
Большая подборка для аналитиков данных, продуктовых аналитиков, веб аналитиков, маркетинговых аналитиков и особенно тех, кто хочет ими стать. От автора Telegram-канала «Аналитика и Growth mind-set».
Но прежде несколько важных моментов:

Пользователь
Большая подборка для аналитиков данных, продуктовых аналитиков, веб аналитиков, маркетинговых аналитиков и особенно тех, кто хочет ими стать. От автора Telegram-канала «Аналитика и Growth mind-set».
Но прежде несколько важных моментов:
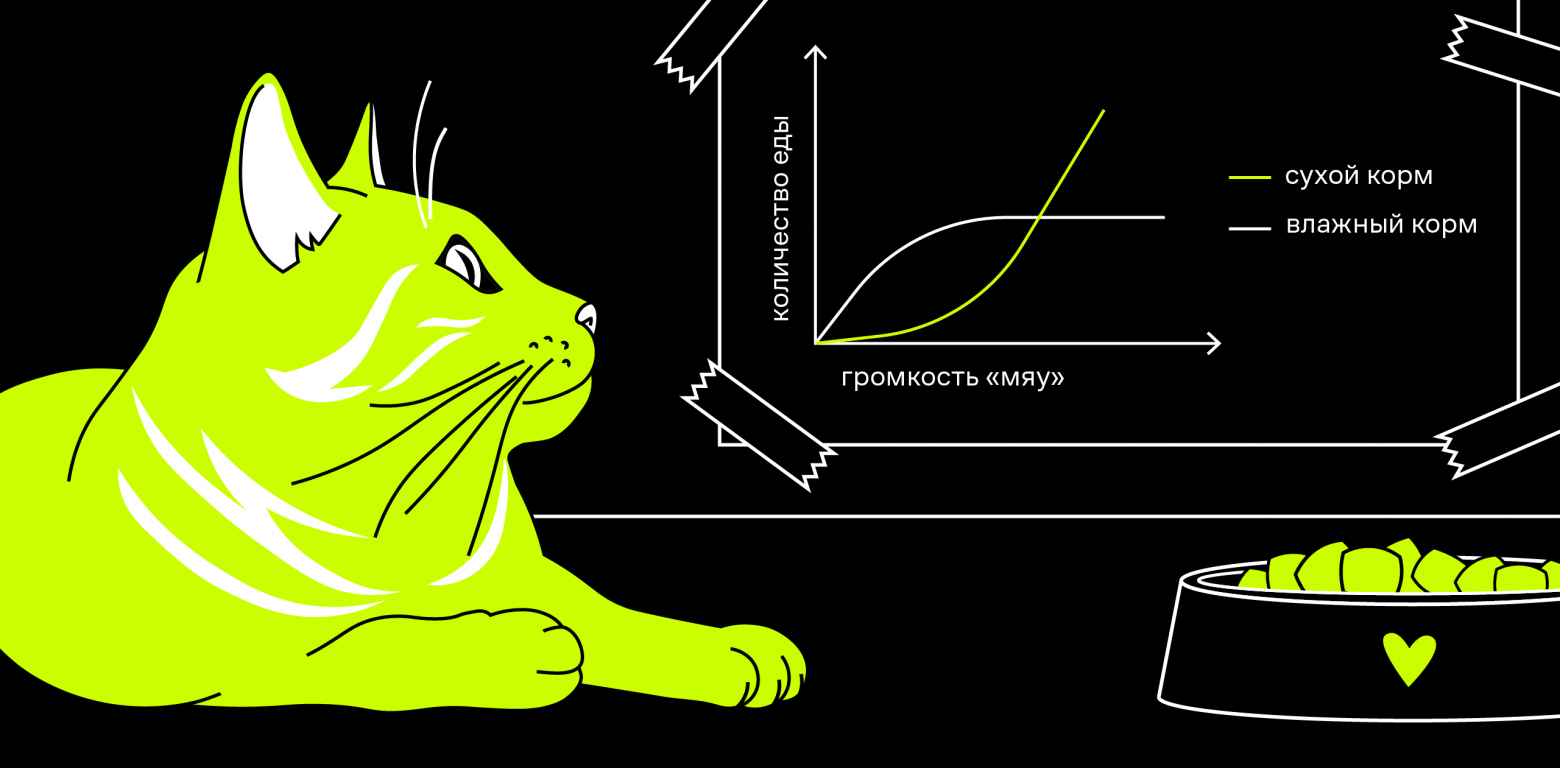
Привет, Хабр. В этой статье я расскажу про своё видение работы с цветом при визуализации графиков. Буду показывать все на примерах — уверен, они вам понравятся.
Я покажу не только картинки было-стало, но и приведу примеры кода, а также объясню логику принятия решений: как использовать ту или иную палитру в конкретной задаче. И что самое главное, дам пошаговые советы, как сделать график логичнее и понятнее для заказчиков.
Меня зовут Саша, сейчас я работаю в Lamoda Tech старшим бизнес/дата-аналитиком. До этого я несколько лет был специалистом по данным в другой компании и регулярно представлял совету директоров анализ и прогноз физических и бизнес-показателей. Умение донести результаты исследования до заказчика, особенно если он не погружен в работу с данными — это важный аспект моей профессии. Надеюсь, моя статья с этим немного поможет.

