В данной статье будет рассмотрено понятие сокета в операционной системе Linux: основные структуры данных, как они работают и можно ли управлять состоянием сокета с помощью приложения. В качестве практики будут рассмотрены инструменты netcat и socat.

Пользователь
Дизассемблируем циклы, написанные на Си
4 мин
Туториал

Доброго времени суток.
Сегодня мы будем смотреть дизассемблированный код инструкций if, for, while, swich, которые написаны на языке Си. Воспользуемся radare2.
Intel Architecture Code Analyzer 2.0.1
2 мин
Мои потребности в анализе производительности софта на x86 покрывают три тула. Один из них — Vtune XE знаком, наверное, всем, кто сталкивался с оптимизацией.
Второй тул, к сожалению, не столь широко известнен. Он уже упоминался на Хабре в контексте оптимизации AVX кода, но область его применения несколько шире.
Иногда после того, как Vtune нашел самый главный хотспот (а зачастую, разработчик и так его знает), возникает потребность приложить некоторые усилия для уменьшения числа тактов, которые тратятся на его исполнение. Уже почти три года я использую для анализа производительности таких небольших, но критичных участков кода Intel Architecture Code Analyzer.
Пользоваться им просто, вот рекурсивный алгоритм всего лишь из 6 шагов:
1. В соответствующем .c/.cpp файле включается
#include «iacaMarks.h»,
2. dll/so библиотеки IACA кладутся в доступное системе место,
3. в исходник добавляются макросы
IACA_START, IACA_END
соответственно, перед началом и после окончания оптимизируемого кода. Например,
Второй тул, к сожалению, не столь широко известнен. Он уже упоминался на Хабре в контексте оптимизации AVX кода, но область его применения несколько шире.
Иногда после того, как Vtune нашел самый главный хотспот (а зачастую, разработчик и так его знает), возникает потребность приложить некоторые усилия для уменьшения числа тактов, которые тратятся на его исполнение. Уже почти три года я использую для анализа производительности таких небольших, но критичных участков кода Intel Architecture Code Analyzer.
Пользоваться им просто, вот рекурсивный алгоритм всего лишь из 6 шагов:
1. В соответствующем .c/.cpp файле включается
#include «iacaMarks.h»,
2. dll/so библиотеки IACA кладутся в доступное системе место,
3. в исходник добавляются макросы
IACA_START, IACA_END
соответственно, перед началом и после окончания оптимизируемого кода. Например,
Действительно ли у каждого ядра есть «свой собственный» кэш первого и второго уровней?
6 мин
У современных процессоров архитектуры Core i7 существует очевидный, документированный, но отчего-то не очень известный даже среди многих специалистов сценарий priority inversion. Его я опишу в этом посте. В нем есть код на С, три диаграммы, и некоторые подробности работы кэшей в процессорах архитектуры Core i7. Никаких покровов не срывается, вся информация давно общедоступна.
Priority inversion – ситуация, когда низкоприоритетный процесс может блокировать или замедлять высокоприоритетный. Обычно имеется в виду очередность доступа к исполнению на ядре для высокоприоритетного кода относительно низкоприоритетного. С этим должно неплохо справляться ядро ОС. Однако помимо вычислительных ядер, которые несложно распределять посредством affinity и MSI-X, в процессоре есть ресурсы, общие для всех задач – контроллер памяти, QPI, общий кэш третьего уровня, PCIe устройства. В вопросы PCIe я углубляться не буду, т.к. не являюсь экспертом в данной теме. Priority inversion на почве доступа к памяти и QPI я давно не наблюдал – пропускной способности современного многоканального контроллера как правило хватает и высокоприоритетным, и низкоприоритетным задачам. Остановлюсь на кэшах.
Priority inversion – ситуация, когда низкоприоритетный процесс может блокировать или замедлять высокоприоритетный. Обычно имеется в виду очередность доступа к исполнению на ядре для высокоприоритетного кода относительно низкоприоритетного. С этим должно неплохо справляться ядро ОС. Однако помимо вычислительных ядер, которые несложно распределять посредством affinity и MSI-X, в процессоре есть ресурсы, общие для всех задач – контроллер памяти, QPI, общий кэш третьего уровня, PCIe устройства. В вопросы PCIe я углубляться не буду, т.к. не являюсь экспертом в данной теме. Priority inversion на почве доступа к памяти и QPI я давно не наблюдал – пропускной способности современного многоканального контроллера как правило хватает и высокоприоритетным, и низкоприоритетным задачам. Остановлюсь на кэшах.
