Один мой друг сказал по поводу pv следующее «Я админю семь лет, мне нужна была эта тулза десятки раз, а я даже не знал что она существует». В размышлениях над тем как заполучить инвайт на Харбе, я набрал в поиске pv. И ничего не нашел.

Дмитрий @justm57
Пользователь
RabbitMQ tutorial 1 — Hello World
6 мин
Туториал
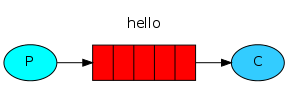
RabbitMQ позволяет взаимодействовать различным программам при помощи протокола AMQP. RabbitMQ является отличным решением для построения SOA (сервис-ориентированной архитектуры) и распределением отложенных ресурсоемких задач.
Под катом перевод первого из шести уроков официального сайта. Примеры на python, но его знание вовсе не обязательно. Аналогичные примеру программы можно воспроизвести практически на любом популярном ЯП. [так выглядят комментарии переводчика, т.е. меня]
Открытый курс машинного обучения. Тема 10. Градиентный бустинг
18 мин

Всем привет! Настало время пополнить наш с вами алгоритмический арсенал.
Сегодня мы основательно разберем один из наиболее популярных и применяемых на практике алгоритмов машинного обучения — градиентный бустинг. О том, откуда у бустинга растут корни и что на самом деле творится под капотом алгоритма — в нашем красочном путешествии в мир бустинга под катом.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
Python и красивые ножки: как я бы знакомил сына с математикой и программированием
4 мин
Раньше мы уже искали необычные модели Playboy с помощью библиотеки Python Scikit-learn. Теперь мы продемонстрируем некоторые возможности библиотек SymPy, SciPy, Matplotlib и Pandas на живом примере из разряда занимательных школьных задач по математике. Цель — облегчить порог вхождения при изучении Python библиотек для анализа данных.

Открытый курс машинного обучения. Тема 9. Анализ временных рядов с помощью Python
27 мин
Доброго дня! Мы продолжаем наш цикл статей открытого курса по машинному обучению и сегодня поговорим о временных рядах.
 Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
Открытый курс машинного обучения. Тема 8. Обучение на гигабайтах с Vowpal Wabbit
26 мин
Всем привет!

Вот мы постепенно и дошли до продвинутых методов машинного обучения. Сегодня обсудим, как вообще подступиться к обучению модели, если данных гигабайты или десятки гигабайт. Обсудим приемы, позволяющие это делать: стохастический градиентный спуск (SGD) и хэширование признаков, посмотрим на примеры применения библиотеки Vowpal Wabbit.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
Открытый курс машинного обучения. Тема 7. Обучение без учителя: PCA и кластеризация
19 мин
Привет всем! Приглашаем изучить седьмую тему нашего открытого курса машинного обучения!
 Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.
Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
Kaggle: Британские спутниковые снимки. Как мы взяли третье место
22 мин
Сразу оговорюсь, что данный текст — это не сухая выжимка основных идей с красивыми графиками и обилием технических терминов (такой текст называется научной статьей и я его обязательно напишу, но потом, когда нам заплатят призовые $20000, а то, не дай бог, начнутся разговоры про лицензию, авторские права и прочее.) (UPD: https://arxiv.org/abs/1706.06169). К моему сожалению, пока устаканиваются все детали, мы не можем поделиться кодом, который написали под эту задачу, так как хотим получить деньги. Как всё утрясётся — обязательно займемся этим вопросом. (UPD: https://github.com/ternaus/kaggle_dstl_submission)
Так вот, данный текст — это скорее байки по мотивам, в которых, с одной стороны, всё — правда, а с другой, обилие лирических отступлений и прочей отсебятины не позволяет рассматривать его как что-то наукоемкое, а скорее просто как полезное и увлекательное чтиво, цель которого показать, как может происходить процесс работы над задачами в дисциплине соревновательного машинного обучения. Кроме того, в тексте достаточно много лексикона, который специфичен для Kaggle и что-то я буду по ходу объяснять, а что-то оставлю так, например, вопрос про гусей раскрыт не будет.
Открытый курс машинного обучения. Тема 6. Построение и отбор признаков
24 мин
Сообщество Open Data Science приветствует участников курса!
В рамках курса мы уже познакомились с несколькими ключевыми алгоритмами машинного обучения. Однако перед тем как переходить к более навороченным алгоритмам и подходам, хочется сделать шаг в сторону и поговорить о подготовке данных для обучения модели. Известный принцип garbage in – garbage out на 100% применим к любой задаче машинного обучения; любой опытный аналитик может вспомнить примеры из практики, когда простая модель, обученная на качественно подготовленных данных, показала себя лучше хитроумного ансамбля, построенного на недостаточно чистых данных.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.

