
В предыдущей статье раскрывались некоторые базовые понятия теории типов. В этот раз мы рассмотрим обобщённые типы (generics) – необходимость появления такой абстракции, ключевые особенности и различные сценарии использования в программировании.

Пользователь
В предыдущей статье раскрывались некоторые базовые понятия теории типов. В этот раз мы рассмотрим обобщённые типы (generics) – необходимость появления такой абстракции, ключевые особенности и различные сценарии использования в программировании.

Продолжаю публикацию расширенных транскриптов лекционного курса "PostgreSQL для начинающих", подготовленного мной в рамках "Школы backend-разработчика" в "Тензоре".
В этой лекции мы узнаем, что такое план выполнения запроса, как и зачем его читать (и почему это совсем непросто), и о каких проблемах с производительностью базы он может сигнализировать. Разберем, что такое Seq Scan, Bitmap Heap Scan, Index Scan и почему Index Only Scan бывает нехорош, чем отличается Materialize от Memoize, а Gather Merge от "просто" Gather.
Как обычно, для предпочитающих смотреть и слушать, а не читать - доступна видеозапись (часть 1, часть 2).
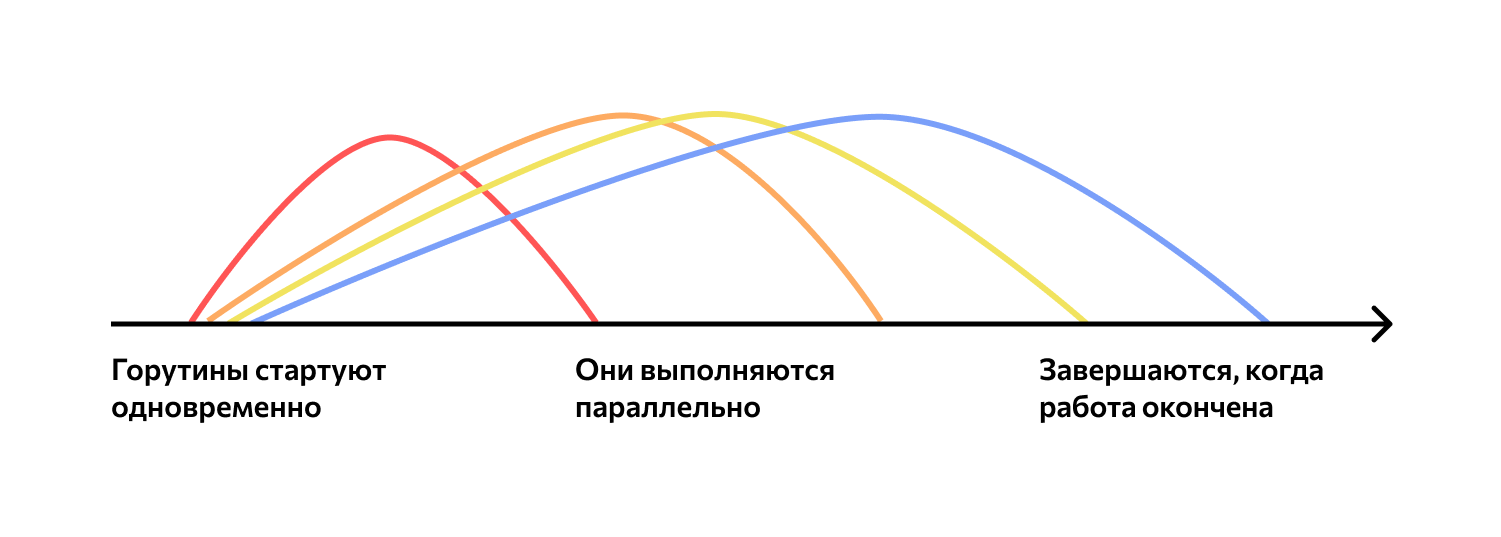
Я довольно давно пишу на Python и во многих проектах использовал multiprocessing — пакет стандартной библиотеки языка Python, который предоставляет интерфейс для работы с процессами, очередями, пулами процессов и многими другими удобными инструментами для параллельного программирования. В какой-то момент я понял, что мне не хватает более детального понимания работы этой библиотеки.
Мне захотелось залезть в исходники multiprocessing, разобраться и заодно написать статью. Данная статья в основном рассчитана на новичков в Python и тех, кто хочет подробнее разобраться в том, как именно создаются процессы и пулы в Python и погрузиться в детали реализации.

