Мой коллега Рафаэль Григорян eegdude недавно написал статью о том, зачем человечеству потребовалась ЭЭГ и какие значимые явления могут быть зарегистрированы в ней. Сегодня в продолжение темы нейроинтерфейсов мы используем один из открытых датасетов, записанных на игре, использующей механику P300, чтобы визуализировать сигнал ЭЭГ, посмотреть структуру вызванных потеницалов, построить основные классификаторы, оценить качество, с которым мы можем предсказать наличие такого вызыванного потенциала.
Напомню, что P300 — это вызванный потенциал (ВП), специфический отклик мозга связанный с принятием решений и и различением стимулов (что он из себя представляет мы увидим ниже). Обычно он используется для построения современных BCI.
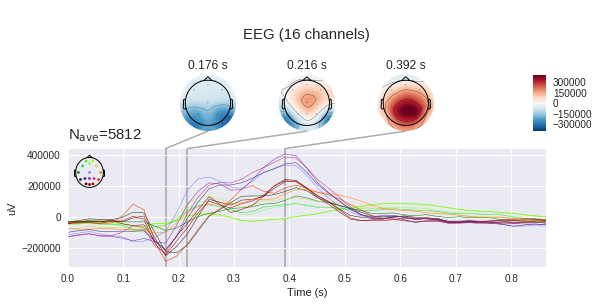
Для того, чтобы заняться классификацией ЭЭГ, можно позвать друзей, написать игру про Енотов и Демонов в VR, записать собственные реакции и написать научную статью (об этом я расскажу как-нибудь в другой раз), но по счастью, учёные со всего мира уже провели некоторые эксперименты за нас и осталось только скачать данные.
Разбор способа построения нейроинтерфейса на P300 с пошаговым кодом и визуализациями, а также ссылку на репозиторий можно найти под катом.