Метод опорных векторов (Support Vector Machines или просто SVM) — мощный и универсальный набор алгоритмов для работы с данными любой формы, применяемый не только для задач классификации и регрессии, но и также для выявления аномалий. В данной статье будут рассмотрены основные подходы к созданию SVM, принцип работы, а также реализации с нуля его наиболее популярных разновидностей.

Благодаря недавнему релизу spark3.2.0 у нас появилась возможность масштабировать данные с помощью pandas.

Уважаемые читатели, рад вас приветствовать в новой статье. Этот материал является продолжением предыдущей публикации, посвященной замыканиям. В данной части обзора мы углубимся в тему декораторов.
Эта статья написана в первую очередь для тех, кто только начинает свой путь в программировании или начал изучать Python. Потому здесь я не буду рассматривать декораторы классов, чтобы сделать материал более доступным для новичков. Тем не менее, для тех, кто изучит данную статью, не составит труда разобраться в декораторах классов, так как они не имеют существенных отличий от рассматриваемых здесь декораторов функций.


Ну вот и пришла пора погрузиться в недра asyncio и подробнее познакомиться с циклом событий. С его помощью мы научимся писать собственные асинхронные веб-серверы, создавать асинхронные драйверы внешних устройств и справляться с вычислительно-затратными задачами в асинхронных приложениях.
За то время что я занимаюсь менторством я заметил, что большинство вопросов новичков связаны с темами: конкурентность, параллелизм, асинхронность. Подобные вопросы часто задают на собеседованиях, в работе эти знания позволяют писать более эффективные и производительные системы.
Цель статьи - понятно и доходчиво, используя примеры кода и бенчмарки рассказать о том какие инструменты есть в Python и как с их помощью добиться высокой производительности.

Публикуем перевод гайда по Spark UI. Это встроенный инструмент Apache Spark, который предоставляет полный обзор среды Spark: узлов, исполнителей, свойств и параметров среды, выполняемых заданий, планов запросов и многого другого. Кроме теории в статье вы найдёте несколько примеров, которые помогут попрактиковаться в отслеживании и анализе заданий Spark.

Раскрывать тему параллельного или асинхронного программирования непросто. Во-первых, она перегружена терминологией и трудна для понимания. Как правило, тонкости и особенности работы с языками усваиваются, лишь когда столкнешься с ними на практике. Во-вторых, в контексте Python тоже много своих подводных камней. Но сегодня почти любой современный web-сервис сталкивается с необходимостью многопоточности или асинхронности. Поскольку это многопользовательская среда, мы хотим направить всю процессорную мощность не на ожидание, а на решение прикладных задач бизнеса, чтобы все пользователи во время получили необходимые данные.
Эта статья будет полезна тем разработчикам, которые хотят выполнять больше работы за одно и то же время и задействовать все ресурсы своего железа. Проще говоря, делать больше при этом обходиться меньшими ресурсами. Пусть железо работает, а не простаивает.


