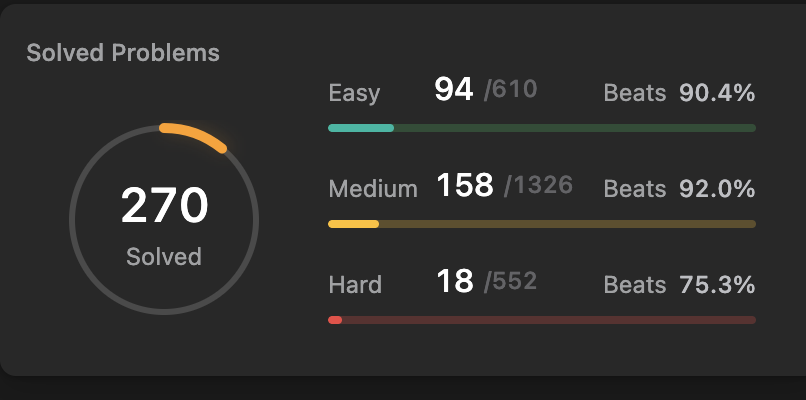
Это статья с 21-ой ссылкой о подготовке к собеседованиям. Я собеседовался на позиции Machine Learning Engineer.
Разобрал основные этапы (алгоритмы, machine learning system design, поведенческий этап) и как к ним готовиться.

