Несмотря на огромную популярность аппарата графических моделей для решения задачи структурной классификации, задача настройки их параметров по обучающей выборке долгое время оставалась открытой. В своем докладе
Дмитрий Ветров, рассказал об обобщении метода опорных векторов и некоторых особенностях его применения для настройки параметров графических моделей. Дмитрий – руководитель группы Байесовских методов, доцент ВМК МГУ и преподаватель в ШАДе.
Видеозапись доклада.
План доклада:
- Байесовские методы в машинном обучении.
- Задачи с взаимозависимыми скрытыми переменными.
- Вероятностные графические модели
- Метод опорных векторов и его обобщение для настройки параметров графических моделей.
Сама концепция машинного обучения довольно несложная – это, если говорить образно, поиск взаимосвязей в данных. Данные представляются в классической постановке набором объектов, взятых из одной и той же генеральной совокупности, у каждого объекта есть наблюдаемые переменные, есть скрытые переменные. Наблюдаемые переменные (дальше будем их обозначать
X) часто называются признаками, соответственно, скрытые переменные (
T) — это те, которые подлежат определению. Для того, чтобы эту взаимосвязь между наблюдаемыми и скрытыми переменными установить, предполагается, что у нас есть обучающая выборка, т.е. набор объектов, для которых известны и наблюдаемые и скрытые компоненты. Глядя на нее, мы пытаемся настроить некоторые решающие правила, которые нам позволят в дальнейшем, когда мы видим набор признаков, оценить скрытые компоненты. Процедура обучения приблизительно выглядит следующим образом: фиксируется множество допустимых решающих правил, которые как правило задаются с помощью весов (
W), а дальше каким-то образом в ходе обучения эти веса настраиваются. Тут же с неизбежностью возникает проблема переобучения, если у нас слишком богатое семейство допустимых решающих правил, то в процессе обучения мы легко можем выйти на случай, когда для обучающей выборки мы прекрасно прогнозируем ее скрытую компоненту, а вот для новых объектов прогноз оказывается плохой. Исследователями в области машинного обучения было потрачено немало лет и усилий для того, чтобы эту проблему снять с повестки дня. В настоящее время, кажется, что худо-бедно это удалось.



 В пятничном номере NY Times опубликована
В пятничном номере NY Times опубликована 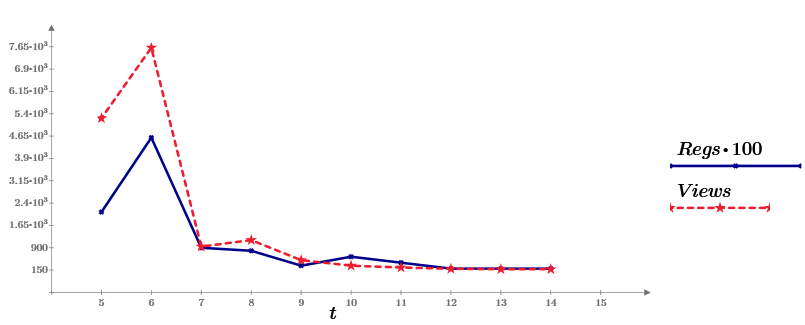






 Данная статья предназначена для разъяснения сути фундаментальных методов построения и оптимизации «искусственного интеллекта» для компьютерных игр (в основном
Данная статья предназначена для разъяснения сути фундаментальных методов построения и оптимизации «искусственного интеллекта» для компьютерных игр (в основном