Летом прошёл онлайн-интенсив GET PROF IT: Messaging, посвящённый работе с инструментами, которые пригодятся Java-разработчикам. Для тех, кто только вернулся из отпусков и пропустил это событие, мы решили поделиться записями воркшопов.

Антон Шеленков @Anshelen
Java-разработчик
Как одно изменение конфигурации PostgreSQL улучшило производительность медленных запросов в 50 раз
3 мин
Здравствуйте, хабровчане! Предлагаю вашему вниманию перевод статьи «How a single PostgreSQL config change improved slow query performance by 50x» автора Pavan Patibandla. Она очень сильно мне помогла улучшить производительность PostgreSQL.
В Amplitude наша цель — предоставить простую в использовании интерактивную аналитику продуктов, чтобы каждый мог найти ответы на свои вопросы о продукте. Чтобы обеспечить удобство работы, Amplitude должен быстро предоставить эти ответы. Поэтому, когда один из наших клиентов пожаловался на то, сколько времени потребовалось для загрузки раскрывающегося списка свойств события в пользовательском интерфейсе Amplitude, мы приступили к детальному изучению проблемы.
Отслеживая задержку на разных уровнях, мы поняли, что одному конкретному запросу PostgreSQL потребовалось 20 секунд для завершения. Для нас это стало неожиданностью, так как обе таблицы имеют индексы в соединяемом столбце.
Медленный запрос

В Amplitude наша цель — предоставить простую в использовании интерактивную аналитику продуктов, чтобы каждый мог найти ответы на свои вопросы о продукте. Чтобы обеспечить удобство работы, Amplitude должен быстро предоставить эти ответы. Поэтому, когда один из наших клиентов пожаловался на то, сколько времени потребовалось для загрузки раскрывающегося списка свойств события в пользовательском интерфейсе Amplitude, мы приступили к детальному изучению проблемы.
Отслеживая задержку на разных уровнях, мы поняли, что одному конкретному запросу PostgreSQL потребовалось 20 секунд для завершения. Для нас это стало неожиданностью, так как обе таблицы имеют индексы в соединяемом столбце.
Медленный запрос
Объясняя необъяснимое
11 мин
Перевод
Друзья, мы с радостью продолжаем публикацию интересных материалов, посвященных самым разнообразным аспектам работы с PostgreSQL. Сегодняшний перевод открывает целую серию статей за авторством Hubert Lubaczewski, которые наверняка заинтересуют широкий круг читателей.

Одна из первых вещей, которую слышит новоиспеченный администратор баз данных – «используй EXPLAIN». И при первой же попытке он сталкивается c непостижимым:
Что бы это могло значить?
Одна из первых вещей, которую слышит новоиспеченный администратор баз данных – «используй EXPLAIN». И при первой же попытке он сталкивается c непостижимым:
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
Sort (cost=146.63..148.65 rows=808 width=138) (actual time=55.009..55.012 rows=71 loops=1)
Sort Key: n.nspname, p.proname, (pg_get_function_arguments(p.oid))
Sort Method: quicksort Memory: 43kB
-> Hash Join (cost=1.14..107.61 rows=808 width=138) (actual time=42.495..54.854 rows=71 loops=1)
Hash Cond: (p.pronamespace = n.oid)
-> Seq Scan on pg_proc p (cost=0.00..89.30 rows=808 width=78) (actual time=0.052..53.465 rows=2402 loops=1)
Filter: pg_function_is_visible(oid)
-> Hash (cost=1.09..1.09 rows=4 width=68) (actual time=0.011..0.011 rows=4 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 1kB
-> Seq Scan on pg_namespace n (cost=0.00..1.09 rows=4 width=68) (actual time=0.005..0.007 rows=4 loops=1)
Filter: ((nspname <> 'pg_catalog'::name) AND (nspname <> 'information_schema'::name))
Что бы это могло значить?