Данные - это важный компонент системы. Приложение может хранить их где угодно, но в результате все сводится к файлам. Файлы - это хорошая абстракция, но она протекает: если не знать того, как работают ОС или гарантии файловой системы, то легко выстрелить себе в ногу.
Меня увлекла тема отказоустойчивости, а конкретно - отказоустойчивой работы с файлами. В этой статье я попытался соединить все полученные знания:
Кто участвует в процессе записи
Ошибки, которые могут произойти
Что от нас зависит, а что нет
И самое главное - как это этого защититься
Если вы собрались плотно погрузиться в тему Doman Driven Design (DDD), о том как его применять, как использовать, для чего он нужен, и как с ним связаны Command and Query Responsibility Segregation (CQRS), Event Sourcing и другие термины из мира DDD то можно воспользоваться планом обучения, который последовательно погрузит вас в эти темы и поможет сориентироваться. Часть информации на русском, часть на английском языке, так как русскоязычных аналогов я не смог найти.
Обзор
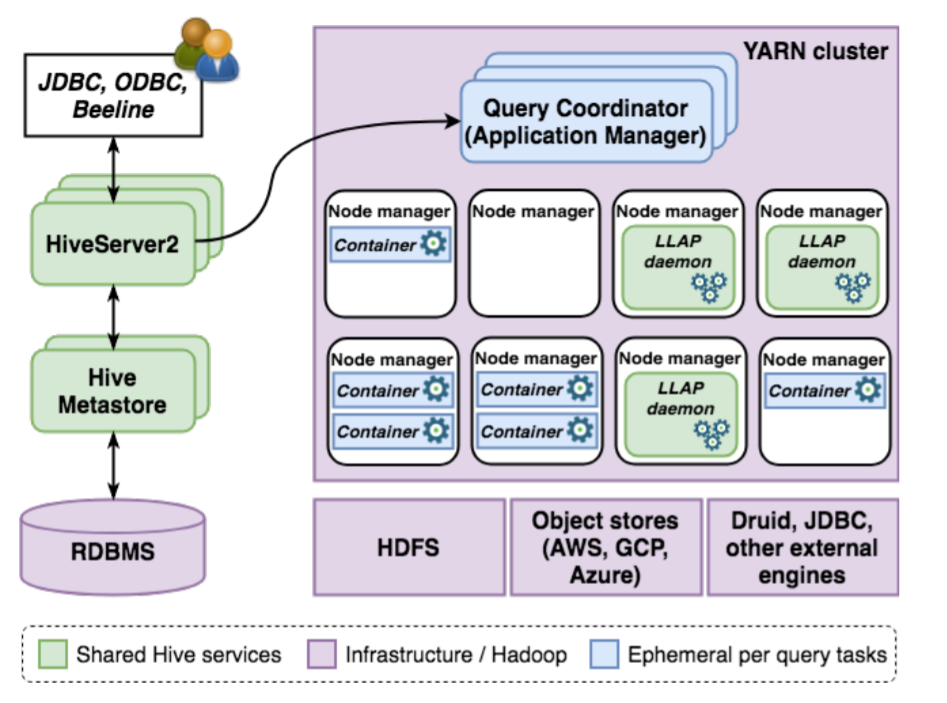
Apache Hive – система управления (СУБД) реляционными базами данных (РБД) с открытым исходным кодом для запросов, агрегирования и анализа параметров и режимов рабочих нагрузок с большими данными. В этой статье описываются ключевые инновационные инструменты для полноценной пакетной обработки в корпоративной системе хранения данных. Мы представляем гибридную архитектуру, которая сочетает в себе традиционные методы массивно-параллельных архитектур (MPP) с физически разделенной памятью с более современными концепциями больших данных, облаков для достижения масштабируемости и производительности, требуемых современными аналитическими приложениями. Мы исследуем систему, подробно описывая улучшения по четырем основным направлениям: транзакция, оптимизатор, среда выполнения и федерация (интеграционный процесс). Затем мы приводим экспериментальные результаты, чтобы продемонстрировать производительность системы для типовых рабочих нагрузок, и в заключение рассмотрим дорожную карту сообщества.
