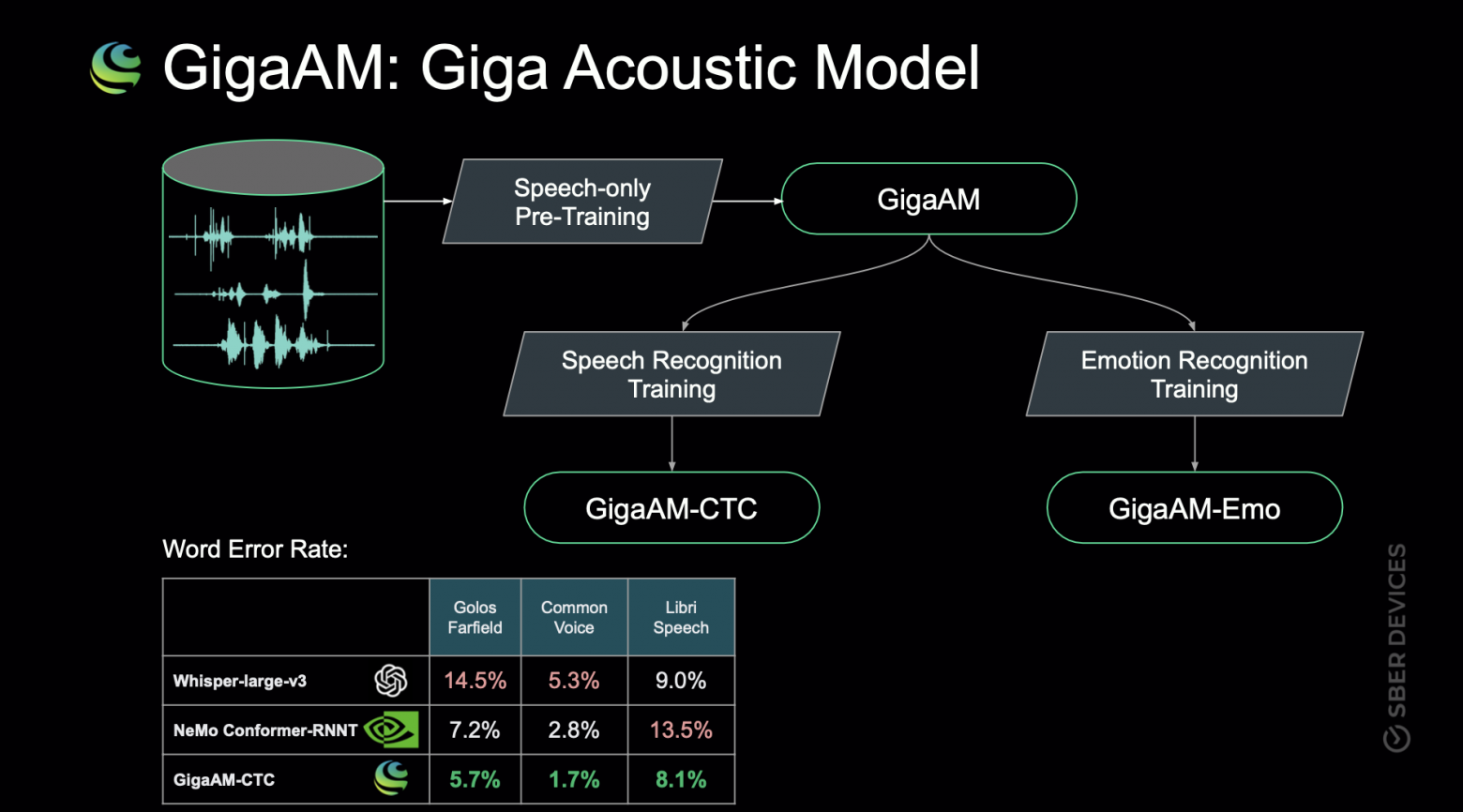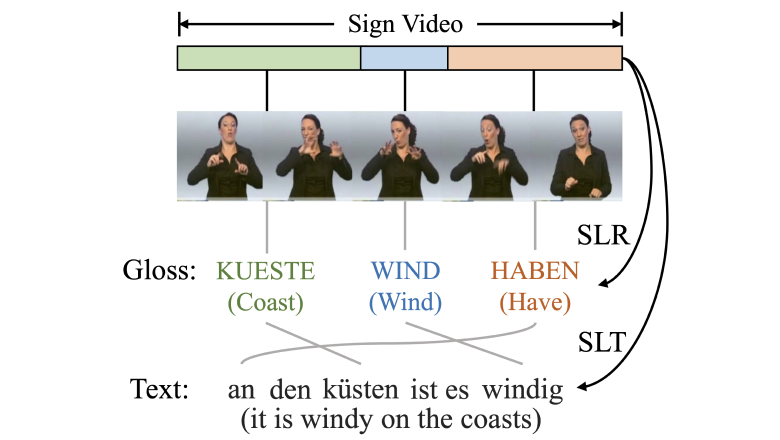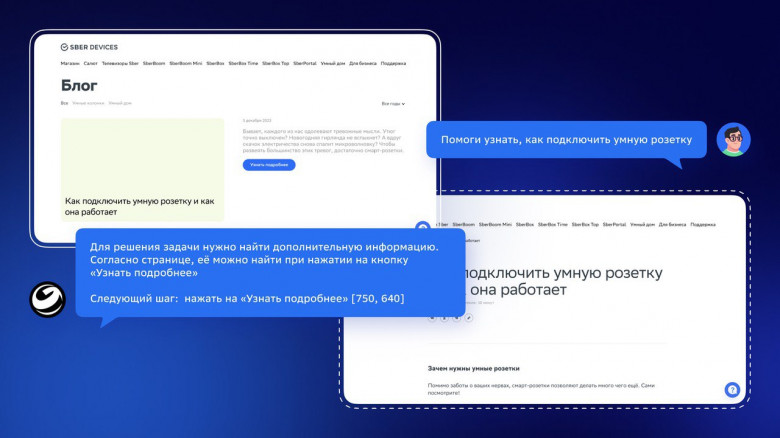
Всем привет!
На связи Георгий Бредис, Deep Learning Engineer из команды Intelligent Document Processing в SberDevices. Наша команда занимается задачами автоматизации бизнес-процессов путем извлечения информации из неструктурированного контента и созданием сервисов суммаризации и поиска на основе LLM. В данный момент мы исследуем новые способы извлечения информации из интерфейсов, что открывает новые возможности для автоматизации процессов в сфере RPA.
В этой статье речь пойдет об использовании больших языковых моделей для работы с браузером, как одного из самых распространенных примеров интерфейса.