Всем привет. Меня зовут Александр, я Java-разработчик в группе компаний Tinkoff.
В данной статье хочу поделиться опытом решения проблем, связанных с синхронизацией состояния кэшей в распределенных системах. Мы столкнулись с ними, разбивая наше монолитное приложение на
В статье я расскажу про наш опыт перехода на сервис-ориентированную архитектуру, сопровождающуюся переездом в Kubernetes, и про решение сопутствующих проблем. Будет рассмотрен подход к организации системы распределенного кэширования In-Memory Data Grid (IMDG), его преимущества и недостатки, из-за которых мы решили написать собственное решение.
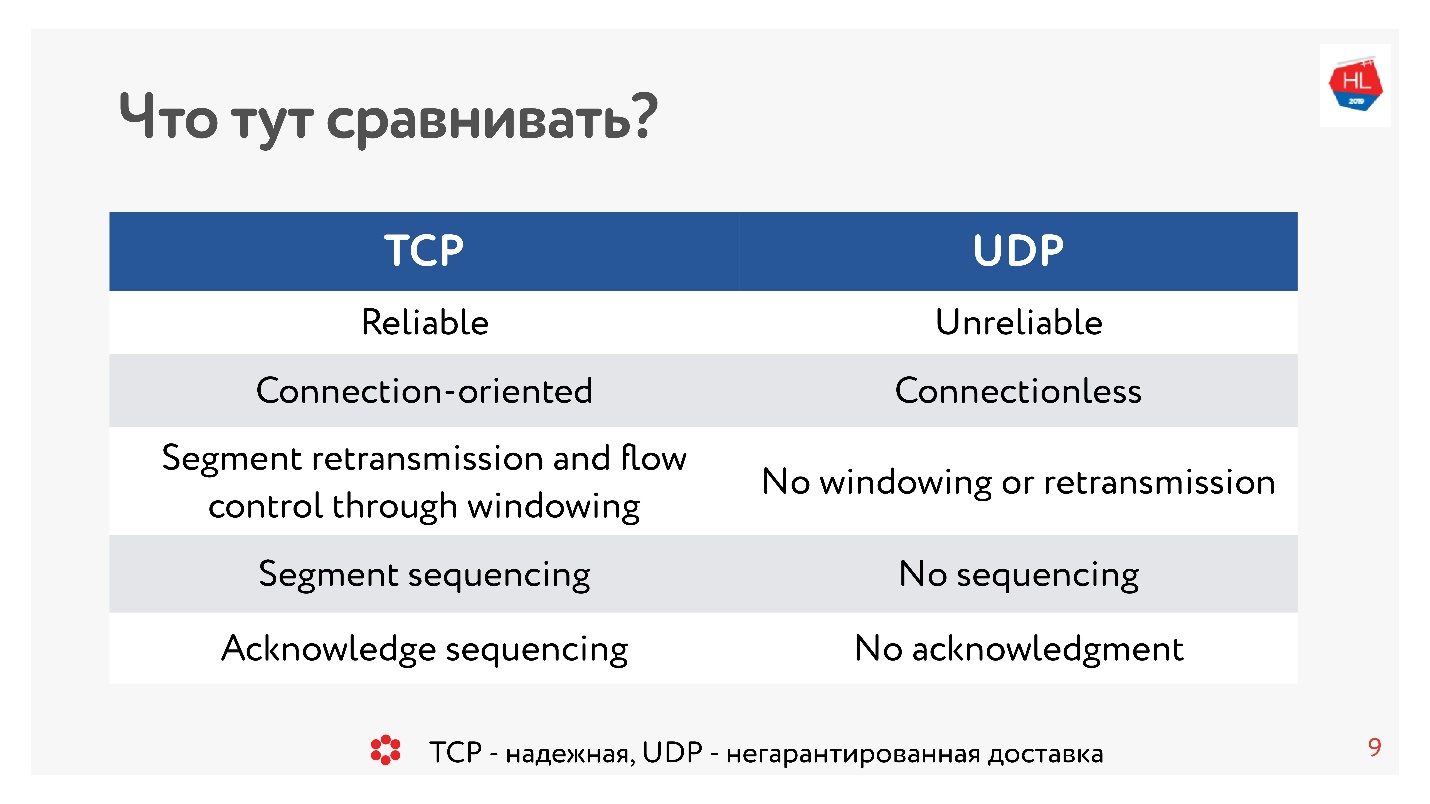
В статье рассматривается проект, бэкэнд которого написан на Java. Поэтому речь также пойдет про стандарты в области временного In-memory-кэширования. Обсудим спецификацию JSR-107, несостоявшуюся спецификацию JSR-347, а также особенности кэширования в Spring. Добро пожаловать под кат!

 Когда вы выросли настолько, что появились узлы в разных городах, возникает задача распределения нагрузки между ними. Задачи такой балансировки могут быть разными, но цель, как правило, одна: сделать так, чтобы было хорошо. У меня дошли руки рассказать о том, как это делают обычно, и как это сделано в
Когда вы выросли настолько, что появились узлы в разных городах, возникает задача распределения нагрузки между ними. Задачи такой балансировки могут быть разными, но цель, как правило, одна: сделать так, чтобы было хорошо. У меня дошли руки рассказать о том, как это делают обычно, и как это сделано в