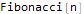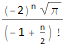«Во всякой вещи скрыт узор, который есть часть Вселенной. В нём есть симметрия, элегантность и красота — качества, которые прежде всего схватывает всякий истинный художник, запечатлевающий мир. Этот узор можно уловить в смене сезонов, в том, как струится по склону песок, в перепутанных ветвях креозотового кустарника, в узоре его листа.
Мы пытаемся скопировать этот узор в нашей жизни и нашем обществе и потому любим ритм, песню, танец, различные радующие и утешающие нас формы. Однако можно разглядеть и опасность, таящуюся в поиске абсолютного совершенства, ибо очевидно, что совершенный узор — неизменен. И, приближаясь к совершенству, всё сущее идёт к смерти» — Дюна (1965)
Я считаю, что концепция вложений (embeddings) — одна из самых замечательных идей в машинном обучении. Если вы когда-нибудь использовали Siri, Google Assistant, Alexa, Google Translate или даже клавиатуру смартфона с предсказанием следующего слова, то уже работали с моделью обработки естественного языка на основе вложений. За последние десятилетия произошло значительное развитие этой концепции для нейронных моделей (последние разработки включают контекстуализированные вложения слов в передовых моделях, таких как BERT и GPT2).








 Скачать файл с кодом и данные можно в
Скачать файл с кодом и данные можно в