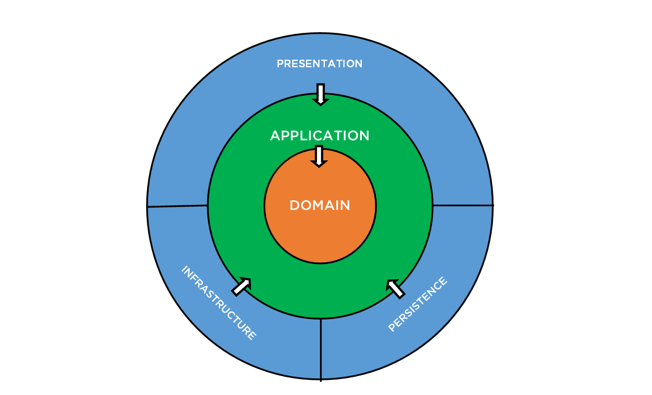
Слой Application - это не только про оркестрацию, но еще немного про бизнес-логику. Следует это простить и принять внутри себя. А иначе попытки продвинуться дальше в написании кода съедят программиста-перфекциониста живьем.
Можно долго искать решения, читать различные комментарии и книги про разделение бизнес-логики от приложения. И все равно ваша конкретная ситуация будет казаться вам уникальной, как будто ничего нельзя сделать либо надо снова переписывать Domain слой, дабы ни одно зернышко бизнес-логики не выпало за его пределы. А можно просто закрыть глаза на некоторые моменты, забыть об идеале и спать спокойно, рассчитывая, что все чудесным образом само разрулится.
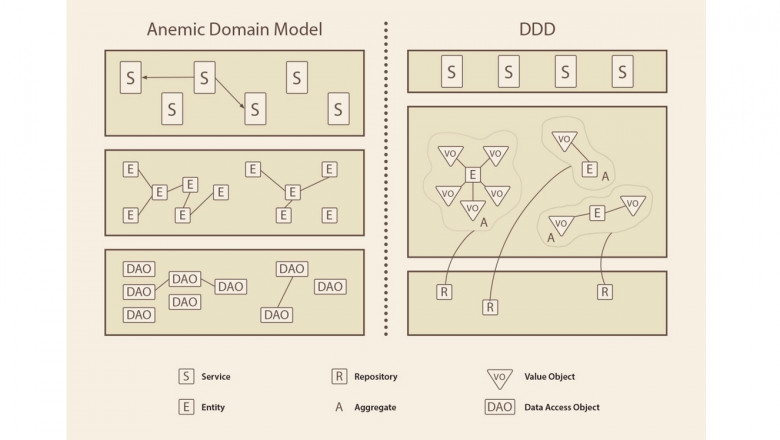
Многие проекты на Django начинаются просто: есть база данных и к приложению, которое крутится на сервере, идут обращения. Например, так начиналась Dodo IS (информационная система компании Додо Пицца, где работал автор сегодняшней статьи). Но если использовать Django из коробки, можно натворить много бед и встретить пачку антипаттернов. Возможно, вы встречали такое на старых legacy-проектах.
Евгений Пешков развивает сообщество DDD-практиков, рассказывая, какие проблемы решает Domain-Driven Design (предметно-ориентированное проектирование) в современном мире. На конференции Russian Python Week 2020 он выступил с рассказом об этом. Кстати, 19 августа пройдет встреча DDDevotion-сообщества, присоединяйтесь, будем о чем поговорить.
В сегодняшней статье будет его рассказ про то, как устроен Domain-Driven Design и какие инструменты использует, чтобы наиболее точно описать требования бизнеса и сам бизнес.
Приветствую тебя, хаброжитель!
В этой статье разберём 100 вопросов, они покрывают львиную долю того, что могут спросить на собеседовании джуниор Go-разработчика с практически любой специализацией. Конечно же, в реальной работе на Go требуются немного другие скиллы, чем умение быстро ответить на любой вопрос. Однако сложилась добрая традиция делать из собеседования викторину с главным призом в виде трудоустройства — к этому нужно быть готовым.
Эта статья — цельный план развития во фронтенде. Расскажем, что из себя представляет современный фронтенд и какие знания нужны для востребованности на рынке труда.
Статья подойдет как для начинающих специалистов, так и для более опытных, которые хотели бы получить какой-то ориентир для дальнейшего развития.
К статье прилагается роадмэп, который можно скачать, изучать, распечатать.
