого количества устройств требует в помощь инструменты автоматизации. Иначе, если все делать мышкой, то можно “укликаться”, пока добавишь и настроишь все, что требовалось. К тому же, обязательно где-нибудь ошибёшься, человек не робот. Благо, в Zabbix все эти инструменты есть: это шаблоны, API, обнаружение сетевых устройств, авторегистрация Zabbix-агентов.
И вот с версии 2.0 сюда добавилось Low-Level Discovery (LLD) или низкоуровневое обнаружение. Хотелось бы рассказать что это такое.
Анализаторы трафика являются полезным и эффективным инструментом в жизни администратора сети, они позволяют «увидеть» то что на самом деле передается в сети, чем упрощают диагностику разнообразных проблем или же изучение принципов работы тех или иных протоколов и технологий.
Однако в сети зачастую передается достаточно много разнообразных блоков данных, и если заставить вывести на экран все, что проходит через сетевой интерфейс, выделить то, что действительно необходимо, бывает проблематично.
Для решения этой проблемы в анализаторах трафика реализованы фильтры, которые разделены на два типа: фильтры захвата и фильтры отображения. Сегодня пойдет речь о первом типе фильтров – о фильтрах захвата. Фильтры захвата, это разновидность фильтров, позволяющая ограничить захват кадров только теми, которые необходимы для анализа, уменьшив, таким образом, нагрузку на вычислительные ресурсы компьютера, а также упростив процесс анализа трафика.
abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh.
Предупреждение: пост очень объёмный, но для удобства использования я решил не резать его на части.
Оглавление:
управление ключами
копирование файлов через ssh
Проброс потоков ввода/вывода
Монтирование удалённой FS через ssh
Удалённое исполнение кода
Алиасы и опции для подключений в .ssh/config
Опции по-умолчанию
Проброс X-сервера
ssh в качестве socks-proxy
Проброс портов — прямой и обратный
Реверс-сокс-прокси
туннелирование L2/L3 трафика
Проброс агента авторизации
Туннелирование ssh через ssh сквозь недоверенный сервер (с большой вероятностью вы этого не знаете)
В этой статье я расскажу о том, как мы подружили Cache + Erlang, и зачем нам это нужно. СУБД Cache была выбрана в качестве хранилища данных. Также мы создали и эксплуатируем MCA(Middleware for Cache Applications) — промежуточное программное обеспечение, обеспечивающее конкурентную модель взаимодействия Erlang и Cache.
Для взаимодействия Erlang и Intersystems Cache реализованы возможности:
Обрабатывать в Cache сообщения из Erlang, транслируя Erlang tuples (внутренний древовидный формат данных Erlang) в глобалы Cache.
Посылать из Cache сообщения процессам Erlang, транслируя глобалы Cache в Erlang tuples.
Разработанное MCA состоит из трёх основных компонент:
Message Dispatcher(MD) — управляет обменом сообщениями в конкурентных условиях между различными Erlang-node(EN) и Cache-процессами, обеспечивает кэширование сообщений по определенным правилам. Запускается в соответствующем EN.
C-node — обеспечивает подгрузку С/C++ библиотек и обмен сообщениями между ними, взаимодействие системы с shared-memory, EN, CallIn/CallOut (функциональностью, реализованной в Cache на языке С) и т.д. На данный момент к С-node, для веб-приложений, c использованием Cache, нами подключены библиотеки для поддержки XSLT преобразования, обработки регулярных выражений.
Porte – шлюз обмена сообщениями (Messaging Gateway) c MD для Cache. Запускается как отдельный background job, который будем называть Porte-job(PJ).
Это продолжение моего рассказа про Natural Language Processing технологию Intersystems iKnow, начало здесь. Во второй части вы найдете описание практической работы с iKnow. Мы создадим домен, настроим его, загрузим текст. Затем, посмотрим и проанализируем результаты. Подробнее об этом под катом…
В данной статье хочу рассказать, как я строил систему ограничения входящего и исходящего трафика в Linux.
Как и учет трафика, ограничение полосы пропускания в сети является очень важной задачей, хотя первое с каждым годом всё быстрее отходит на второй план, шейпинг трафика остается необходимой задачей каждого системного/сетевого администратора.
Данная статья касается современных линуксов. Например, RHEL6 с ядрами 2.6.3х — подойдёт, а вот RHEL5 с ядрами 2.6.18 (кстати, наиболее популярный в продакшне) — увы, нет. И ещё — здесь не будет описания ядерных отладчиков или скриптов SytemTap; только старые-добрые простые команды вида «cat /proc/PID/xyz» в отношении некоторых полезных узлов файловой системы /proc.
Диагностика «тормозящего» процесса
Вот хороший пример часто возникающей проблемы, которую я воспроизвёл на своём лаптопе: пользователь жалуется, что команда find работает «значительно медленнее», при этом не возвращая никаких результатов. Зная, в чём дело, мы решили проблему. Однако меня попросили изложить систематический подход к решению подобных задач.