Boot yourself, Spring is coming (Часть 1)
32 мин
Евгений EvgenyBorisov Борисов (NAYA Technologies) и Кирилл tolkkv Толкачев (Циан.Финанс, Твиттер) рассказывают о самых важных и интересных моментах Spring Boot на примере стартера для воображаемого Железного банка.

В основе статьи — доклад Евгения и Кирилла с нашей конференции Joker 2017. Под катом — видео и текстовая расшифровка доклада.
В основе статьи — доклад Евгения и Кирилла с нашей конференции Joker 2017. Под катом — видео и текстовая расшифровка доклада.
Блокировки в PostgreSQL: 2. Блокировки строк
14 мин
В прошлый раз мы говорили о блокировках на уровне объектов, в частности — о блокировках отношений. Сегодня посмотрим, как в PostgreSQL устроены блокировки строк и как они используются вместе с блокировками объектов, поговорим про очереди ожидания и про тех, кто лезет без очереди.
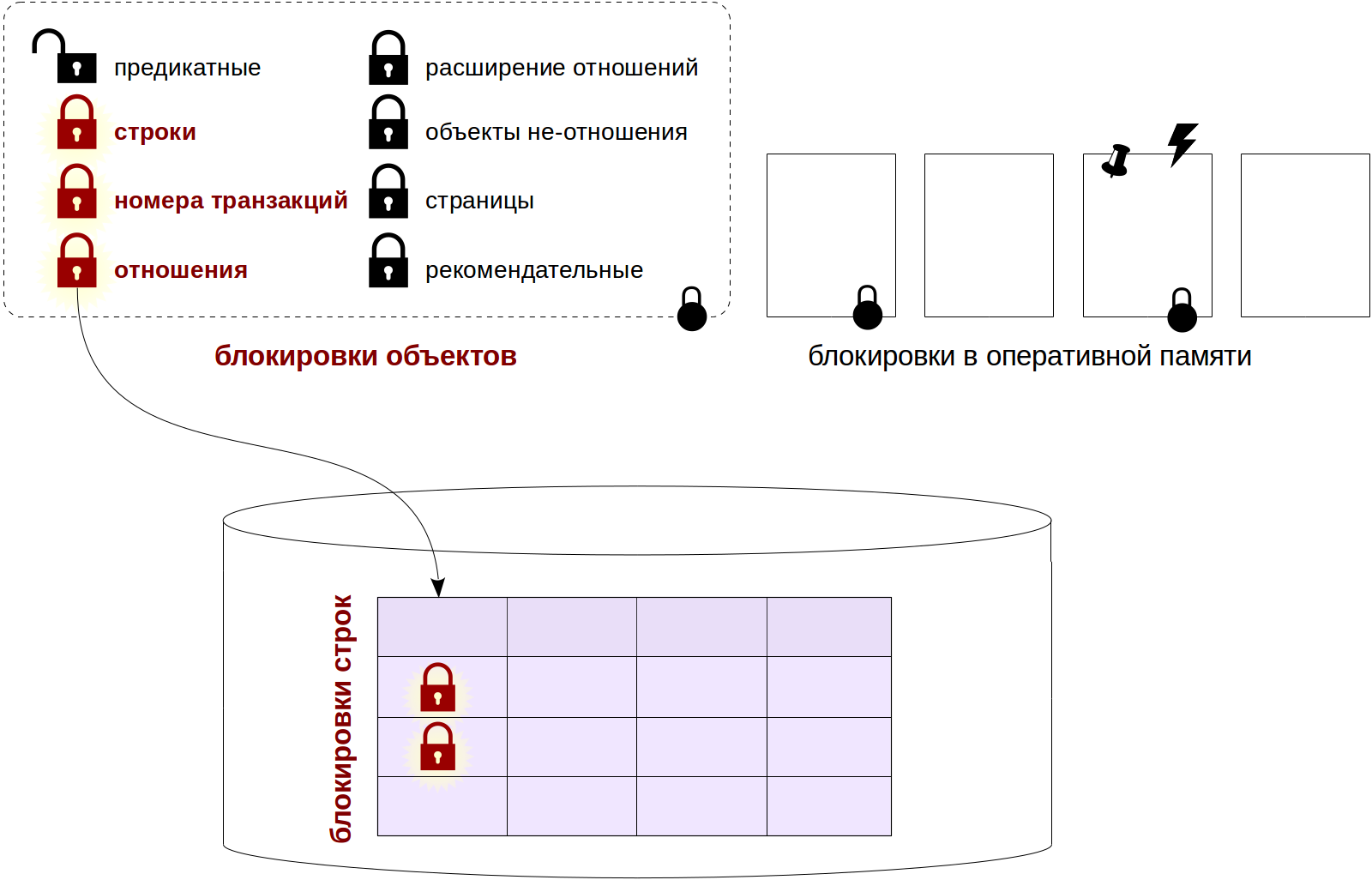
Напомню несколько важных выводов из прошлой статьи.
