Этим постом я запускаю публикацию расширенных транскриптов лекционного курса "PostgreSQL для начинающих", подготовленного мной в рамках "Школы backend-разработчика" в "Тензоре".
В программе: рассказ об основах SQL, возможностях простых и сложных SELECT, анализ производительности запросов, разбор [не]эффективного применения индексов и особенностей работы транзакций и блокировок в этой СУБД.
Курс не претендует на лавры "войти в айти", поэтому подразумевает наличие у слушателя опыта программирования или работы с другими СУБД, и, главное, желания самостоятельно изучать тему работы с PostgreSQL глубже.
Для тех, кому комфортнее смотреть и слушать, а не читать - доступна видеозапись.

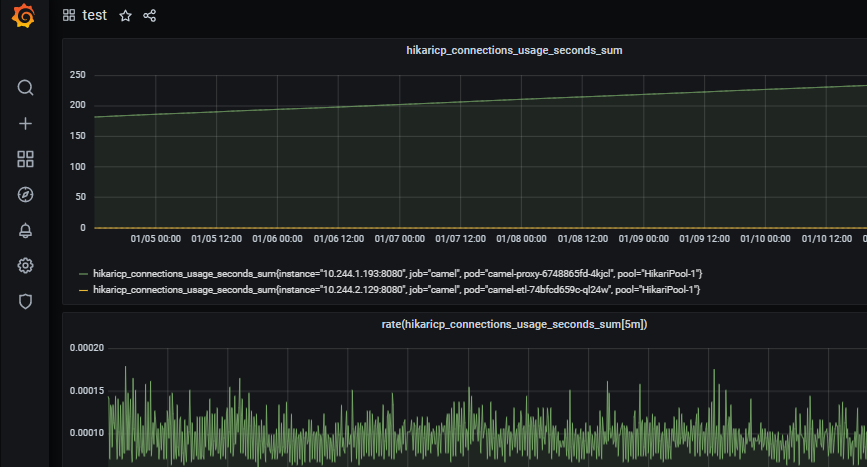





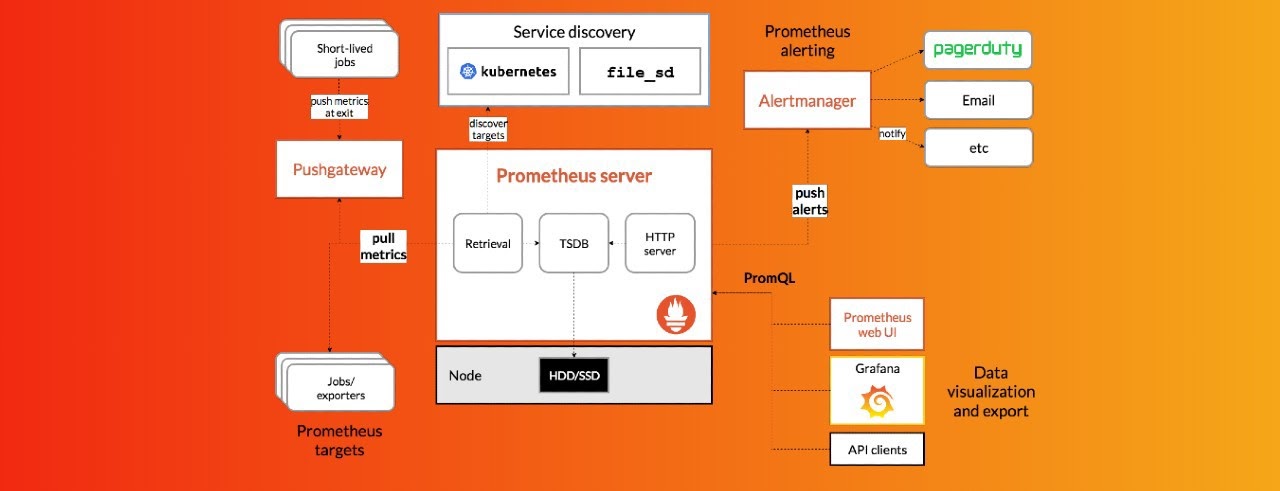
 Эта статья содержит краткую выжимку из моего собственного опыта и опыта моих коллег, с которыми мне днями и ночами доводилось разгребать инциденты. И многих инцидентов не возникло бы никогда, если бы всеми любимые микросервисы были написаны хотя бы немного аккуратнее.
Эта статья содержит краткую выжимку из моего собственного опыта и опыта моих коллег, с которыми мне днями и ночами доводилось разгребать инциденты. И многих инцидентов не возникло бы никогда, если бы всеми любимые микросервисы были написаны хотя бы немного аккуратнее.