Всем привет! Меня зовут Александр Токарев, я технический архитектор домена «Управление данными» в «Леруа Мерлен». Год назад мы уже делали обзор нашей Платформы данных, сейчас же я расскажу про её развитие за последний год и про задачи, которые нам удалось решить.
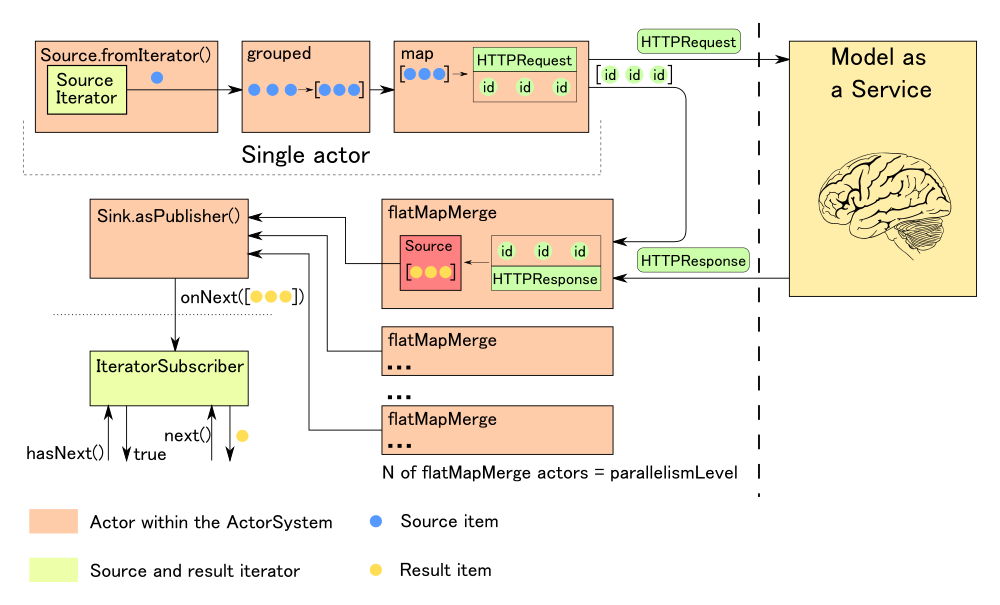
Мы столкнулись с необходимостью масштабировать наш подход, когда количество источников, интегрированных в платформу, стало больше 150. Всего же мы планируем интегрировать данные из более чем 800 систем. Однако ETL-инструменты, которые мы использовали на первых этапах развития дата платформы, не позволяли добиться эффективного масштабирования. Кроме того, сам процесс интеграции источников был достаточно трудоемким. Поэтому возник запрос на рефакторинг архитектуры процесса поставки данных, который, с одной стороны, позволил бы эффективно горизонтально масштабироваться, а с другой стороны, упростил бы сам процесс интеграции. В результате мы пришли к следующей схеме процесса.