Об обработке текстов на естественном языке сейчас знают все. Все хоть раз пробовали задавать вопрос Сири или Алисе, пользовались Grammarly (это не реклама), пробовали генераторы стихов, текстов... или просто вводили запрос в Google. Да, вот так просто. На самом деле Google понимаетот него хотите, благодаря ш, что вы тукам, которые умеют обрабатывать и анализировать естественную речь в вашем запросе.
При анализе текста мы можем столкнуться с ситуациями, когда текст содержит специфические символы, которые необходимо проанализировать наравне с "простым текстом" или формулы, например. В таком случае обработка текста может усложниться.
Вы можете заметить, что если ввести в поисковую строку запрос с символами с ударением (так называемый модифицирующий акут), к примеру "ó", поисковая система может показать результаты, содержащие слова из вашего запроса, символы с ударением уже выглядят как обычные символы.
Так как всё-таки происходит обработка таких запросов?

Привет! В последние годы аналитика данных переживает настоящий бум. Все большее количество компаний принимают решение сбора, хранения и анализа данных, чтобы повысить эффективность своих бизнес-процессов и принимать решения на основе фактов.
Одним из наиболее важных инструментов в аналитике данных является анализ временных рядов. Временной ряд - это последовательность наблюдений за определенным параметром в разные моменты времени. Таким образом, временной ряд содержит информацию о том, как изменяется параметр со временем.

Python — один из самых популярных языков программирования в мире. Статистика современного рынка свидетельствует о том, что Python желаемый навык, и что его использование широко распространено в различных сферах, таких как наука, инженерия, бизнес, аналитика данных и многих других.
В этой статье я составил полную дорожную карту для изучения Python, прилагая полезные источники знаний.
Собрал в одно месте все самое нужное и популярное. Для тех, кто больше любит посмотреть, чем почитать, в конце прикрепил ссылку, где можно посмотреть ролики авторов, которые очень подробно обо всем рассказывают. Пользуйтесь на здоровье =)
prompt для этих ИИ будут фактически одинаковым, как и для других похожих сервисов.
Многие студенты колледжей в России в этом году будут обязаны сдать демо-экзамен по дисциплине, посвящённой изучению темы машинного обучения, но качество обучения в учебном заведении может страдать в силу малого количества опыта в вопросе проведения подобного рода тестирования. В силу данного обстоятельства студенты в поисках материала для подготовки обращаются к помощи интернет ресурсов, но с ужасом обнаруживают, что информация не такая структуризированная, как было бы удобно экзаменуемым.
Меня тоже коснулась эта проблема, поэтому я решил написать статью, объясняющую принципы работы с необходимыми инструментами для сдачи демонстративного экзамена.

Вы провели опрос клиентского опыта в вашей компании. В данном случае на каждый вопрос клиенты отвечали по 10 бальной шкале, где 1 - совсем неудовлетворен, а 10 - полностью удовлетворен. Вопросы разбиты на несколько тематических блоков. В начале блок основных вопросов:

