
Serde — это высокопроизводительная библиотека для сериализации и десериализации данных в Rust. Она поддерживает различные форматы данных, включая JSON, YAML, TOML, BSON и многие другие.
В этой статье рассмотрим основы Serde в Rust.

User
Serde — это высокопроизводительная библиотека для сериализации и десериализации данных в Rust. Она поддерживает различные форматы данных, включая JSON, YAML, TOML, BSON и многие другие.
В этой статье рассмотрим основы Serde в Rust.

Этот парень открыл все турникеты на станции. Вы до сих пор считаете, что все хакеры вредны?
Начну с простого вопроса: кто из вас пользуется общественным транспортом? А кому нравится за него платить? Если такие все же найдутся, то могут смело переставать читать статью. Для остальных у меня есть рассказ о том, как четверо старшеклассников из Массачусетса взломали местную транспортную систему.
Жителям Бостона статья поможет получить бесплатные поездки, а для всех остальных этот материал будет неплохим уроком по реверс-инжинирингу. Ну или, по крайней мере, вы узнаете любопытную историю.

Без выстраивания хороших отношений со стейкхолдерами (или заинтересованными сторонами) на проекте далеко не уедешь. О том, как это делать like a boss, – годная статья автора Кэт Бугард в блоге Miro.
Все картинки – из Miro.


Подготовка документации — дело затратное. Прежде чем приступать к ней, нужно подумать, действительно ли она нужна, или это делается, потому что «так принято».
В статье я подробно остановился на ситуациях, когда написать её необходимо. Если в одной из них вы узнаете свой проект, то документация сильно поможет в его реализации.
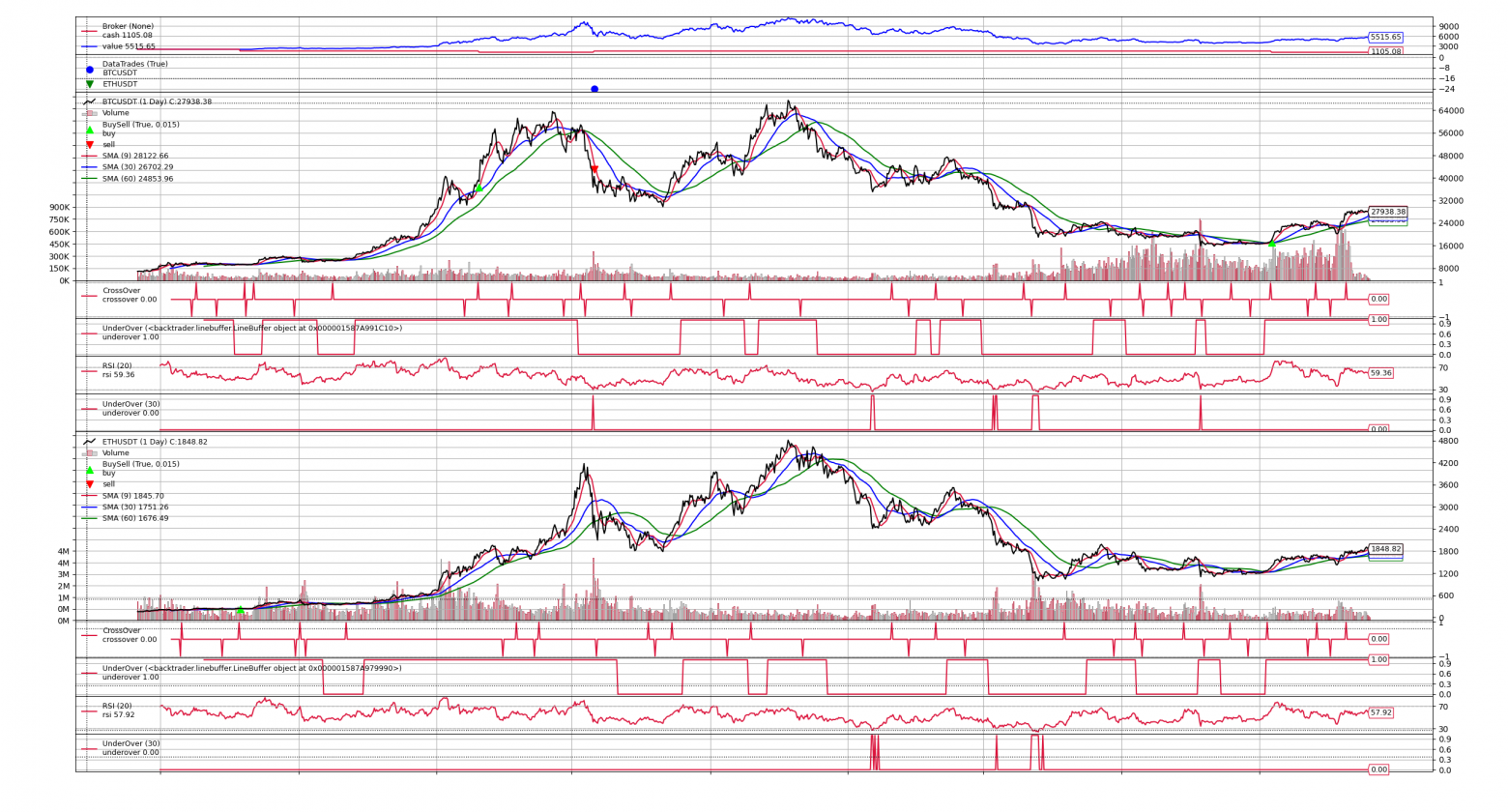
Программирование для меня это хобби и любимое дело. А так я сертифицированный системный архитектор. Поэтому прошу не особо ругать за код :-)
В настоящее время я увлекаюсь написанием торговых роботов. Постепенно изучаю нейросети для их применения к анализу цен/объемов акций/фьючерсов.
Обычно я писал торговых роботов для работы с Брокерами и делал авто-торговлю Акциями или Фьючерсами, но вдруг возникла мысль:
- А что, если уже готовый код можно применять и на других активах??? Например на крипто активах для Биткоина или Эфира или других?
Уже изучив много библиотек и примеров за долгое время написания своих торговых роботов, решил сделать небольшую библиотеку backtrader_binance для интеграции API Binance и библиотеки тестирования торговых стратегий Backtrader.
Вот с помощью backtrader_binance, сейчас и создадим алго-робота для торговли BTC и ETH.