Нам безусловно хочется, чтобы изменение одной строки не приводило к блокировке других строк той же таблицы. Но и заводить на каждую строку по собственной блокировке мы не можем себе позволить.
Есть разные пути решения этой проблемы. В некоторых СУБД происходит повышение уровня блокировки: если блокировок уровня строк становится слишком много, они заменяются одной более общей блокировкой (например, уровня страницы или всей таблицы).
Как мы увидим позже, в PostgreSQL такой механизм тоже применяется, но только для предикатных блокировок. С блокировками строк дело обстоит иначе.
Блокировки строк
Устройство
Напомню несколько важных выводов из прошлой статьи.
- Блокировка должна существовать где-то в разделяемой памяти сервера.
- Чем выше гранулярность блокировок, тем меньше конкуренция (contention) среди одновременно работающих процессов.
- С другой стороны, чем выше гранулярность, тем больше места в памяти занимают блокировки.
Нам безусловно хочется, чтобы изменение одной строки не приводило к блокировке других строк той же таблицы. Но и заводить на каждую строку по собственной блокировке мы не можем себе позволить.
Есть разные пути решения этой проблемы. В некоторых СУБД происходит повышение уровня блокировки: если блокировок уровня строк становится слишком много, они заменяются одной более общей блокировкой (например, уровня страницы или всей таблицы).
Как мы увидим позже, в PostgreSQL такой механизм тоже применяется, но только для предикатных блокировок. С блокировками строк дело обстоит иначе.
Блокировки в PostgreSQL: 1. Блокировки отношений
14 мин
Два предыдущих цикла статей были посвящены изоляции и многоверсионности и журналированию.
В этом цикле мы поговорим о блокировках (locks). Я буду придерживаться этого термина, но в литературе может встретиться и другой: замóк.
Цикл будет состоять из четырех частей:
Материал всех статей основан на учебных курсах по администрированию, которые делаем мы с Павлом pluzanov, но не повторяет их дословно и предназначен для вдумчивого чтения и самостоятельного экспериментирования.
В этом цикле мы поговорим о блокировках (locks). Я буду придерживаться этого термина, но в литературе может встретиться и другой: замóк.
Цикл будет состоять из четырех частей:
- Блокировки отношений (эта статья);
- Блокировки строк;
- Блокировки других объектов и предикатные блокировки;
- Блокировки в оперативной памяти.
Материал всех статей основан на учебных курсах по администрированию, которые делаем мы с Павлом pluzanov, но не повторяет их дословно и предназначен для вдумчивого чтения и самостоятельного экспериментирования.
Читайте и другие серии.
Индексы:
- Механизм индексирования;
- Интерфейс метода доступа, классы и семейства операторов;
- Hash;
- B-tree;
- GiST;
- SP-GiST;
- GIN;
- RUM;
- BRIN;
- Bloom.
Изоляция и многоверсионность:
- Изоляция, как ее понимают стандарт и PostgreSQL;
- Слои, файлы, страницы — что творится на физическом уровне;
- Версии строк, виртуальные и вложенные транзакции;
- Снимки данных и видимость версий строк, горизонт событий;
- Внутристраничная очистка и HOT-обновления;
- Обычная очистка (vacuum);
- Автоматическая очистка (autovacuum);
- Переполнение счетчика транзакций и заморозка.
