Архитектура RISC-V корнями уходит к началу 1980-х годов, группа под руководством Дэвида Паттерсона в стенах университета Беркли разработала архитектуры RISC-I и RISC-II. Долгое время архитектуре приходилось существовать в тени лицензируемых ARM и MIPS ядер. Архитектура RISC-V появилась в 2010 году, и поддерживается Linux Foundation. Отметка в 10 миллиардов произведенных ядер была преодолена за 12 лет.
Сейчас RISC-V может сыграть большую роль в становлении российской микроэлектроники. Компании CloudBEAR и Syntacore работают над процессорами собственной микроархитектуры, совместимыми с системой команд RISC-V. Архитектура RISC-V позволяет нашим разработчикам создавать энергоэффективные процессоры сравнимого с мировым уровня и сохранять программную совместимость со всеми программами, созданными для экосистемы RISC-V во всем мире.
В данной статье мы попробуем на примере RISC-V платы MangoPi разобраться, как выполняется кросс-компиляция под RISC-V.
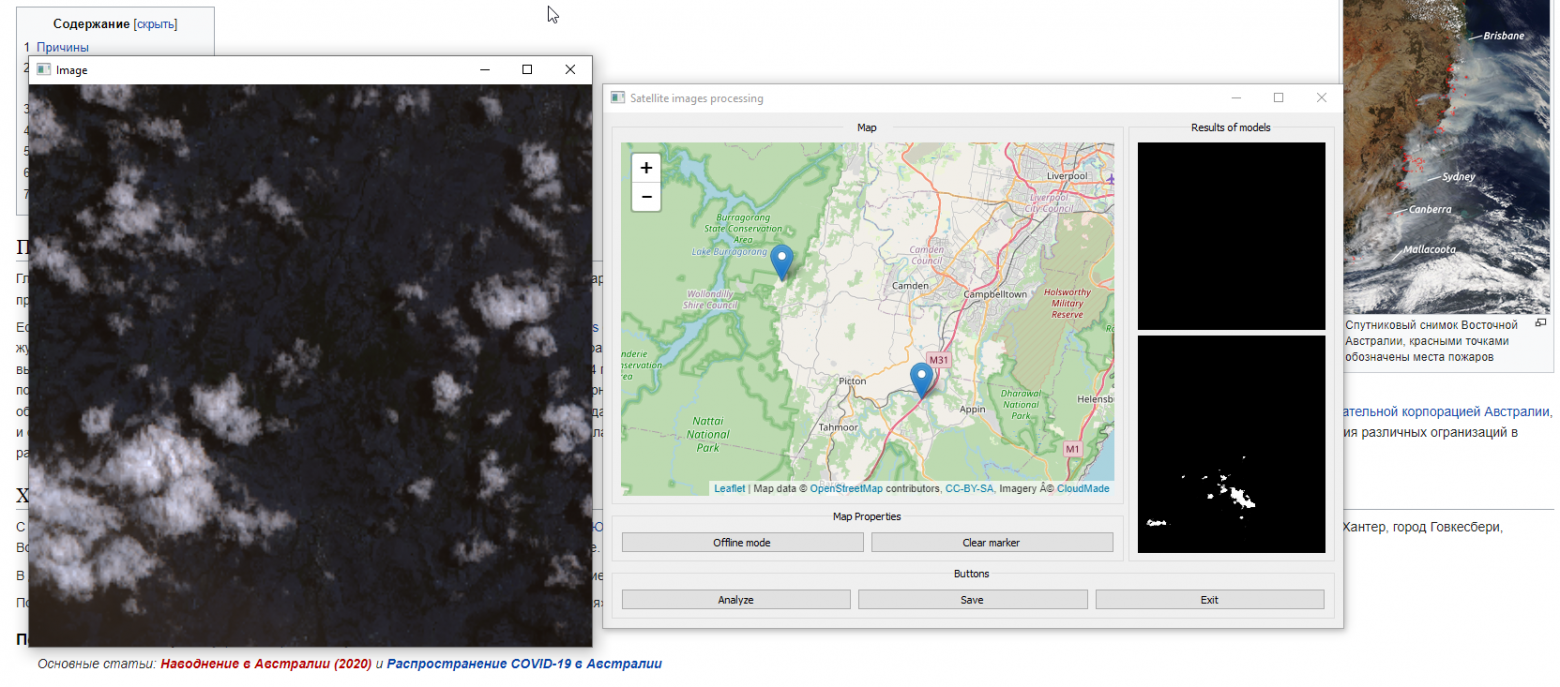
Использование моделей глубокого обучения для решения задачи семантической сегментации (задачи присвоения метки принадлежности к некоторому классу для каждого из пикселей изображения) стало широко используемой практикой в различных областях: в медицине для анализа рентгеновских снимков и данных компьютерной томографии, в анализе видео с видеорегистраторов, управлении роботизированными манипуляторами. Развивающейся является тематика использования моделей глубокого обучения для сегментации спутниковых данных.