Михаил Михайлец, руководитель группы аналитиков направления облачных решений Лиги Цифровой Экономики, рассказал, как его команда попробовала быстро подготовить задачи по классическому ТЗ (ГОСТ 19) в Jira при работе с государственным заказчиком и что из этого получилось.
Пожалуй, большинству известно, что ГОСТ предусматривает водопадную модель разработки ПО. До недавнего времени она была зафиксирована в постановлении Правительства Российской Федерации от 6 июля 2015 г. № 676 «О требованиях к порядку создания, развития, ввода в эксплуатацию, эксплуатации и вывода из эксплуатации государственных информационных систем и дальнейшего хранения содержащейся в их базах данных информации».
Несмотря на обнадеживающее движение в сторону итеративной разработки со стороны правительства, стандарты пока обновляться не спешат. Годы выпуска действующих ГОСТов, которые идут после тире в их номерах, тонко намекают, что гибкие подходы в разработке не учитывались при их создании.
В теории можно породить жизнеспособного «кентавра» — если в течение спринтов проходить указанные стадии проекта раз за разом в ходе разработки каждой функции приложения.

Всем привет, меня зовут Гай, и я консультант, помогающий IT-компаниям проводить стратегические сессии и разрабатывать стратегию компании.
В данной статье я хочу описать три пункта стратегирования:
1. Фрейм стратегического анализа и постановки целей.
2. Как картировать набор решений, чтобы цели дошли до нижних звеньев.
3. Психотипирование кадров как важнейший пункт реализации стратегии.
Я проводил стратегические сессии в паре десятков отечественных ИТ-компаний, в том числе и с драгоценной для нас с вами компанией «Хабр» я работаю уже три года.

Всем привет! Меня зовут Игорь Дергунов и я руководитель инновационной лаборатории Digital Design, которая занимается оптимизацией бизнес-процессов с помощью методов машинного обучения. В процессе работы над проектами в данной сфере быстро приходит осознание необходимости учета и структурирования проводимых экспериментов. В нашем случае мы воспользовались инструментом MLflow, который предоставляет функциональность для отслеживания экспериментов и управления жизненным циклом моделей машинного обучения.
И все шло хорошо, результаты проверки гипотез (параметры обучения, метрики, артефакты и модели) сохранялись, их было удобно наглядно сравнивать, и все были довольны. Так продолжалось достаточно долгое время, пока не возникла необходимость вернуться к эксперименту, который выполнялся какое-то время назад и был приостановлен.

Привет, Хабр! На связи Рустем, IBM Senior DevOps Engineer и сегодня я хотел бы продолжить наше знакомство с инструментом в DataOps инженирии — Apache Airflow. Сегодня мы спроектируем ETL-пайплайн.