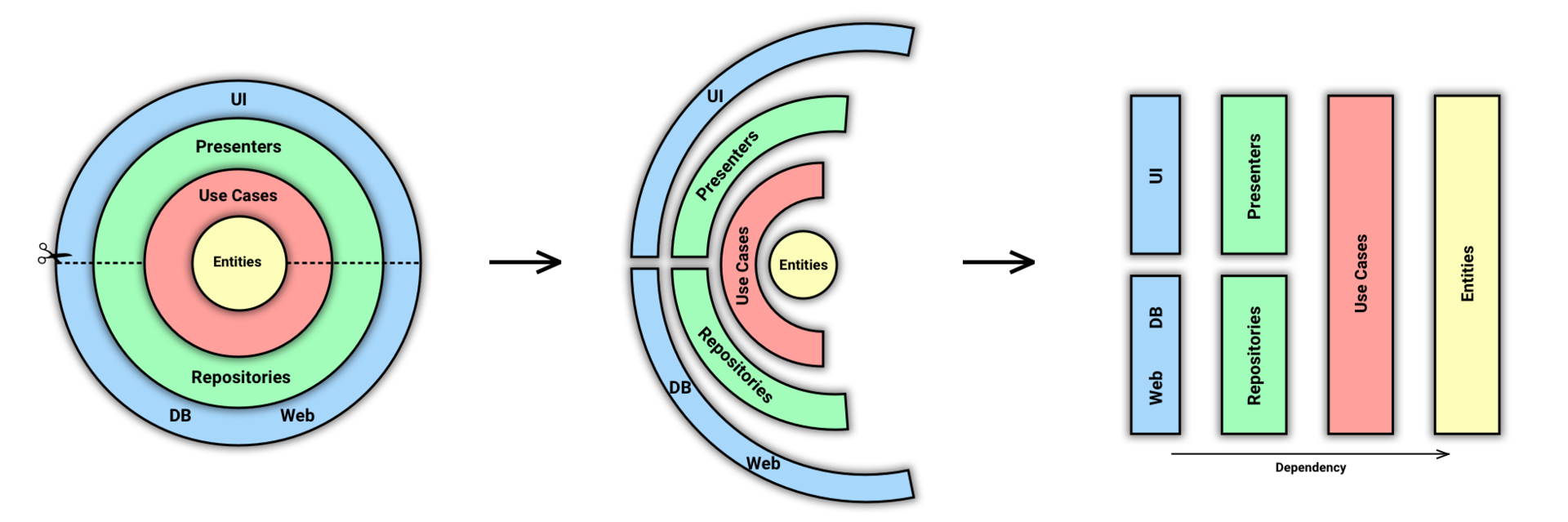
На первый взгляд, Clean Architecture – довольно простой набор рекомендаций к построению приложений. Но и я, и многие мои коллеги, сильные разработчики, осознали эту архитектуру не сразу. А в последнее время в чатах и интернете я вижу всё больше ошибочных представлений, связанных с ней. Этой статьёй я хочу помочь сообществу лучше понять Clean Architecture и избавиться от распространенных заблуждений.

Двадцать лет назад Джоэл Спольски написал: «Не существует такой штуки, как «обычный текст». Если имеется строка, но неизвестно, какую кодировку символов она использует — смысла в этой строке нет. Больше нельзя спрятать голову в песок и притвориться, что «обычный» текст имеет кодировку ASCII.»
Многое изменилось за 20 лет. В 2003 году главный вопрос звучал так: «Что это за кодировка?». В 2023 году такой вопрос больше не стоит: с вероятностью в 98% это — UTF-8. Наконец то! Можно снова спрятать голову в песок!


Всем привет меня зовут Максим, я SRE инженер в группе компаний Тинькофф.
Но сегодня я здесь по другой причине.
Я уже давно собираю и публикую подборки видео, от которых есть толк, с разных каналов SRE направленности в телеграмм канале https://t.me/sre_pub и спасибо им большое за то что позволяют мне это делать.
Но я не видел подобных подборок на хабре и для меня до сих пор загадка почему.
Лично для меня Хабр является основной площадкой для получения информации.
Вы можете это понять по 1500+ моих закладок в профиле.
Так вот я просмотрел все доклады с SREcon23 составил для вас подборку из докладов вырезав все доклады в которых было больше болтовни или рекламы чем пользы.

Сейчас трудно себе представить «боевую» инсталляцию любой серьезной СУБД в виде единственного инстанса. Конечно, некоторые приложения требуют для своей работы использование локальных баз данных, но если мы говорим о сетевом многопользовательском режиме работы, то здесь использование только одной инсталляции это очень плохая идея.
Основной проблемой единственной инсталляции естественно является надежность. В случае падения сервера нам потребуется некоторое, возможно значительное, время на восстановление. Так восстановление террабайтной базы может занять несколько часов.
Да и исправный бэкап есть не всегда, но об этом мы уже говорили в предыдущей статье.