Каждый фреймворк глубокого обучения использует свой подход к инференсу глубоких моделей и находит компромисс между временем обработки данных, потреблением ресурсов и качеством работы. Результатом такого разнообразия является множество возможных комбинаций из задачи машинного обучения, фреймворка, модели, набора тестовых данных и целевого устройства, что делает задачу оценки производительности инференса крайне трудной. Именно поэтому разрабатываются системы, позволяющие автоматически собирать данные о производительности и качестве работы большого количества моделей.
Полноценных школ по компьютерному зрению, таких, чтобы участники могли получить опыт от разработчиков алгоритмов из крупных технологических компаний, осталось очень немного. В этом плане больше всего повезло студентам из Нижнего Новгорода, ведь каждое лето силами преподавателей Университета Лобачевского и инженеров компании Intel проводится Computer Vision Summer Camp - Летняя школа по компьютерному зрению. А для тех, кому не удалось на нее попасть, мы расскажем самое важное и интересное…
Задачу обнаружения различных объектов сейчас модно решать на основе глубокого обучения. Но для этого нужно собрать и разметить датасет, сконструировать глубокую нейросеть, обучить ее и запустить “в продакшн”. И если недавно для всего этого приходилось самостоятельно писать код, то сейчас можно воспользоваться готовыми инструментами от опытных разработчиков. Мы воспользуемся CVAT для разметки датасета, OpenVINO Training Extensions для обучения модели и OpenVINO Object Detection Demo для ее инференса. И не напишем ни строчки кода (команды консоли не в счет).
Данная статья будет полезна студентам и тем, кто хочет разобраться с тем, как происходит шумоподавление речи (Speech Denoising) с помощью глубокого обучения. На Хабре уже были статьи по данной тематике несколько лет назад (раз, два), но нашей целью является желание дать несколько более глубокое понимание процесса работы со звуком.
В первой части мы уже познакомились с тем, какие существуют методы для повышения производительности, что такое DL Workbench, как в него загрузить модель для оптимизации. Настало время познакомиться еще с двумя методами повышения производительности инференса - квантизация моделей и Throughput mode.
Если у вас есть проект с интенсивной обработкой данных глубокими моделями (или еще нет, но вы собираетесь его создать), то вам будет полезно познакомиться с приемами по повышению их производительности и уменьшению затрат на покупку / аренду вычислительных мощностей. Тем более, что многие из приемов сейчас выполняются буквально за несколько кликов мышкой, но при этом позволяют повысить производительность на порядок. В этом посте мы рассмотрим какие оптимизации бывают, установим Docker на Windows 10 и запустим DL Workbench, измерим производительность инференса без оптимизации и с применением оных.
Перед разработчиками встает задача определения производительности железа в задаче исполнения глубоких моделей. Например, хочется решить проблему анализа пола-возраста покупателей, которые заходят в магазин, чтобы в зависимости от этого менять оформление магазина или наполнение товаром. Вы уже знаете какие модели хотите использовать в вашем ПО, но до конца не понятно как выбрать железо. Можно выбрать самый топ и переплачивать как за простаивающие мощности, так и за электроэнергию. Можно взять самый дешевый i3 и потом вдруг окажется, что он может вывезти каскад из нескольких глубоких моделей на 8 камерах. А может быть камера всего одна, и для решения задачи достаточно Raspberry Pi с Movidius Neural Compute Stick? Поэтому хочется иметь инструмент для оценки скорости работы вашего инференса на разном железе, причем еще до начала обучения.
