Уже несколько лет я пользуюсь облигациями в качестве замены депозита, потому что процент дохода, который можно получить со вклада стабильно падает. В отличии от ситуации с депозитом, в облигациях всегда можно найти большую доходность. И в этой ситуации меня не устраивало только количество времени на механическую работу по поиску подходящих вариантов бумаг.
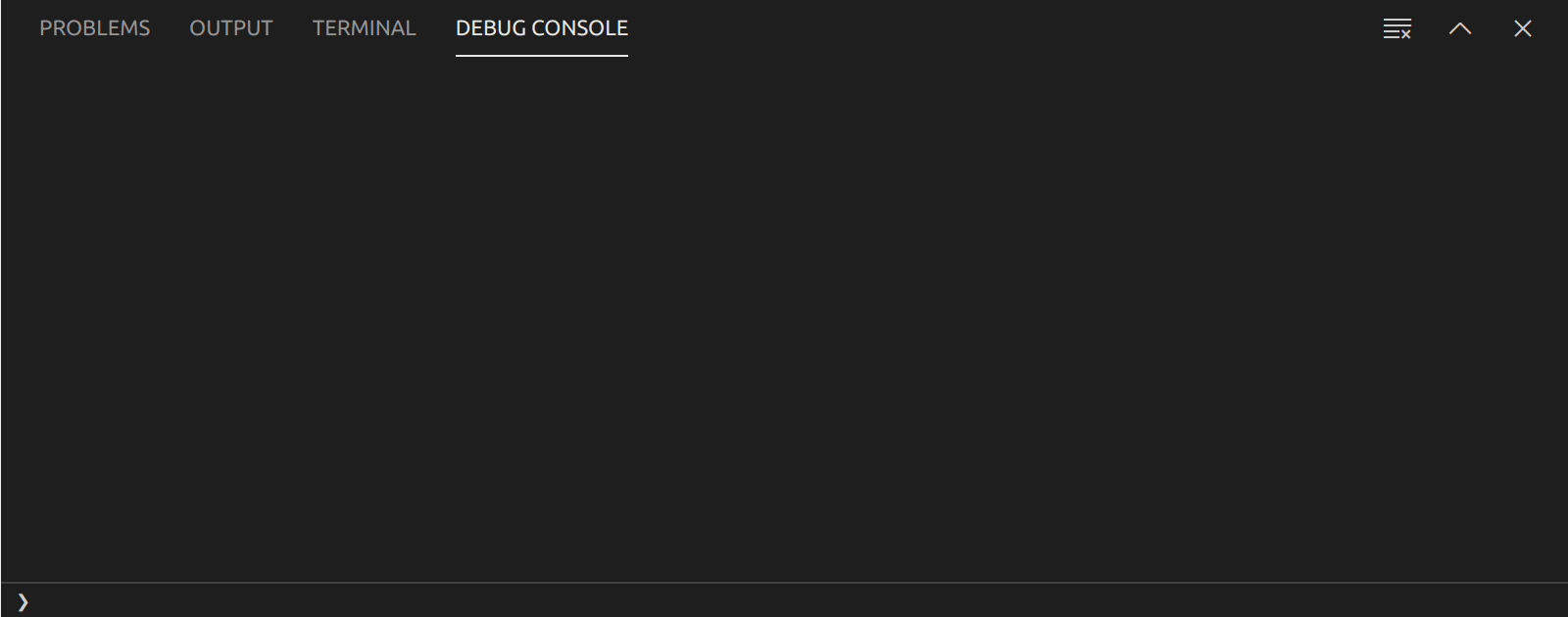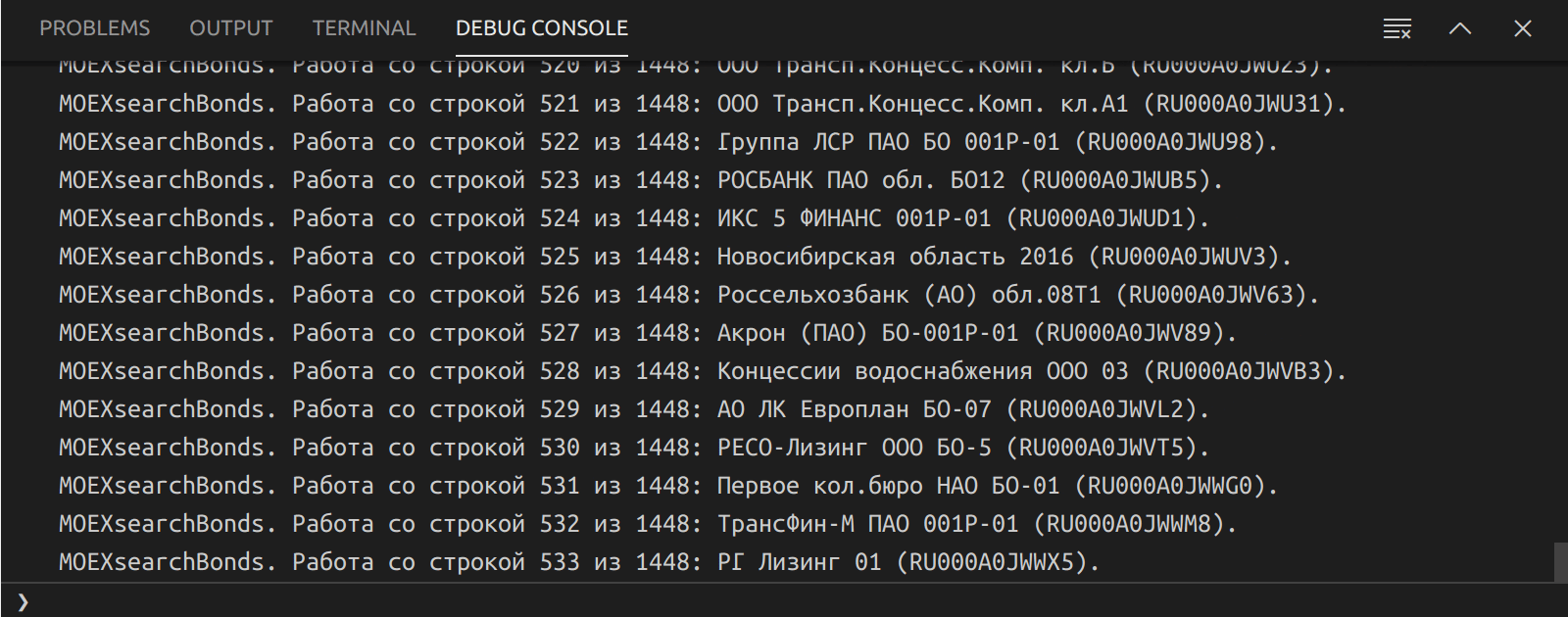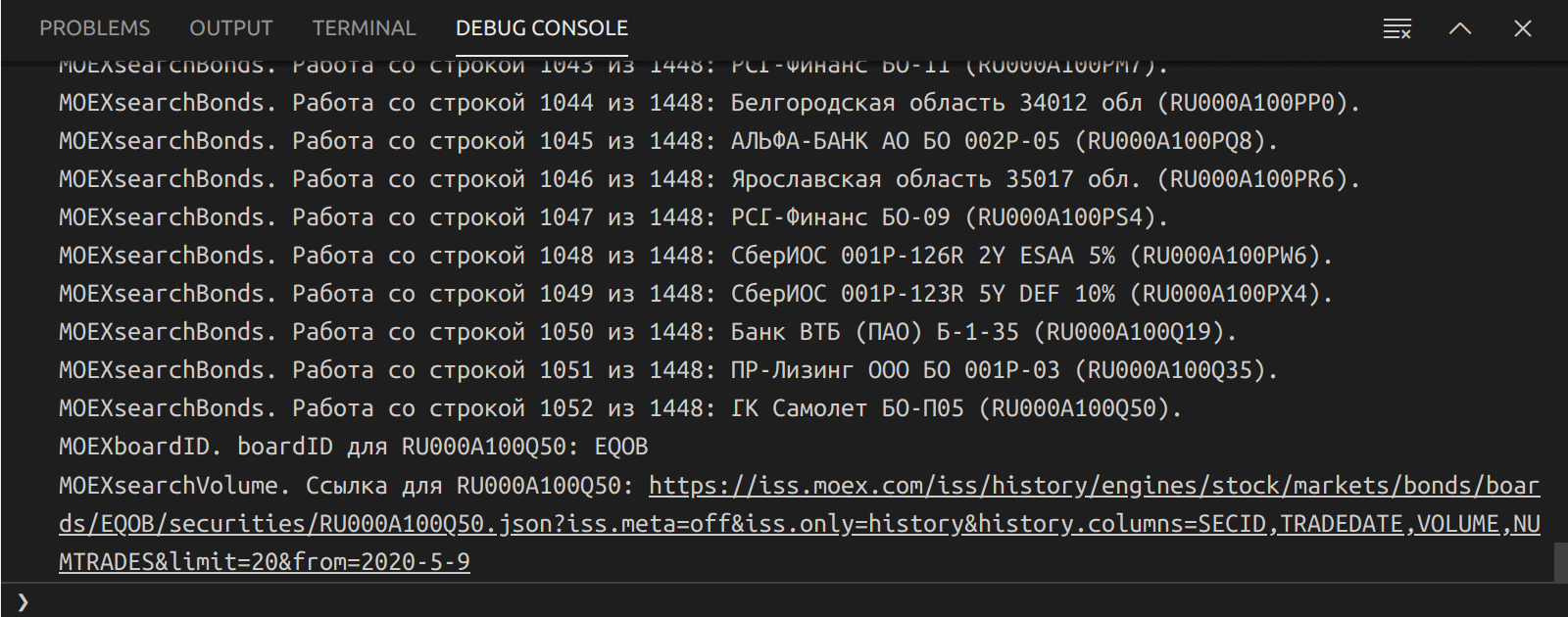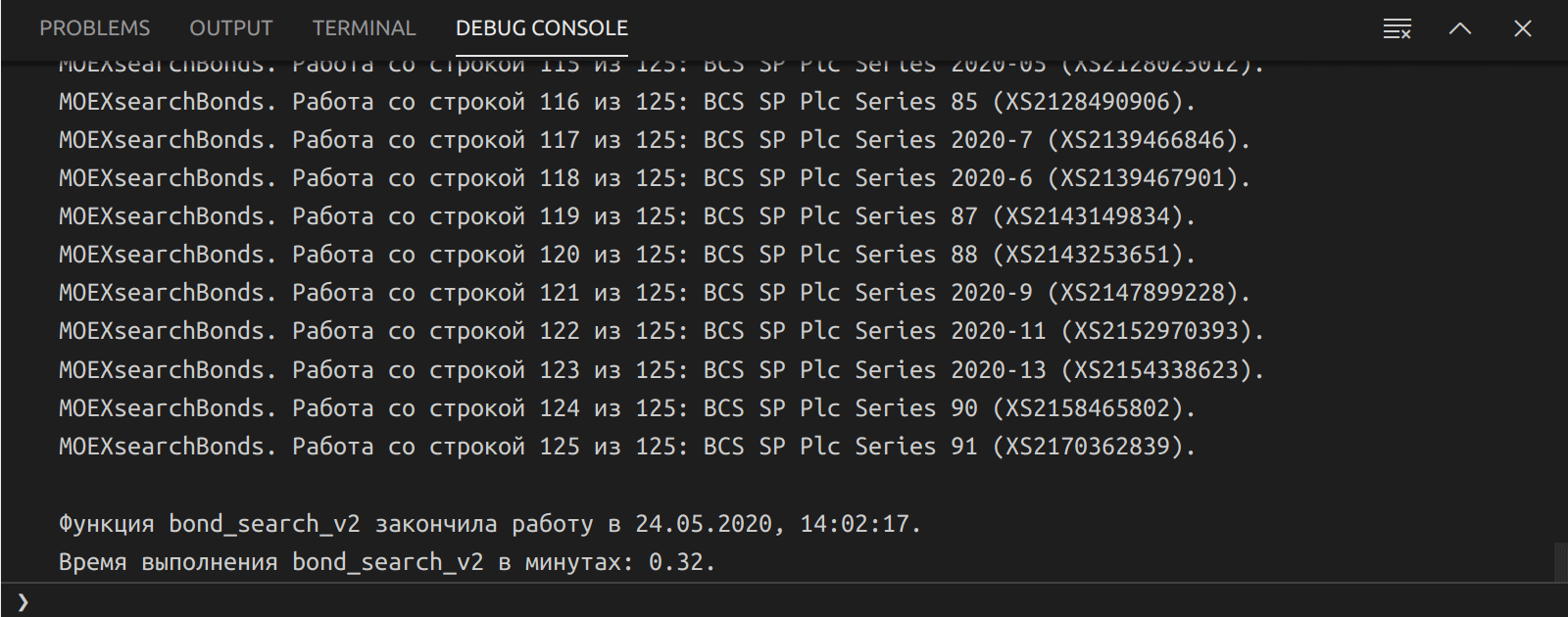
Работа скрипта по поиску облигаций на Московской бирже
Так как сервисов по поиску российских облигаций много, но ни один из них не имеет достаточной гибкости и простоты и поэтому на работу с ними тратится достаточно много времени. Исходя из этого и решил разработать собственный скрипт для поиска облигаций.