Привет, Хабр! На связи снова Юрий Кацер, эксперт по ML и анализу данных в промышленности, а также руководитель направления предиктивной аналитики в компании «Цифрум» Госкорпорации “Росатом”.
До сих пор рамках рабочих обязанностей решаю задачи поиска аномалий, прогнозирования, определения остаточного ресурса и другие задачи машинного обучения в промышленности. В рамках рабочих задач мне приходится часто сталкиваться с проблемой правильной оценки качества решения задачи, и, в частности, выбора правильной data science метрики в задачах обнаружения аномалий.
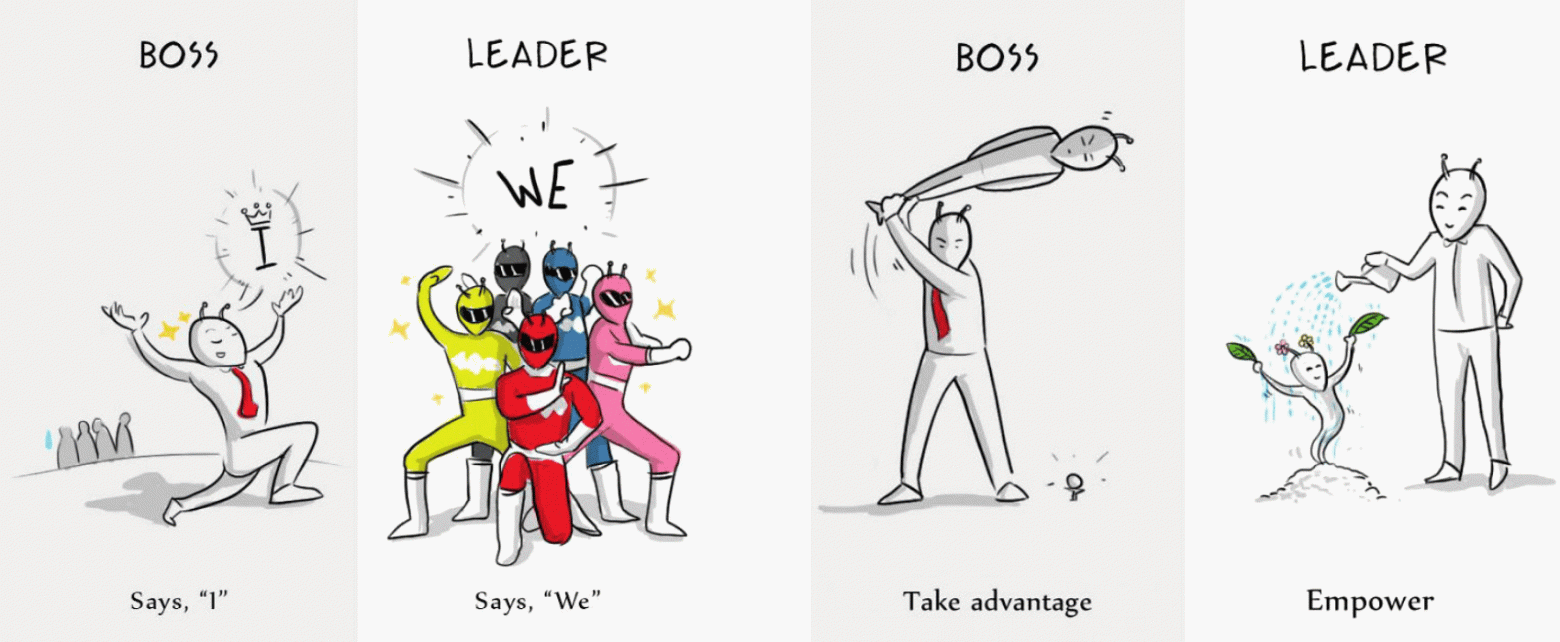
Уже более 5 лет я занимаю руководящие позиции в области анализа данных. От синьора DS с двумя подчиненными до лида трех команд аналитиков и инженеров в Малом бизнесе Сбера. За это время я сформировал приципы, которые помогают мне в управлении творческими специалистами.
Не претендую на истину, да и не всему всегда получается следовать. Принципы не отражают всех задач менеджера, а относятся к конкретным вопросам. Делюсь с вами своим опытом, буду рад услышать ваше мнение.

Оператор Join позволяет коррелировать, обогащать и фильтровать два входных набора (пакета / блока) данных (Datasets).Обычно два входных набора данных классифицируются как левый и правый на основе их расположения по отношению к пункту/оператору Join.По сути, соединение работает на основе условного оператора, который включает логическое выражение, основанное на сравнении между левым ключом, полученным из записи левого блока данных, и правым ключом, полученным из записи правого комплекса данных. Левый и правый ключи обычно называются соединительными ключами (Join Keys). Логическое выражение оценивается для каждой пары записей из двух входных наборов данных. На основе логического вывода, полученного в результате оценки выражения, условный оператор включает условие выбора — для отбора либо одной из записей (из пары), либо комбинированной записи (из записей, образующих пару).