
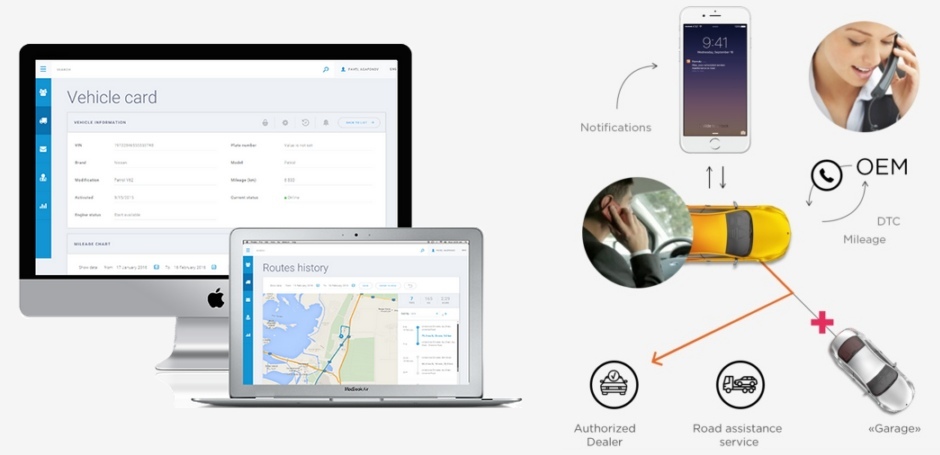
Ни для кого не секрет, что .net сейчас используется в большинстве случаев как инструмент бэкенд разработки, а в клиентской разработке последние лет 5 правит js сообщество с своей экосистемой и инструментами для разработки. Это все безобразие с каждым годом усиливает пропасть между фронтэндом и бэкендом, и планка вхождения в область становится все выше и выше, разработчики начинают делиться на два лагеря и уходит такое понятие как фуллстек.
Да, под Node.js можно написать сервер, но для бэковой разработки, все же, .net бесспорный лидер. На js, на мой взгляд, очень сложно написать гибкий и легко поддерживаемый бэкенд, хотя возможно многие со мной и не согласятся.
Давайтеударим автопробегом по бездорожью попытаемся вопреки всему этому написать SPA приложение с бэком на .net core и клиентом на js, из инструментов разработки будем использовать горячо любимую Visual Studio.
После этого туториала, я надеюсь, веб и бэк разработчикам будет проще найти почву под ногами в вражьей области и понять в какую сторону двигаться для более углубленного изучения. Поехали!
Да, под Node.js можно написать сервер, но для бэковой разработки, все же, .net бесспорный лидер. На js, на мой взгляд, очень сложно написать гибкий и легко поддерживаемый бэкенд, хотя возможно многие со мной и не согласятся.
Давайте
После этого туториала, я надеюсь, веб и бэк разработчикам будет проще найти почву под ногами в вражьей области и понять в какую сторону двигаться для более углубленного изучения. Поехали!












 Есть три агрегатные функции, которые чаще всего используются на практике: COUNT, SUM и AVG.
Есть три агрегатные функции, которые чаще всего используются на практике: COUNT, SUM и AVG. Однажды вечером подошел ко мне сын и сказал, что хочет поиграть в Марио. Летом у бабушки на даче он любил «зарубиться» в дождливую погоду. А за окном как раз дождь. Не долго думая я скачал ему первый попавшийся эмулятор 8-ми битной приставки и игру. Однако, оказалось, что удовольствие от игры на клавиатуре совсем не то. Идти покупать джойстик было уже поздно. И тогда я подумал, что можно обойтись и без него. Под рукой у нас была старенькая Nokia Lumia, ее размеры и форма примерно совпадали с нашими нуждами. Было решено написать джойстик. Сын отправился рисовать дизайн на листе бумаги в клеточку, а папа пошел варить кофе и думать, как бы осуществить эту идею с наименьшими временными затратами.
Однажды вечером подошел ко мне сын и сказал, что хочет поиграть в Марио. Летом у бабушки на даче он любил «зарубиться» в дождливую погоду. А за окном как раз дождь. Не долго думая я скачал ему первый попавшийся эмулятор 8-ми битной приставки и игру. Однако, оказалось, что удовольствие от игры на клавиатуре совсем не то. Идти покупать джойстик было уже поздно. И тогда я подумал, что можно обойтись и без него. Под рукой у нас была старенькая Nokia Lumia, ее размеры и форма примерно совпадали с нашими нуждами. Было решено написать джойстик. Сын отправился рисовать дизайн на листе бумаги в клеточку, а папа пошел варить кофе и думать, как бы осуществить эту идею с наименьшими временными затратами.