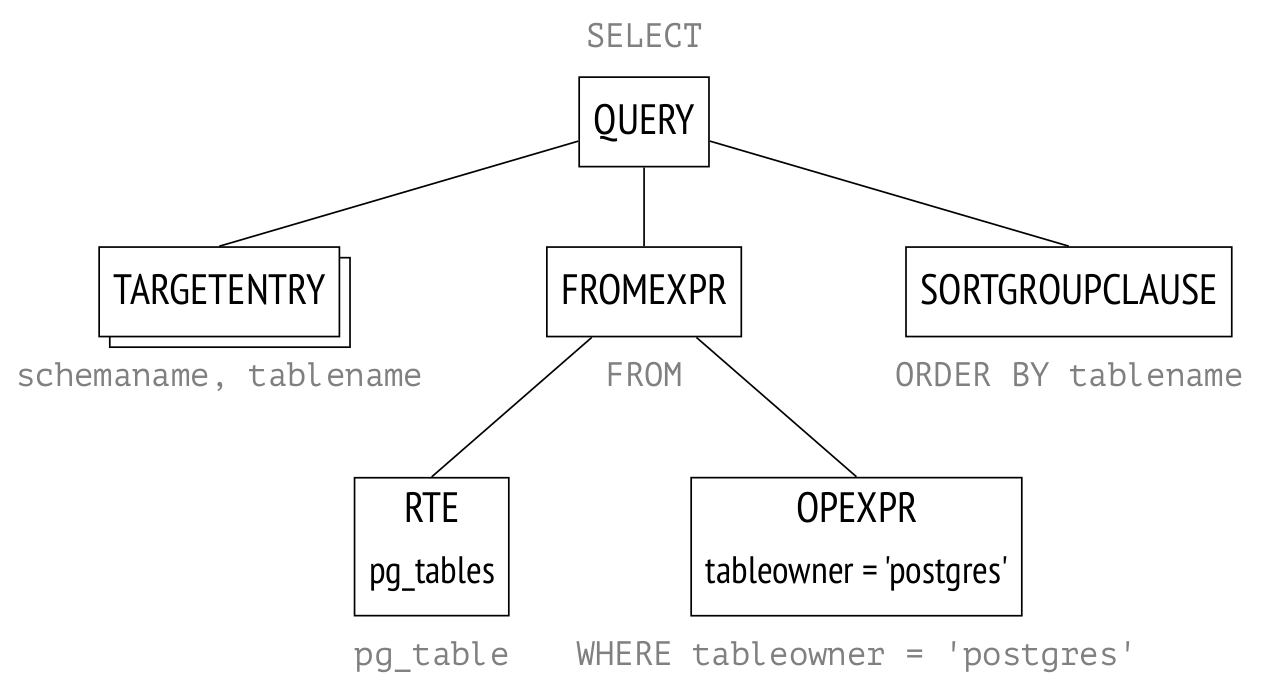
Привет, Хабр! Начинаю еще один цикл статей об устройстве PostgreSQL, на этот раз о том, как планируются и выполняются запросы.
Предыдущие циклы были посвящены изоляции и многоверсионности, журналированию и блокировкам.
В этом цикле я собираюсь рассмотреть этапы выполнения запросов, статистику, последовательное сканирование, индексное сканирование, соединение вложенным циклом, соединение хешированием, сортировку и соединение слиянием.
Материал перекликается с нашим учебным курсом QPT «Оптимизация запросов», но ограничивается только подробностями внутреннего устройства и не затрагивает оптимизацию как таковую. Кроме того, я ориентируюсь на еще не вышедшую версию PostgreSQL 14. А курс мы тоже скоро обновим (правда, на версию 13; приходится бежать со всех ног, чтобы только оставаться на месте).
Пролог
- Глянь, статью на Хабр подготовил.
- Эм... а почему заголовок на английском?
- "Предметно-ориентированное проектирование, Гексагональная архитектура портов и адаптеров, Внедрение зависимостей и Пайто..."
С пронзительным хлопком в воздухе материализуется обалдевший Сатана в обличии сине-жёлтого питона.
--
Эта техническая статья о применении практик гексагональной архитектуры и всего остального вышеперечисленного в разработке приложений. На примере рассматривается как элегантно вплести гексагональную архитектуру в устоявшуюся, консервативную и казалось бы совершенно безкомпромиссную структуру веб-приложений на Django
Helm — один из самых популярных пакетных менеджеров для Kubernetes. Познакомиться с ним полезно любому DevOps-инженеру и всем, кто сталкивается с задачами деплоя приложений. Эта статья — первый из двух материалов, которые можно вместе можно рассматривать как краткое, но достаточно полное введение в Helm.

Добрый день, Хабр! Хочу поделиться учебником-справочником знаний, которые мне удалось собрать по RabbitMQ и сжать в короткие рекомендации и выводы.