Управлять проектами машинного обучения (Machine learning) и data science сложно, поскольку проекты часто носят исследовательский характер, и трудно предсказать, сколько времени потребуется на их завершение. Часто всё начинается с одной идеи, а затем перетекает в новое направление, когда предложенный метод не срабатывает или если предположения относительно данных оказываются неверными.
Построение модели также является длительным процессом (по сравнению с работой в сфере программного обеспечения и аналитики), и data scientist нередко попадает в кроличью нору и тратит месяцы на проект, не имея четких представлений о прогрессе. Еще одно отличие от стандартных практик разработки программного обеспечения заключается в том, что построение модели обычно выполняется всего одним человеком, и это не совсем вписывается в традиционные командные рабочие процессы, такие как Kanban и Scrum.
Я потратил достаточно много времени, изучая существующие рабочие процессы (в основном в Jira) с точки зрения пригодности для управления проектами машинного обучения и data science, но безуспешно. Большая часть информации нацелена на разработку программного обеспечения и фокусируется на Agile методологиях. Обсуждая этот вопрос с коллегами и друзьями мне не удалось найти ничего, что было бы адаптировано для машинного обучения и data science. Я заметил, что часть коллег пытаются адаптировать свой рабочий процесс к стандартной инженерной практике, в других же случаях, они вообще не пытаются управлять проектами. Последнее особенно проблематично, по причине того, что проекты, которые требуют слишком много времени и замахиваются на слишком большую предметную область, вероятнее всего провалятся.
Поскольку мне не удалось найти подходящее решение, я решил разработать собственную рабочую схему для управления проектами машинного обучения и data science. Данный процесс может быть реализован в Jira и позволяет мне легко отслеживать статус проектов, вести отчетность, а также не давать раздуваться предметной области, избегая построения чересчур сложных моделей. У наших исследователей появляется рабочая схема, которая помогает им в построении модели, что повышает их успехи в проекте. Я пользуюсь этой системой уже несколько лет, и мы с моей командой очень довольны ею.


В этой статье я расскажу вам об операциях машинного обучения (MLOps) — области, которую можно охарактеризовать как DevOps для машинного обучения.
Адрес TCP/IP поддерживает только 65000 подключений, поэтому придётся назначить этому серверу примерно 30000 IP-адресов.
Существует 65535 номеров TCP-портов, значит ли это, что к TCP-серверу может подключиться не более 65535 клиентов? Можно решить, что это накладывает строгое ограничение на количество клиентов, которые может поддерживать один компьютер/приложение.
Если есть ограничение на количество портов, которые может иметь одна машина, а сокет можно привязать только к неиспользуемому номеру порта, как с этим справляются серверы, имеющие чрезвычайно большое количество запросов (больше, чем максимальное количество портов)? Эта проблема решается распределением системы, то есть кучей серверов на множестве машин?

В данной статье я расскажу о том, как я сделал из Raspberry Pi маршрутизатор, способный перенаправлять отдельные сайты, отдельные подсети, да хоть все запросы через tor.



 Суффиксное дерево – мощная структура, позволяющая неожиданно эффективно решать мириады сложных поисковых задач на неструктурированных массивах данных. К сожалению, известные алгоритмы построения суффиксного дерева (главным образом алгоритм, предложенный Эско Укконеном (Esko Ukkonen)) достаточно сложны для понимания и трудоёмки в реализации. Лишь относительно недавно, в 2011 году, стараниями Дэни Бреслауэра (Dany Breslauer) и Джузеппе Италиано (Giuseppe Italiano) был придуман сравнительно несложный метод построения, который фактически является упрощённым вариантом алгоритма Питера Вейнера (Peter Weiner) – человека, придумавшего суффиксные деревья в 1973 году. Если вы не знаете, что такое суффиксное дерево или всегда его боялись, то это ваш шанс изучить его и заодно овладеть относительно простым способом построения.
Суффиксное дерево – мощная структура, позволяющая неожиданно эффективно решать мириады сложных поисковых задач на неструктурированных массивах данных. К сожалению, известные алгоритмы построения суффиксного дерева (главным образом алгоритм, предложенный Эско Укконеном (Esko Ukkonen)) достаточно сложны для понимания и трудоёмки в реализации. Лишь относительно недавно, в 2011 году, стараниями Дэни Бреслауэра (Dany Breslauer) и Джузеппе Италиано (Giuseppe Italiano) был придуман сравнительно несложный метод построения, который фактически является упрощённым вариантом алгоритма Питера Вейнера (Peter Weiner) – человека, придумавшего суффиксные деревья в 1973 году. Если вы не знаете, что такое суффиксное дерево или всегда его боялись, то это ваш шанс изучить его и заодно овладеть относительно простым способом построения.