Пользователь
Это статья с 21-ой ссылкой о подготовке к собеседованиям. Я собеседовался на позиции Machine Learning Engineer.
Разобрал основные этапы (алгоритмы, machine learning system design, поведенческий этап) и как к ним готовиться.
Ознакомиться с самой идеей атаки CSRF можно на классических ресурсах:
Причина CSRF кроется в том, что браузеры не понимают, как различить, было ли действие явно совершено пользователем (как, скажем, нажатие кнопки на форме или переход по ссылке) или пользователь неумышленно выполнил это действие (например, при посещении bad.com, ресурсом был отправлен запрос на good.com/some_action, в то время как пользователь уже был залогинен на good.com).
Эффективным и общепринятым на сегодня способом защиты от CSRF-Атаки является токен. Под токеном имеется в виду случайный набор байт, который сервер передает клиенту, а клиент возвращает серверу.
Защита сводится к проверке токена, который сгенерировал сервер, и токена, который прислал пользователь.
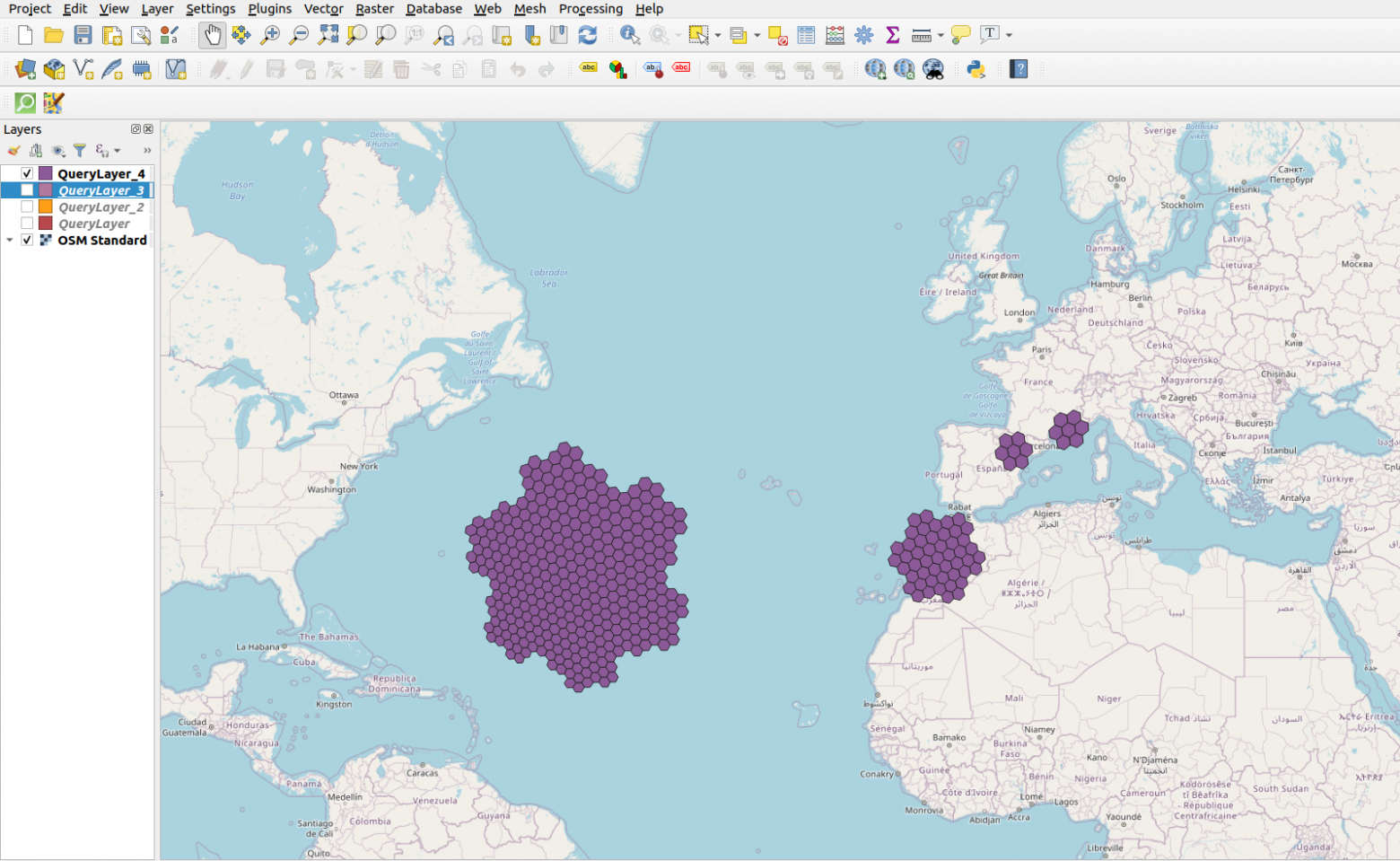
