
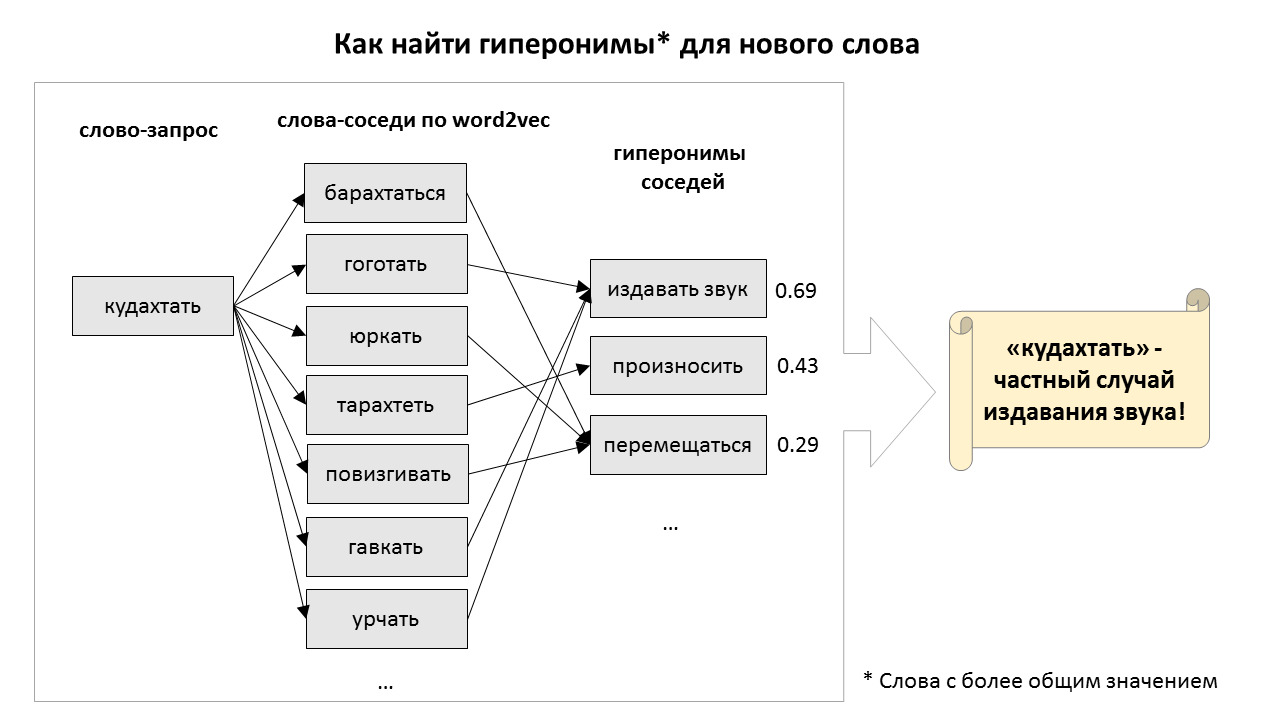
Как может машина понимать смысл слов и понятий, и вообще, что значит — понимать? Понимаете ли вы, например, что такое спаржа? Если вы скажете мне, что спаржа — это (1) травянистое растение, (2) съедобный овощ, и (3) сельскохозяйственная культура, то, наверное, я останусь убеждён, что вы действительно знакомы со спаржей. Лингвисты называют такие более общие понятия гиперонимами, и они довольно полезны для ИИ. Например, зная, что я не люблю овощи, робот-официант не стал бы предлагать мне блюда из спаржи. Но чтобы использовать подобные знания, надо сначала откуда-то их добыть.
В этом году компьютерные лингвисты организовали соревнование по поиску гиперонимов для новых слов. Я тоже попробовал в нём поучаствовать. Нормально получилось собрать только довольно примитивный алгоритм, основанный на поиске ближайших соседей по эмбеддингам из word2vec. Однако этот простой алгоритм каким-то образом оказался наилучшим решением для поиска гиперонимов для глаголов. Послушать про него можно в записи моего выступления, а если вы предпочитаете читать, то добро пожаловать под кат.





 Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.  Из этой статьи читатель узнает о том, как написать робота, проходящего тесты, и немножко «разомнет мозги» в теории вероятностей, разбираясь вместе с автором, почему при кажущейся сложности задачи автоматический подбор решения сходится за очень короткое время. Предупреждение: половина статьи ― «матан».
Из этой статьи читатель узнает о том, как написать робота, проходящего тесты, и немножко «разомнет мозги» в теории вероятностей, разбираясь вместе с автором, почему при кажущейся сложности задачи автоматический подбор решения сходится за очень короткое время. Предупреждение: половина статьи ― «матан».