К счастью, система работает под управлением OEL6, т.е. на достаточно свежем ядре (а именно — 2.6.39 UEK2)
Мне давно хотелось написать свою статью о технологии iKnow. Прошло уже три года с момента её появления, но публикаций о применениях этой технологии в русскоязычных решениях до сих пор не было. Объяснение этому довольно простое – не было полноценной поддержки русского языка. Но с каждым новым релизом, начиная с Cache 2013.1, ситуация менялась в лучшую сторону. И вот, наконец, мы решили реализовать первый проект на iKnow. О том, как это было, что получилось, а что нет, читайте далее в моей статье.
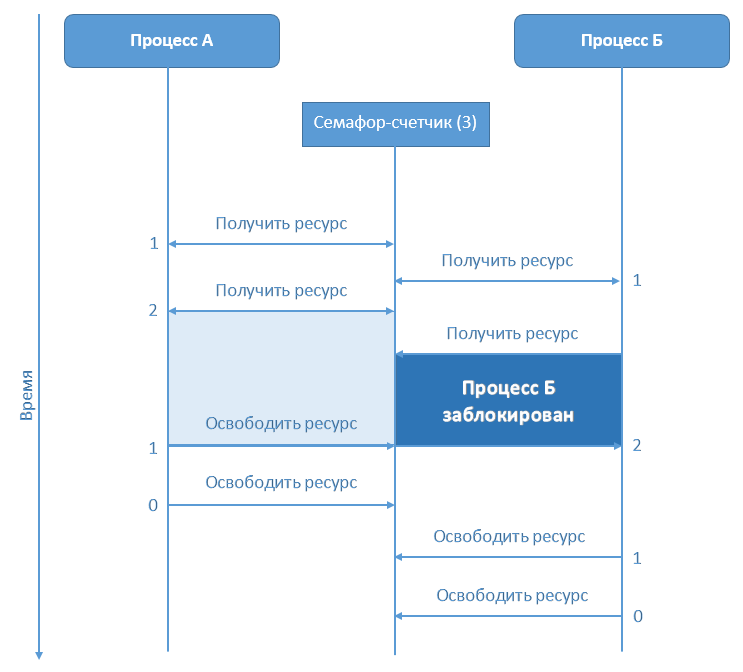
Часто при многопользовательском или параллельном доступе к данным возникает ситуация, когда необходимо заблокировать/дать доступ к переменной или участку памяти одновременно нескольким процессам. Решается данная задача с помощью мьютексов, семафоров, мониторов и т. д. В данном посте рассмотрим как же реализован один из методов предоставления совместного доступа к данным — семафор — в СУБД Intersystems Caché.
Одним из самых страшных бичей сети ethernet являются, так называемые, петли. Они возникают когда (в основном из-за человеческого фактора) в топологии сети образуется кольцо. К примеру, два порта коммутатора соединили патч-кордом (часто бывает когда два свича заменяют на один и не глядя втыкают всё, что было) или запустили узел по новой линии, а старую отключить забыли (последствия могут быт печальными и трудно выявляемыми). В результате такой петли пакеты начинают множиться, сбиваются таблицы коммутации и начинается лавинообразный рост трафика. В таких условиях возможны зависания сетевого оборудования и полное нарушение работы сети.
Помимо настоящих петель не редки случаи когда при выгорания порта (коммутатора или сетевой карты) он начинает возвращать полученные пакеты назад в сеть, при этом чаще всего соединение согласовывается в 10M, а линк поднимается даже при отключенном кабеле. Когда в сегменте такой порт только один, последствия могут быть не столь плачевными, но всё же весьма чувствительны (особенно сильно страдают пользователи висты и семёрки). В любом случае с такими вещами нужно нещадно бороться и понимать тот факт, что намеренно или случайно создавая петлю, пусть и на небольшой период времени, можно отключить целый сегмент сети.
Так уж повелось, что программисты закрепляют удачные решения в виде шаблонов проектирования. По шаблонам существует множество литературы. Классикой безусловно считается книга Банды четырех «Design Patterns» by Erich Gamma, Richard Helm, Ralph Johnson and John Vlissides" и еще, пожалуй, «Patterns of Enterprise Application Architecture» by Martin Fowler. Лучшее из того, что я читал с примерами на PHP – это «PHP Objects, Patterns and Practice» by Matt Zandstra. Так уж получилось, что вся эта литература достаточно сложна для людей, которые только начали осваивать ООП. Поэтому у меня появилась идея изложить некоторые паттерны, которые я считаю наиболее полезными, в сильно упрощенном виде. Другими словами, эта статья – моя первая попытка интерпретировать шаблоны проектирования в KISS стиле.
Сегодня речь пойдет о том, какие проблемы могут возникнуть с инициализацией объектов в ООП приложении и о том, как можно использовать некоторые популярные шаблоны проектирования для решения этих проблем.
