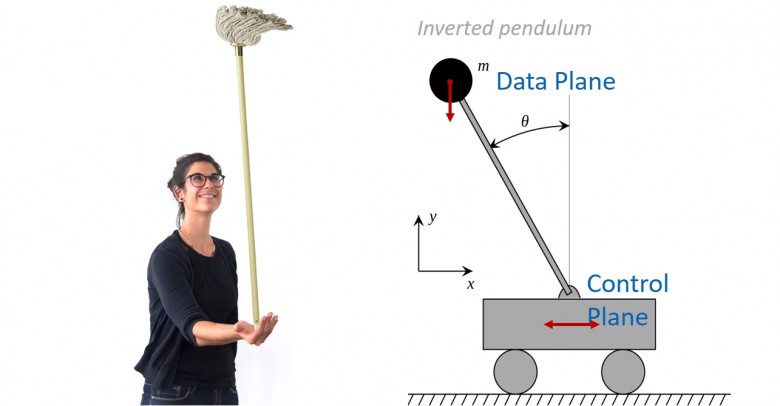
Помните детскую забаву? Поставить швабру на ладонь и удержать ее в вертикальном положении как можно дольше? В теории управления она известна под именем обратного маятника. Есть палка с грузом на конце и тележка, которая должна удерживать этот маятник в вертикальном положении.
Это отличная аналогия для современных облачных сервисов. Палка с грузом — это Data Plane сервиса. На русский язык этот термин можно перевести как “уровень передачи и обработки данных”. Тележка — Control Plane или “уровень управления”. Основная задача Control Plane заключается в обеспечении стабильной работы Data Plane. То есть нужно балансировать так, чтобы Data Plane всегда был в вертикальном, работоспособном состоянии. Это не просто — любые задержки и сбои в Control Plane неминуемо приведут к тому, что Data Plane “упадет”. Василий Пантюхин, архитектор AWS, поделится примером того, как нетривиальную задачу по стабилизации сервисов решают в облаке Amazon.