Меня зовут Васильев Евгений, и команда в составе Дмитрия, Вячеслава и меня заняла 2 место на хакатоне "Цифровой прорыв" в Нижнем Новгороде в кейсе Ростелекома: Разработка системы мониторинга за поведением студента во время экзамена, и забрала приз в 100 000 рублей. После просмотра решений всех команд и возникла идея для данной заметки с громким названием.
Репозиторий моделей Open Model Zoo библиотеки OpenVINO содержит много самых разных глубоких нейронных сетей из области компьютерного зрения (и не только). Но нам пока не встретилось GAN моделей, которые генерировали бы новые данные из шума. В этой статье мы создадим такую модель в Keras и запустим ее в OpenVINO.
Кустикова Валентина, Васильев Евгений, Вихрев Иван, Дудченко Антон, Уткин Константин и Коробейников Алексей.
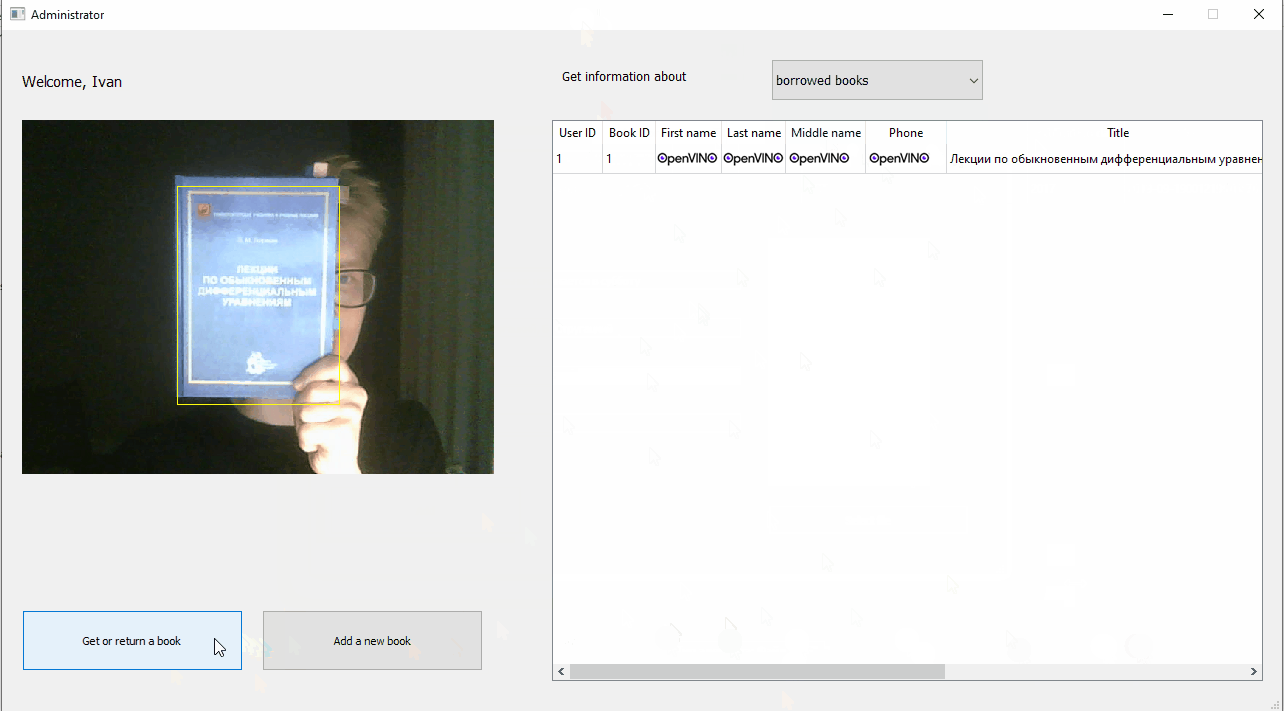
Intel Distribution of OpenVINO Toolkit — набор библиотек для разработки приложений, использующих машинное зрение и Deep Learning. А эта статья расскажет, как создавалось демо-приложение «Умная библиотека» на основе библиотеки OpenVINO силами студентов младших курсов. Мы считаем, что данная статья будет интересна начинающим свой путь в программировании и использовании глубоких нейронных сетей.