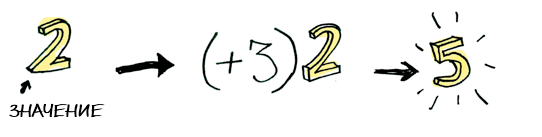Для надежной поточной обработки данных в реальном времени и принятия решений на основе анализа данных из внешнего источника нужно обеспечить организацию конвейера обработки и хранения данных, который может быть кластеризирован и распараллелен для достижения необходимой производительности и отказоустойчивости. Кроме того, нужно обеспечить механизм своевременной доставки обновленных данных (на основе периодического опроса или использования Web Sockets/SSE) в систему анализа, которая также должна иметь доступ к истории изменений (например, для анализа тренда или получения усредненных значений по временному окну). В этой статье мы поговорим про использование Apache Kafka совместно с Hazelcast для анализа данных в реальном времени, а также разработаем коннектор для Kafka Connect для извлечения данных из внешнего источника (на примере WeatherStack API)