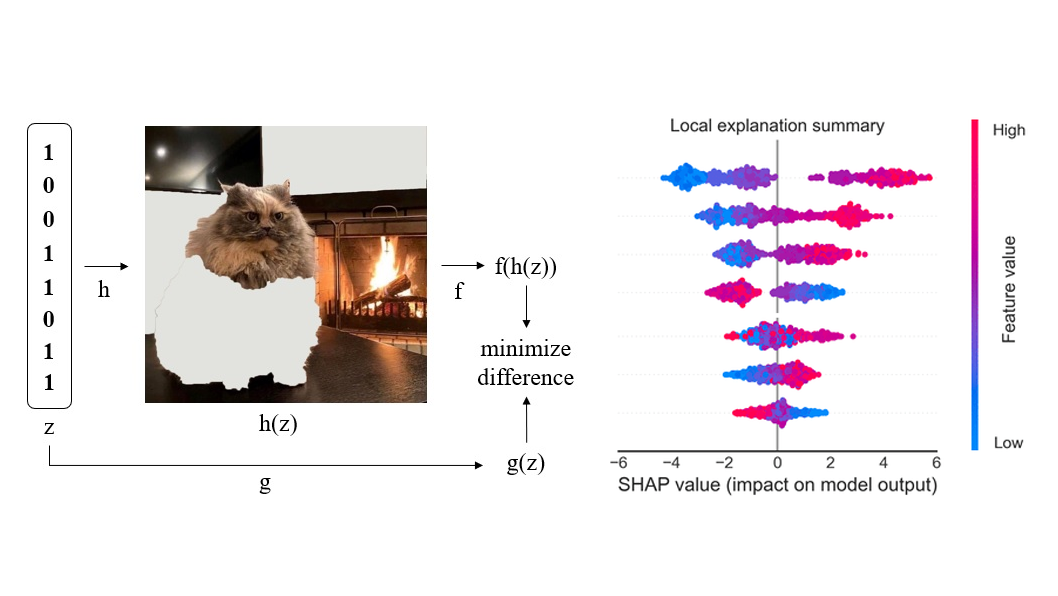
В этом обзоре мы рассмотрим, как методы LIME и SHAP позволяют объяснять предсказания моделей машинного обучения, выявлять проблемы сдвига и утечки данных, осуществлять мониторинг работы модели в production и искать группы примеров, предсказания на которых объясняются схожим образом.
Также поговорим о проблемах метода SHAP и его дальнейшем развитии в виде метода Shapley Flow, объединяющего интерпретацию модели и многообразия данных.
Специалисты по анализу данных часто оценивают свои прогностические модели с точки зрения точности и погрешности, но редко спрашивают себя:
«Способна ли моя модель спрогнозировать реальные вероятности?»
Однако точная оценка вероятности чрезвычайно ценна с точки зрения бизнеса (иногда она даже ценнее погрешности). Хотите пример?
Представьте, что ваша компания продает два вида кружек: обычные белые кружки и кружки с котятами. Вам нужно решить, какую из кружек показать клиенту. Для этого нужно предсказать вероятность того, что пользовать может купить ту или другую кружку. Вы обучили пару моделей и у вас есть следующие результаты:
Возможно я плохо искал, но я не смог найти подробного руководства по созданию бота на python с применением фреймворка Django и подхода webhook, работающего на хостинге от российской компании. В большинстве материалов говориться о применении фреймворка Flask и использования бесплатных хостингов Heroku и PythonAnywhere. Опыт сообщества Хабр меня выручает, поэтому я решил в знак благодарности потратить время на написание данной статьи. Опишу полученный практический опыт, чтобы дать возможность всем кто в этом заинтересован сэкономить время и лучше понять как сделать бота на Python с применением фреймворка Django на своём хостинге, используя подход webhook.
Я не люблю читать книжные рейтинги по двум причинам. Во-первых, чаще всего они представляют собой список книг, отобранных неведомым автором по неведомым критериям. Во-вторых, описания книг больше напоминают рекламные тексты издательств, которым сложно верить.
Из-за этого большинство подобных материалов мало полезны, несмотря на то, что могут содержать толковые книги. Мне давно хотелось написать полезный обзор, который не станет навязывать определенные материалы, а позволит читателю выбрать наиболее подходящие.
Меня зовут Рушан, и я автор Telegram‑канала Нейрон. Не забудьте поделиться с коллегами или просто с теми, кому интересны такие статьи. Представляю пост который идёт строго (!) в закладки и передаётся коллегам. Он с подборкой примечательных файлов формата Jupyter Notebook по Machine Learning, Data Science и другим сферам, связанным с анализом данных. Эти блокноты Jupyter, будут наиболее полезны специалистам по анализу данных — как обучающимся новичкам, так и практикующим профи.
Вопрос расчёта lifetime value (он же LTV, customer lifetime value, CLV) рано или поздно встаёт перед разработчиками мобильных (впрочем, и не только) приложений. Методов расчёта придумано множество, и по поводу того, как считать LTV, существует сколько людей, столько же и мнений. В данном материале я решил описать наиболее распространённые методы, обозначить их плюсы и минусы. Данные методы подходят прежде всего для описания f2p-модели.
Курсы по анализу данных в CS центре читает Вадим Леонардович Аббакумов — кандидат физ.-мат. наук, он работает главным экспертом-аналитиком в компании Газпромнефть-Альтернативное топливо.
Лекции предназначены для двух категорий слушателей. Первая — начинающие аналитики, которым сложно начинать с изучения, например, книги The Elements of Statistical Learning. Курс подготовит их к дальнейшей работе. Вторая — опытные аналитики, не получившие систематического образования в области анализа данных. Они могут заполнить пробелы в знаниях. С прошлого года на занятиях используется язык программирования Python.
Чтобы понимать материал, достаточно когда-то прослушанных курсов математического анализа, линейной алгебры и теории вероятностей и базовых знаний языка Python.