Повышение производительности с использованием uop-кэша на Sandy Bridge+
15 мин
В современных x86 процессорах Intel конвеер можно разделить на 2 части: Front End и Back End.
Front End отвечает за загрузку кода из памяти и его декодирование в микрооперации.
Back End отвечает за выполнение микроопераций, пришедших от Front End. Поскольку эти микрооперации могут выполняться ядром не по порядку, то Back End также следит за тем, чтобы результат выполнения этих микроопераций строго соответствовал порядку в котором они идут в коде.
В большинстве случаев неэффективное использование Front End'a не оказывает заметного влияние на производительность. Пиковая пропускная способность на большинстве процессоров Intel — 4 микрооперации за такт, поэтому, например, для Memory/L3-bound кода ЦПУ не сможет полностью ее утилизировать.
Однако в некоторых случаях различие в производительности может быть достаточно существенно. Под катом — анализ влияния кэша микроопераций на производительность.
Front End отвечает за загрузку кода из памяти и его декодирование в микрооперации.
Back End отвечает за выполнение микроопераций, пришедших от Front End. Поскольку эти микрооперации могут выполняться ядром не по порядку, то Back End также следит за тем, чтобы результат выполнения этих микроопераций строго соответствовал порядку в котором они идут в коде.
В большинстве случаев неэффективное использование Front End'a не оказывает заметного влияние на производительность. Пиковая пропускная способность на большинстве процессоров Intel — 4 микрооперации за такт, поэтому, например, для Memory/L3-bound кода ЦПУ не сможет полностью ее утилизировать.
Про относительно новый Ice Lake
Если верить официальной документации, то пиковая пропускная способность у Ice Lake была увеличена с 4 до 5 микроопераций за такт. К сожалению, доступа к этой модели цпу у меня нет, поэтому убедиться в этом на практике не представляется возможным.
Однако в некоторых случаях различие в производительности может быть достаточно существенно. Под катом — анализ влияния кэша микроопераций на производительность.
Примитивно-рекурсивные функции и функция Аккермана
7 мин
Функция Аккермана — одна из самых знаменитых функций в Computer Science. С ней связан как минимум один фундаментальный результат и как минимум один просто важный. Фундаментальный результат, говоря аккуратно и непонятно, таков: существует всюду определённая вычислимая функция, не являющаяся примитивно-рекурсивной. Важный результат заключается в том, что лес непересекающихся множеств (также известный как disjoint set union) работает очень быстро.
Мне очень нравится изучать функцию Аккермана, т.к. всё, что с ней связано, очень красиво и изящно. Вот и записанный выше фундаментальный результат понять намного проще, чем это может показаться.
Из текста ниже вы узнаете, что такое примитивно-рекурсивные функции и как выяснить, что функция Аккермана к таковым не относится. И, конечно, этот текст убедит вас в том, что это невероятно красивая конструкция и невероятно красивое рассуждение!
Критерии простоты
4 мин
Львиная доля программистов с чистой совестью заявит, что предпочитает решать задачи просто, руководствуясь прежде всего здравым смыслом. Вот только это "просто" у каждого свое и как правило отличное от других. После одного долгого и неконструтивного спора с коллегой я решил изложить, что именно считаю простым сам и почему. Это не привело к немедленному согласию, но позволило понять логику друг друга и свести к минимуму лишние дискуссии.
Первый критерий
Особенности мозга человека таковы, что он плохо хранит и отличает более 7-9 элементов в одном списке при оптимальном их количестве 1-3.
Отсюда рекомендация — в идеале иметь не более трех членов в интерфейсе, трех параметров в методе и так далее и не допускать увеличение их количества свыше девяти.
Этот критерий может быть реализован средствами статического анализа.
Продолжения в Haskell
6 мин
Продолжение — это состояние программы в определённый момент, которое мы потом можем использовать, чтобы вернуться в то состояние.
С помощью продолжений можно реализовать обработку исключений, подобие goto и множество других вещей напоминающих императивные конструкции.
Также, используя продолжения можно улучшить производительность программы, убирая ненужные «обёртывания» и сопоставления с образцом.
В этой статье я расскажу, как можно реализовать продолжения в Haskell, и покажу несколько интересных функций работающих с ними.