Открытый курс машинного обучения. Тема 5. Композиции: бэггинг, случайный лес
28 мин

Пятую статью курса мы посвятим простым методам композиции: бэггингу и случайному лесу. Вы узнаете, как можно получить распределение среднего по генеральной совокупности, если у нас есть информация только о небольшой ее части; посмотрим, как с помощью композиции алгоритмов уменьшить дисперсию и таким образом улучшить точность модели; разберём, что такое случайный лес, какие его параметры нужно «подкручивать» и как найти самый важный признак. Сконцентрируемся на практике, добавив «щепотку» математики.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
Список статей серии
- Первичный анализ данных с Pandas
- Визуальный анализ данных c Python
- Классификация, деревья решений и метод ближайших соседей
- Линейные модели классификации и регрессии
- Композиции: бэггинг, случайный лес
- Построение и отбор признаков
- Обучение без учителя: PCA, кластеризация
- Обучение на гигабайтах c Vowpal Wabbit
- Анализ временных рядов с помощью Python
- Градиентный бустинг
Открытый курс машинного обучения. Тема 4. Линейные модели классификации и регрессии
30 мин

Всем привет!
Сегодня мы детально обсудим очень важный класс моделей машинного обучения – линейных. Ключевое отличие нашей подачи материала от аналогичной в курсах эконометрики и статистики – это акцент на практическом применении линейных моделей в реальных задачах (хотя и математики тоже будет немало).
Пример такой задачи – это соревнование Kaggle Inclass по идентификации пользователя в Интернете по его последовательности переходов по сайтам.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Все материалы доступны на GitHub.
А вот видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017). В ней, в частности, рассмотрены два бенчмарка соревнования, полученные с помощью логистической регрессии.
Библиотеки для глубокого обучения Theano/Lasagne
14 мин
Туториал
 Привет, Хабр!
Привет, Хабр!
Параллельно с публикациями статей открытого курса по машинному обучению мы решили запустить ещё одну серию — о работе с популярными фреймворками для нейронных сетей и глубокого обучения.
Я открою этот цикл статьёй о Theano — библиотеке, которая используется для разработки систем машинного обучения как сама по себе, так и в качестве вычислительного бекэнда для более высокоуровневых библиотек, например, Lasagne, Keras или Blocks.
Theano разрабатывается с 2007 года главным образом группой MILA из Университета Монреаля и названа в честь древнегреческой женщины-философа и математика Феано (предположительно изображена на картинке). Основными принципами являются: интеграция с numpy, прозрачное использование различных вычислительных устройств (главным образом GPU), динамическая генерация оптимизированного С-кода.
Открытый курс машинного обучения. Тема 2: Визуализация данных c Python
15 мин

Второе занятие посвящено визуализации данных в Python. Сначала мы посмотрим на основные методы библиотек Seaborn и Plotly, затем поанализируем знакомый нам по первой статье набор данных по оттоку клиентов телеком-оператора и подглядим в n-мерное пространство с помощью алгоритма t-SNE. Есть и видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Сейчас статья уже будет существенно длиннее. Готовы? Поехали!
Открытый курс машинного обучения. Тема 3. Классификация, деревья решений и метод ближайших соседей
33 мин

Привет всем, кто проходит курс машинного обучения на Хабре!
В первых двух частях (1, 2) мы попрактиковались в первичном анализе данных с Pandas и в построении картинок, позволяющих делать выводы по данным. Сегодня наконец перейдем к машинному обучению. Поговорим о задачах машинного обучения и рассмотрим 2 простых подхода – деревья решений и метод ближайших соседей. Также обсудим, как с помощью кросс-валидации выбирать модель для конкретных данных.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Открытый курс машинного обучения. Тема 1. Первичный анализ данных с Pandas
Простой
15 мин
Туториал

Открытый курс машинного обучения mlcourse.ai сообщества OpenDataScience – это сбалансированный по теории и практике курс, дающий как знания, так и навыки (необходимые, но не достаточные) машинного обучения уровня Junior Data Scientist. Нечасто встретите и подробное описание математики, стоящей за используемыми алгоритмами, и соревнования Kaggle Inclass, и примеры бизнес-применения машинного обучения в одном курсе. С 2017 по 2019 годы Юрий Кашницкий yorko и большая команда ODS проводили живые запуски курса дважды в год – с домашними заданиями, соревнованиями и общим рейтингом учаcтников (имена героев запечатлены тут). Сейчас курс в режиме самостоятельного прохождения.
Chatbot на базе рекуррентной нейронной сети своими руками за 1 вечер/6$ и ~ 100 строчек кода
10 мин
Туториал
Перевод
В данной статье я хочу показать насколько просто сегодня использовать нейронные сети. Вокруг меня довольно много людей одержимы идеей того, что нейронки может использовать только исследователь. И что бы получить хоть какой то выхлоп, нужно иметь как минимуму кандидатскую степень. А давайте на реальном примере посмотрим как оно на самом деле, взять и с нуля за один вечер обучить chatbot. Да еще не просто абы чем а самым что нинаесть ламповым TensorFlow. При этом я постарался описать все настолько просто, что-бы он был понятен даже начинающему программисту! В путь!
