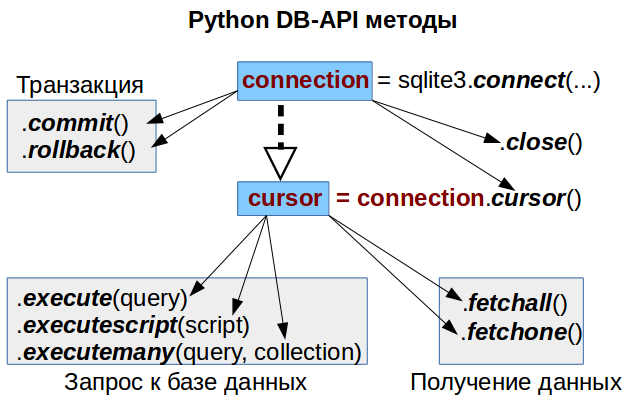
Это конспект лекции Татьяны Денисовой tdenisova — бэкенд-разработчика в Яндекс.Учебнике. Вы узнаете, какие бывают базы данных, какие их особенности важно помнить, как в работе с данными учитывать характеристики системы и планы масштабирования, в какую из тем нужно углубиться для решения конкретной задачи. А также как при возникновении багов определить, является ли работа с БД источником проблемы (и если да, то в какую сторону копать).
— О чем именно мы будем говорить? Не о примитивных селектах и джойнах — о них, я думаю, большинство из вас уже знает.
— О чем именно мы будем говорить? Не о примитивных селектах и джойнах — о них, я думаю, большинство из вас уже знает.

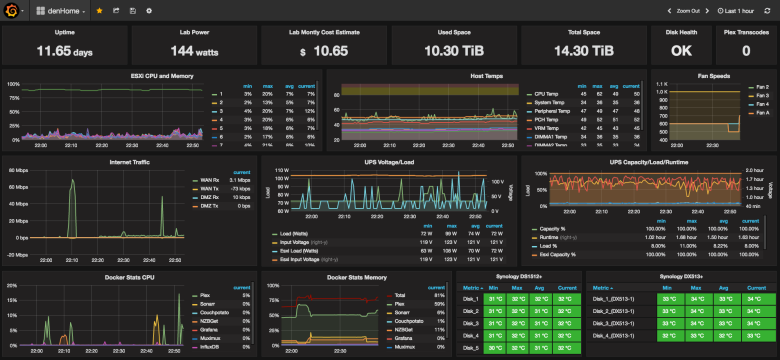
 Существует ли в мире очень большая и крупная база данных, которая время от времени не страдает от проблем с производительностью? Держу пари, что их не так уж много. Поэтому каждый DBA (администратор базы данных), отвечающий за PostgreSQL, должен знать, как отслеживать потенциальные проблемы производительности, чтобы выяснить, что на самом деле происходит.
Существует ли в мире очень большая и крупная база данных, которая время от времени не страдает от проблем с производительностью? Держу пари, что их не так уж много. Поэтому каждый DBA (администратор базы данных), отвечающий за PostgreSQL, должен знать, как отслеживать потенциальные проблемы производительности, чтобы выяснить, что на самом деле происходит.