Большинство литературы посвященной паттернам в ООП (объектно-ориентированном программировании), как правило, объясняются на примерах с самим кодом. И это правильный подход, так как паттерны ООП уже по-умолчанию предназначаются для людей, которые знают что такое программирование и суть ООП. Однако порой требуется заинтересовать этой темой людей, которые в этом совершенно ничего не понимают, например «не-программистов» или же просто начинающих «компьютерщиков». Именно с этой целью и был подготовлен данный материал, который призван объяснить человеку любого уровня знаний, что такое паттерн ООП и, возможно, привлечет в ряды программистов новых «адептов», ведь программирование это на самом деле очень интересно.
Статья предназначена исключительно для новичков, так что «старожилы» ничего нового для себя не узнают. В основном статья описывает известные паттерны из книги «Приемы объектно-ориентированного программирования. Шаблоны проектирования.», но более популярным и простым языком.
Возможно не все, кто знаком с InterSystems Caché, знают о расширениях Студии по работе с исходным кодом. На самом деле в ней можно создать свой тип исходного кода, компилировать его в интерпретируемый (INT) и объектный код, и даже в некоторых случаях обеспечить и code completion. Т.е. теоретически можно реализовать поддержку в Студии любого языка программирования, который будет исполняться СУБД не хуже Caché ObjectScript. В этой статье я опишу простой пример, как реализовать возможность писать программы на некотором подобии JavaScript в Caché Студии. Если интересно, добро пожаловать под кат.
Уже были статьи про основы гита (0, 1, 2), были и статьи про внутреннее устройство репозитория. Сегодня поговорим, как простому смертному работать с гитом на автопилоте и не морочить себе голову.
Во-первых, шорткаты (в порядке убывания популярности):
alias gst='git-status'
alias ga='git-add'
alias gc='git-commit -m'
alias gp='git pull && git push'
alias gull='git pull'
alias gush='git push'
alias gb='git-branch'
alias gco='git-checkout'
alias gd='git-diff'
Во-вторых, отображение текущей ветки в командной строке:




 abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh.
abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh.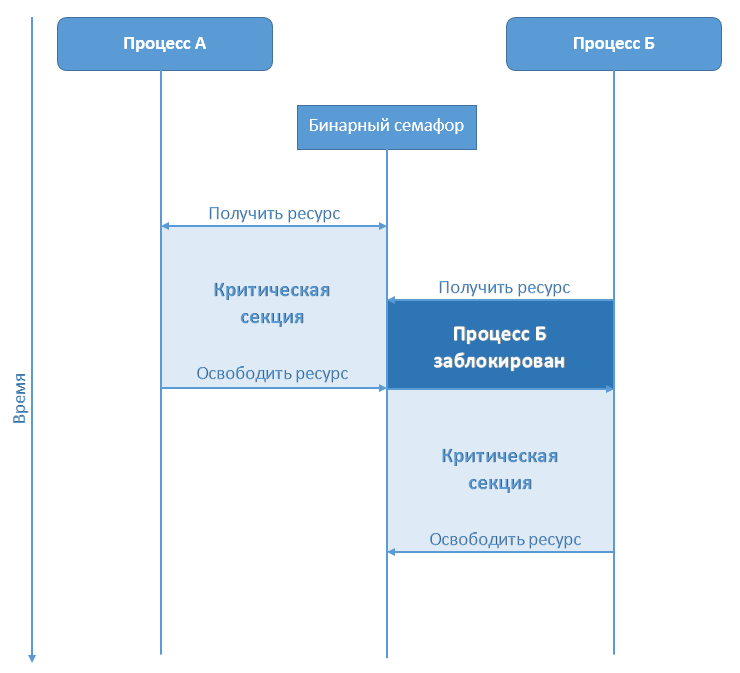
 Большинство литературы посвященной паттернам в ООП (объектно-ориентированном программировании), как правило, объясняются на примерах с самим кодом. И это правильный подход, так как паттерны ООП уже по-умолчанию предназначаются для людей, которые знают что такое программирование и суть ООП. Однако порой требуется заинтересовать этой темой людей, которые в этом совершенно ничего не понимают, например «не-программистов» или же просто начинающих «компьютерщиков». Именно с этой целью и был подготовлен данный материал, который призван объяснить человеку любого уровня знаний, что такое паттерн ООП и, возможно, привлечет в ряды программистов новых «адептов», ведь программирование это на самом деле очень интересно.
Большинство литературы посвященной паттернам в ООП (объектно-ориентированном программировании), как правило, объясняются на примерах с самим кодом. И это правильный подход, так как паттерны ООП уже по-умолчанию предназначаются для людей, которые знают что такое программирование и суть ООП. Однако порой требуется заинтересовать этой темой людей, которые в этом совершенно ничего не понимают, например «не-программистов» или же просто начинающих «компьютерщиков». Именно с этой целью и был подготовлен данный материал, который призван объяснить человеку любого уровня знаний, что такое паттерн ООП и, возможно, привлечет в ряды программистов новых «адептов», ведь программирование это на самом деле очень интересно.