Когда человек раньше говорил что он контролирует весь мир, то его обычно помещали в соседнюю палату с Бонапартом Наполеоном. Надеюсь, что эти времена остались в прошлом и каждый желающий может анализировать геоданные всей земли и получать ответы на свои глобальные вопросы за минуты и секунды. Я опубликовал Openstreetmap_h3 — свой проект, который позволяет производить геоаналитику над данными из OpenStreetMap в PostGIS или в движке запросов, способном работать с Apache Arrow/Parquet.
Первым делом передаю привет хейтерам и скептикам. То что я разработал — действительно уникально и решает проблему преобразования и анализа геоданных используя обычные и привычные инструменты доступные каждому аналитику и датасаенс специалисту без бигдат, GPGPU, FPGA. То что выглядит сейчас простым в использовании и в коде — это мой личный проект в который я инвестировал свои отпуска, выходные, бессонные ночи и уйму личного времени за последние 3 года. Может быть я поделюсь и предысторией проекта и граблями по которым ходил, но сначала я все же опишу конечный результат.
Первый пост не претендует на монографию, начну с краткого обзора...
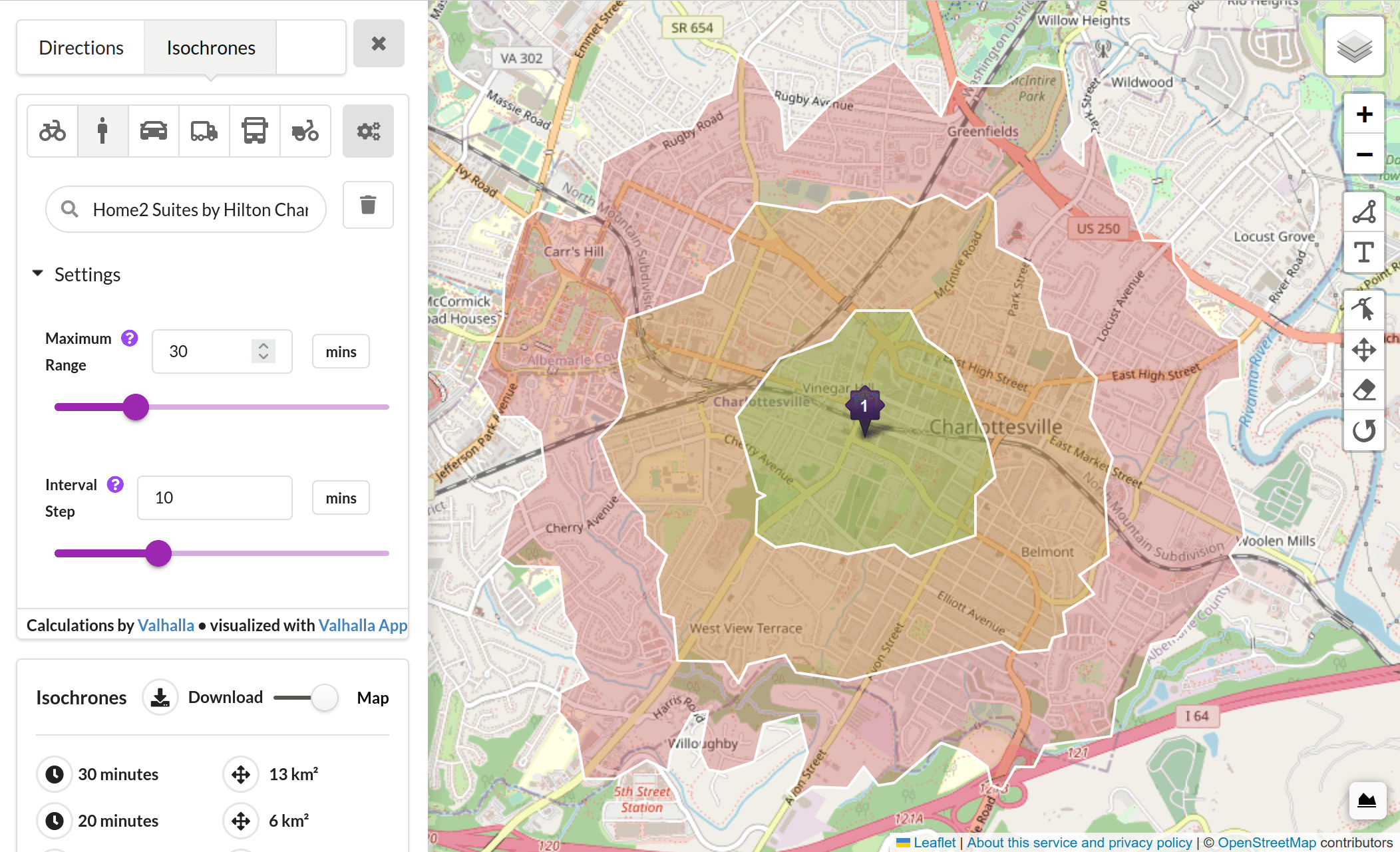