С помощью продолжений можно реализовать обработку исключений, подобие goto и множество других вещей напоминающих императивные конструкции.
Также, используя продолжения можно улучшить производительность программы, убирая ненужные «обёртывания» и сопоставления с образцом.
В этой статье я расскажу, как можно реализовать продолжения в Haskell, и покажу несколько интересных функций работающих с ними.
Теория категорий позволяет математике отказаться от равенств
14 мин
Перевод
Две монументальных работы убедили многих математиков отказаться от знака равенства. Их цель – реконструировать основы дисциплины при помощи более слабого взаимоотношения – «эквивалентности». И этот процесс не всегда идёт гладко.
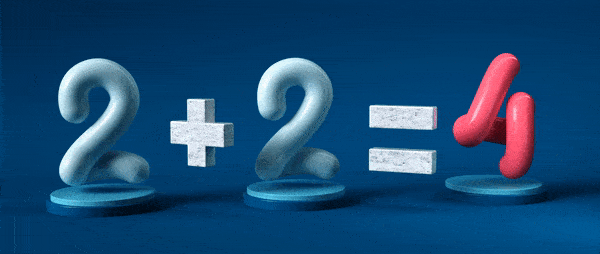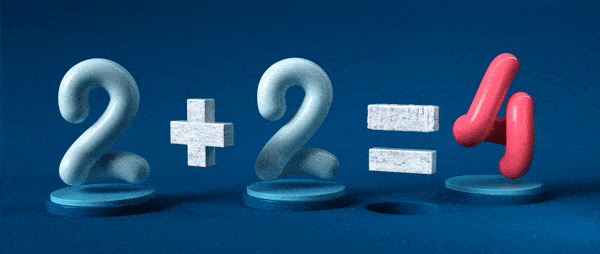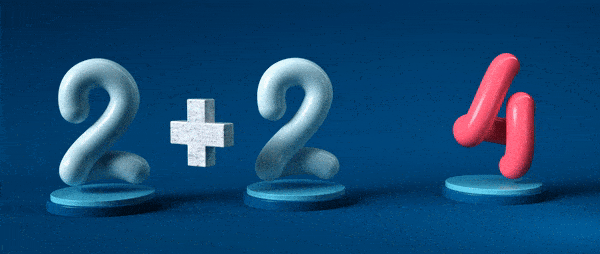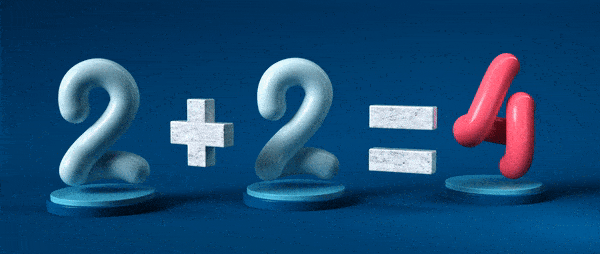
Знак равенства – краеугольный камень математики. Он, кажется, делает фундаментальное и непротиворечивое заявление: две этих сущности абсолютно одинаковы.
Однако ширится круг математиков, относящихся к знаку равенства, как к первоначальной ошибке математики. Они считают его внешним лоском, прячущим важные сложности взаимоотношения величин – сложности, способные открыть решения огромного количества задач. Они хотят реформировать математику, используя более свободный язык эквивалентности.
«Мы породили эту идею равенства, — сказал Джонатан Кэмпбелл из Университета Дьюка. – А на её месте должна была быть эквивалентность».
Коты в коробочках, или Компактные структуры данных
12 мин

Как быть, если дерево поиска разрослось на всю оперативку и вот-вот подопрет корнями соседние стойки в серверной? Что делать с инвертированным индексом, жадным до ресурсов? Завязывать ли с разработкой под Android, если пользователю прилетает «Память телефона заполнена», а приложение едва на половине загрузки важного контейнера?
В целом, можно ли сжать структуру данных, чтобы она занимала заметно меньше места, но не теряла присущих ей достоинств? Чтобы доступ к хэш-таблице оставался быстрым, а сбалансированное дерево сохраняло свои свойства. Да, можно! Для этого и появилось направление информатики «Succinct data structures», исследующее компактное представление структур данных. Оно развивается с конца 80-х годов и прямо сейчас переживает расцвет в лучах славы big data и highload.
А тем временем на Хабре найдется ли герой, способный пересковоговорить три раза подряд
[səkˈsɪŋkt]?