Сделал это на Node.js с выводом полученных результатов в локальный html файл с интерактивной таблицей от Google Charts (а в случае, если JavaScript отключен в браузере, что например происходит при открытии этого html файла из мессенджера на iPhone, то отображается статическая версия таблицы, также сгенерированная скриптом).
Работа скрипта по поиску облигаций на Московской бирже
Так как сервисов по поиску российских облигаций много, но ни один из них не имеет достаточной гибкости и простоты и поэтому на работу с ними тратится достаточно много времени. Исходя из этого и решил разработать собственный скрипт для поиска облигаций.
Сделал это на Node.js с выводом полученных результатов в локальный html файл с интерактивной таблицей от Google Charts (а в случае, если JavaScript отключен в браузере, что например происходит при открытии этого html файла из мессенджера на iPhone, то отображается статическая версия таблицы, также сгенерированная скриптом).






 Экосистема языка python стремительно развивается. Это уже не просто язык общего назначения. С его помощью можно успешно разрабатывать веб-приложения, системные утилиты и много другое. В этой заметке мы сконцентрируемся все же на другом приложении, а именно на научных вычислениях. Я хотел бы поделиться своим опытом в данной теме.
Экосистема языка python стремительно развивается. Это уже не просто язык общего назначения. С его помощью можно успешно разрабатывать веб-приложения, системные утилиты и много другое. В этой заметке мы сконцентрируемся все же на другом приложении, а именно на научных вычислениях. Я хотел бы поделиться своим опытом в данной теме.