Я был в восторге, когда узнал об утечке проприетарного исходного кода Яндекса. И после анализа данных я должен сказать, что выводы оказались весьма интересными! Итак, без лишних слов, давайте окунемся в основные выводы, которые я сделал.

Ориентировочно с мая 2022 года в разных темах на форуме 4PDA и других интернет-площадках начали появляться сообщения вида "Что-то смартфон стал плохо ловить спутники GPS и показывать точное местоположение". Многие связывали это с обновлениями прошивок, пробовали откатываться, использовать различные приложения, дергающие различные API Android...
Объединяло все эти жалобы два момента: все смартфоны на чипах Qualcomm Snapdragon различных поколений, и все пользователи были из РФ.

Уже февраль 2021 года, а значит пришло время подводить итоги! В это время, 3 года назад, состоялся первый альфа релиз библиотеки. Библиотека DeepPavlov v0.0.1 содержала несколько предварительно обученных моделей и конфигураций JSON. А сегодня у нас есть несколько продуктов, множество пользователей и сценариев использования, достижения в всемирно известных конкурсах и конференциях, и всего через несколько месяцев библиотека DeepPavlov совершит скачок до версии v1.
И несмотря на обстоятельства пандемии, в 2020 году у нас было много задач и поводов для гордости. Как минимум, мы обновили наш веб-сайт, выпустили новый продукт DP Dream, выиграли Про/Чтение, а также повторно участвуем в Alexa Prize Challenge. Об этих и других достижениях мы рады поделиться с вами в обзоре нашего 2020 года.
Ps. 5 марта в честь 3х летия состоится встреча пользователей и разработчиков открытой библиотеки DeepPavlov. Посмотреть детали и зарегистрироваться можно на сайте.




Прим. перев.: это не совсем обычный перевод, потому что в его основе не отдельно взятая статья, а недавний случай со Stack Exchange, ставший главным хитом ресурса в этом месяце. Его автор задает вопрос, ответ на который можно отнести к базовым знаниям в области ИТ, но в то же время оказавшийся откровением для некоторых посетителей сайта.
Сжимая каталоги по ~1,3 ГБ, в каждом из которых по 1440 файлов JSON, я обнаружил 15-кратную разницу между размером архивов, сжатых с помощью tar на macOS или Raspbian 10 (Buster), и архивов, полученных при использовании библиотеки tarfile, встроенной в Python.
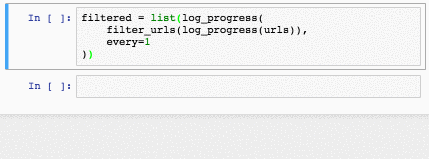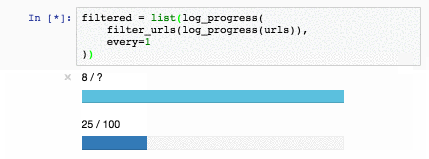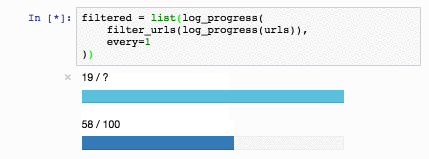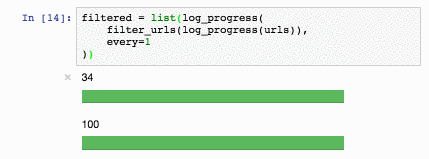
def log_progress(sequence, every=10):
for index, item in enumerate(sequence):
if index % every == 0:
print >>sys.stderr, index,
yield item



Не успели отшуметь новости о нейросети BERT от Google, показавшей state-of-the-art результаты на целом ряде разговорных (NLP) задач в машинном обучении, как OpenAI выкатили новую разработку: GPT-2. Это нейронная сеть с рекордным на данный момент числом параметров (1.5 млрд, против обычно используемых в таких случаях 100-300 млн) оказалась способна генерировать целые страницы связного текста.
Генерировать настолько хорошо, что в OpenAI отказались выкладывать полную версию, опасаясь что эту нейросеть будут использовать для создания фейковых новостей, комментариев и отзывов, неотличимых от настоящих.
Тем не менее, в OpenAI выложили в общий доступ уменьшенную версию нейросети GPT-2, со 117 млн параметров. Именно ее мы запустим через сервис Google Colab и поэкспериментруем с ней.

Сегодня попробуем обучить свою собственную нейронную сеть, чтобы писала текст для песен. Обучающей выборкой будут тексты группы "Руки Вверх". Ничто не мешает чтобы поменять данные на тексты своих любимых групп. Для извлечения данных с веб-сайтов используем Python3 (модуль BeautifulSoup).
Задача будет состоять в том, чтобы выгрузить данные(тексты) c веб-сайтов а потом на их основе обучить нейронную сеть.
На самом деле, можно разбить работу на 2 этапа:
Этап 1: выгрузить и сохранить тексты песни в удобном формате.
Этап 2: обучить свою собственную нейронную сеть.

Все справочники из этой статьи бесплатны и открыто лежат в интернете. Ни один не украли из ФСБ таинственные хакеры.