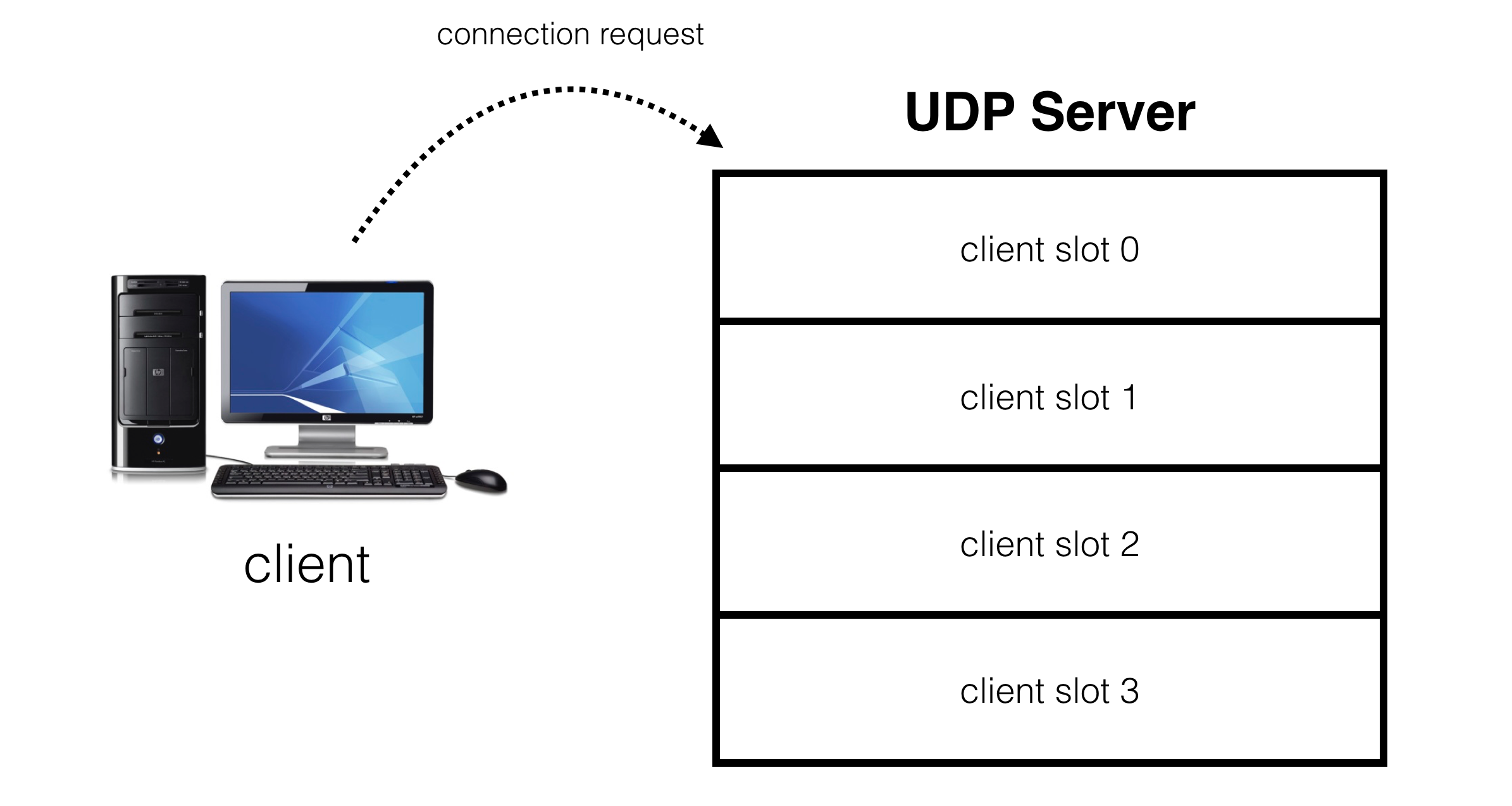
Привет, Хабр! Меня зовут Кирилл Колодяжный, я ведущий инженер-программист в YADRO. Помимо основных рабочих задач, включающих исследование проблем производительности СХД, я увлекаюсь машинным обучением. Участвовал в коммерческих проектах, связанных с техническим зрением, 3D-сканерами и обработкой фотографий. В задачах часто использовал С++, хотя машинное обучение традиционно ассоциируется с Python. Этот язык программирования буквально захватил сферу, его используют повсюду — от обучающих курсов до серьезных ML-проектов.
Однако Python — не единственный язык, на котором можно решать задачи машинного обучения. Так, альтернативой может стать С++. Если последний вам ближе, вам будет интересен и полезен этот текст.
Под катом разберемся:
• как организовать работу с данными и загрузку обучающего датасета,
• как описать структуру нейронной сети,
• как использовать уже готовые алгоритмы машинного обучения из доступных библиотек и фреймворков,
• как организовать конвейер обучения сети,
• как использовать предобученные глубокие сети для решения задач.









 методики FAANG — по этой причине практически во всех IT-собесах есть она: секция алгоритмов. Кто-то ей рад, кто-то не очень, но секция есть и уходить пока не планирует. Поэтому нужно закатать рукава и достойно встретить суровую реальность.
методики FAANG — по этой причине практически во всех IT-собесах есть она: секция алгоритмов. Кто-то ей рад, кто-то не очень, но секция есть и уходить пока не планирует. Поэтому нужно закатать рукава и достойно встретить суровую реальность.
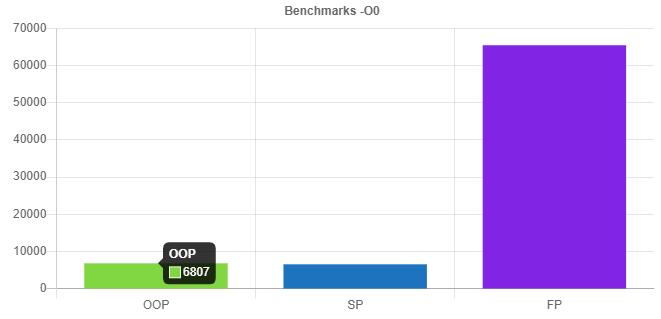

»")