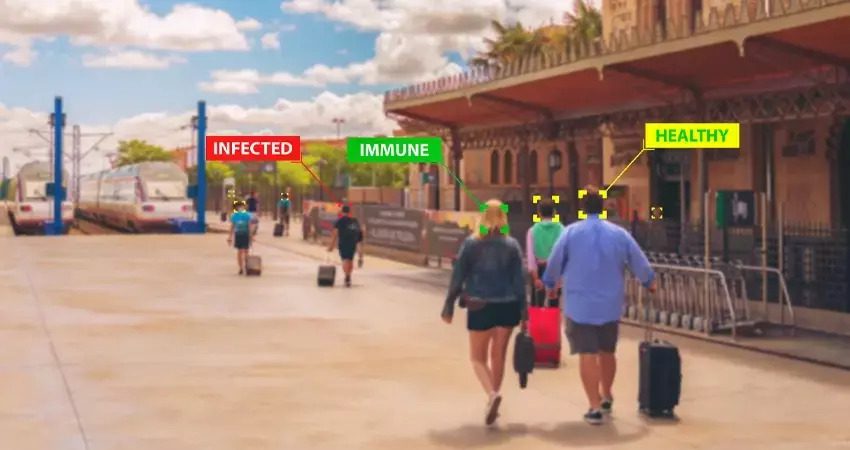
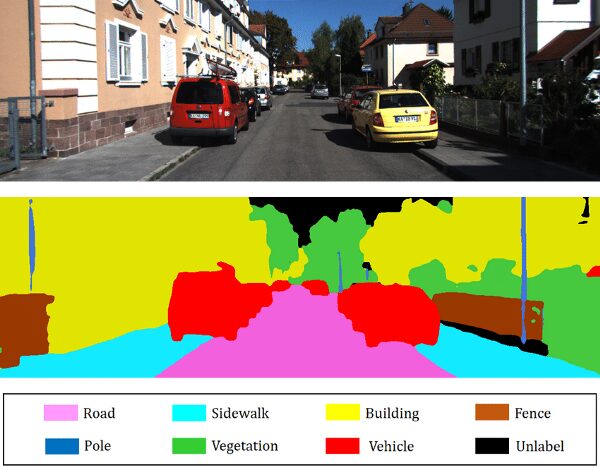
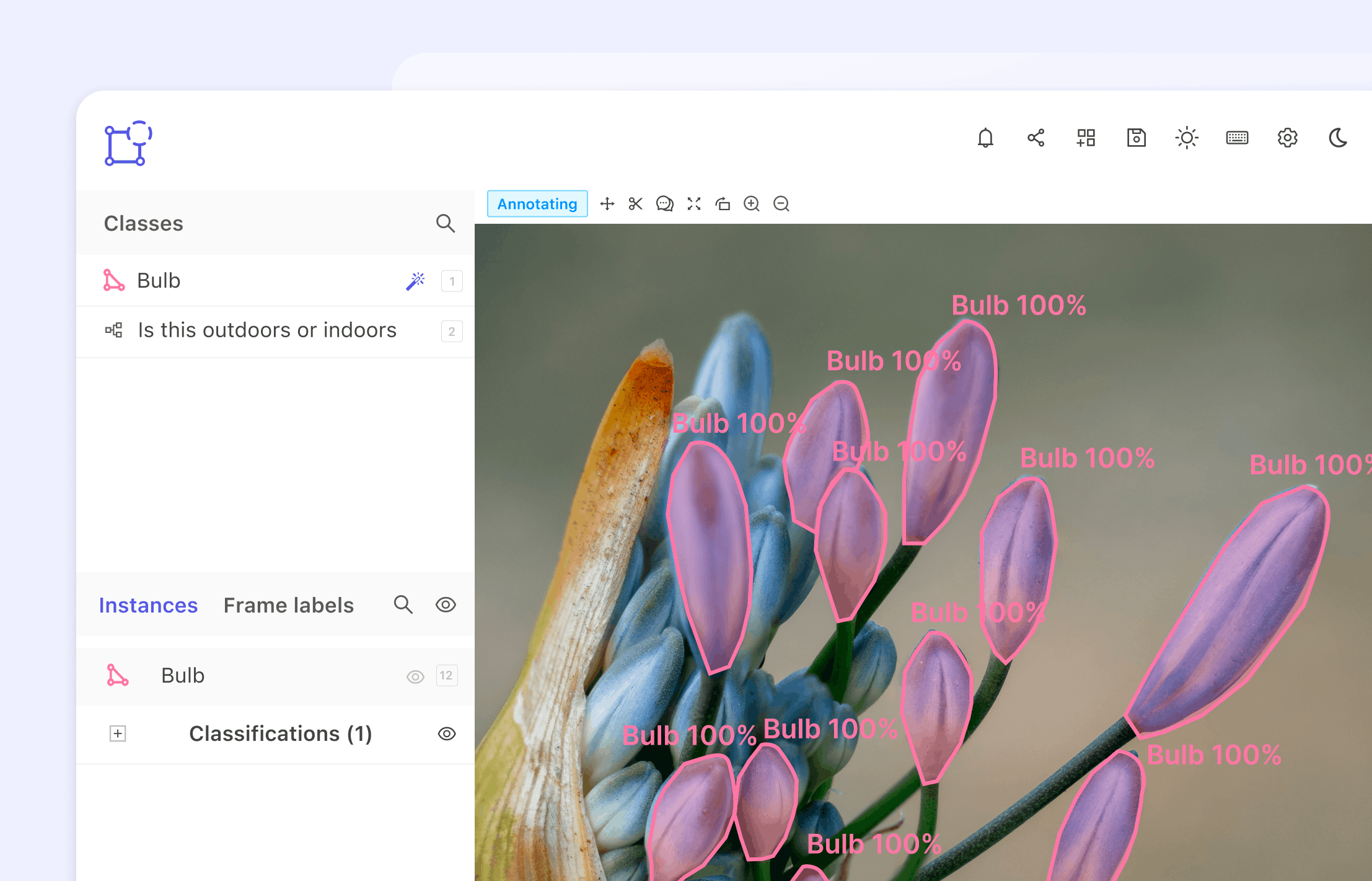
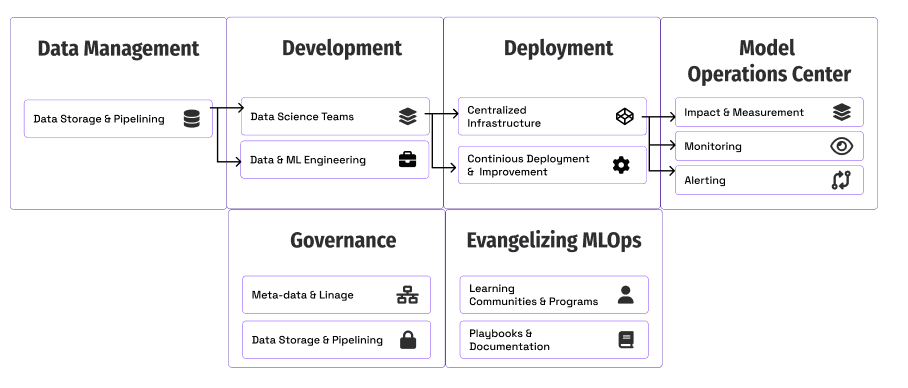
Качество данных играет критически важную роль в любом процессе управления данными. Организации используют данные для принятия решений и улучшения различных бизнес-показателей. Однако если данные усеяны неточностями, ошибками или несогласованностями, то они могут нанести больше вреда, чем пользы.
Согласно опросу
Gartner за 2020 год, в среднем потери из-за низкого качества данных составляют примерно $12,8 миллиона за год. Как сообщается в последнем отчёте
State of Data Quality, задержки продакшена (задержки с выпуском продукта) — характерный симптом низкого качества данных. Высококачественные и безошибочные данные повышают надёжность и верность полученных из них выводов.
Для повышения качества данных необходима система его оценки. В достижении этой цели вам помогут размерности качества данных. Размерности позволяют измерять покрытие и выявлять компоненты, требующие тестирования качества данных.
В этой статье рассматриваются шесть размерностей качества данных: полнота, согласованность, целостность, вневременная актуальность, уникальность и валидность. Определив их, вы сможете обеспечить исчерпывающее понимание качества данных и выявить аспекты, требующие совершенствования. И здесь нам на помощь приходит Great Expectation (GX).