Для личных нужд я использую bare-metal сервер от Hetzner, порезанный на виртуалки и, с недавних времен, VPS на HostHatch для мониторинга и резервирования. Также есть маленькая ВМка у TietoKettu (для ВПН, экспериментов и прочее).
Так как IPv4-адресов мало, то хостинги обычно дают дополнительные айпишки за дополнительные деньги, а вот IPv6-сети выделяют щедро. Изначально, я объединил все виртуалки, у которых был публичный IPv4-адрес в Wireguard mesh сеть, но потом когда выяснилось, что надо бы присоединить ещё одну ВМку, пришлось переделать mesh на IPv6-адреса и тут понеслось...
Сначала выяснилось что у HostHatch нет связности с ElmoNet (TietoKettu использует их адреса), после недели-двух бодания с техподдержкой HostHatch-a связность появилась. Однако недели две назад от них приходит письмо, о техобслуживании нод, где живут мои ВМки. И что вы думаете? После обслуживания туннель до этих ВМок так и не восстановился. В итоге, оказалось что обе вмки исчезли их IPv6-интернета. На этот раз связность починили только через 3 дня, хотя я создал срочный тикет.
В итоге, я перевёл туннели обратно на IPv4 и переключился на DN42, но в один выходной мне на глаза попалась статья на Reddit и я решил воскресить идею о "своем" куске Интернета. Масла в огонь подбавил Vultr, который наглухо заблокировал доступ на свои ресурсы (даже IP calculator) с Hetzner.
В одном из комментов, к вышеупомянутой статье, была ссылка на IPv6-сообщество в Discord. Я присоединился и стал задавать много вопросов в канале #asn-newbies.
Думаю, что кому-нибудь мой опыт и набитые шишки будет полезен. Если это так, то прошу под кат.









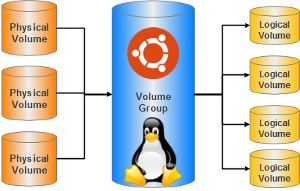 Классические разделы, на которые чаще всего разбивается жёсткий диск для установки системы и хранения данных, имею ряд существенных недостатков. Их размер очень сложно изменять, они находятся в строгой последовательности и просто взять кусочек от первого раздела и добавить к последнему не получится, если между ними есть ещё разделы. Поэтому очень часто при начальном разбиении винчестера пользователи ломают себе голову — сколько места выделить под тот или иной раздел. И почти всегда в процессе использования системы приходят к выводу, что они сделали не правильный выбор.
Классические разделы, на которые чаще всего разбивается жёсткий диск для установки системы и хранения данных, имею ряд существенных недостатков. Их размер очень сложно изменять, они находятся в строгой последовательности и просто взять кусочек от первого раздела и добавить к последнему не получится, если между ними есть ещё разделы. Поэтому очень часто при начальном разбиении винчестера пользователи ломают себе голову — сколько места выделить под тот или иной раздел. И почти всегда в процессе использования системы приходят к выводу, что они сделали не правильный выбор.