Журналирование:
- Буферный кеш;
- Журнал предзаписи — как устроен и как используется при восстановлении;
- Контрольная точка и фоновая запись — зачем нужны и как настраиваются;
- Настройка журнала — уровни и решаемые задачи, надежность и производительность.
Тяжёлое бремя времени. Доклад Яндекса о типичных ошибках в работе со временем
12 мин
В коде самых разных проектов нередко приходится оперировать временем — например, чтобы завязать логику работы приложения на текущее время у пользователя. Старший разработчик интерфейсов Виктор Хомяков victor-homyakov описал типичные ошибки, которые встречались ему в проектах на языках Java, C# и JavaScript от разных авторов. Перед ними вставали одни и те же задачи: получить текущую дату и время, измерить интервалы или выполнить код асинхронно.
— До Яндекса я работал в других продуктовых компаниях. Это не как фрилансер — написал, сдал и забыл. Приходится очень долго работать с одной кодовой базой. И я, собственно, смотрел, читал, писал много кода на разных языках и увидел много чего интересного. В итоге у меня родилась тема этого рассказа.
— До Яндекса я работал в других продуктовых компаниях. Это не как фрилансер — написал, сдал и забыл. Приходится очень долго работать с одной кодовой базой. И я, собственно, смотрел, читал, писал много кода на разных языках и увидел много чего интересного. В итоге у меня родилась тема этого рассказа.
Spring Boot 2: чего не пишут в release notes
35 мин

Когда у масштабного проекта происходит масштабное обновление, всё никогда не бывает просто: неизбежно возникают неочевидные нюансы (проще говоря, грабли). И тогда, как бы хороша ни была документация, с чем-то поможет только опыт — свой или чужой.
На конференции Joker 2018 я рассказал, с какими проблемами столкнулся сам при переходе к Spring Boot 2 и как они решаются. А теперь специально для Хабра — текстовая версия этого доклада. Для удобства в посте есть и видеозапись, и оглавление: можно не читать всё целиком, а перейти непосредственно к волнующей вас проблеме.
Мелкая питонячая радость #7: три штуки по цене одной — консольная анимация, алгоритмы и отладка
2 мин
На этой неделе достаточно крупных мелких радостей не нашлось, зато нашлись 3 совсем мелкие мелкие радости.
termtosvg
Сейчас принято снабжать свои библиотеки и репо на github красивой анимацией, показывающей консоль с живой демкой вашего творения.

Традиция, бесспорно, хорошая и правильная. Только записывать такие анимации бывает трудно/лень/некогда. Авторы termtosvg пристрелили всех зайцев одим выстрелом и дали программистам прекрасную штуку для записи консольных демок.
Лямбда-выражения в Java 8
19 мин
В новой версии Java 8 наконец-то появились долгожданные лямбда-выражения. Возможно, это самая важная новая возможность последней версии; они позволяют писать быстрее и делают код более ясным, а также открывают дверь в мир функционального программирования. В этой статье я расскажу, как это работает.
Java задумывалась как объектно-ориентированный язык в 90-е годы, когда объектно-ориентированное программирование было главной парадигмой в разработке приложений. Задолго до этого было объектно-ориентированное программирование, были функциональные языки программирования, такие, как Lisp и Scheme, но их преимущества не были оценены за пределами академической среды. В последнее время функциональное программирование сильно выросло в значимости, потому что оно хорошо подходит для параллельного программирования и программирования, основанного на событиях («reactive»). Это не значит, что объектная ориентированность – плохо. Наоборот, вместо этого, выигрышная стратегия – смешивать объектно-ориентированное программирование и функциональное. Это имеет смысл, даже если вам не нужна параллельность. Например, библиотеки коллекций могут получить мощное API, если язык имеет удобный синтаксис для функциональных выражений.
Главным улучшением в Java 8 является добавление поддержки функциональных программных конструкций к его объектно-ориентированной основе.
Java задумывалась как объектно-ориентированный язык в 90-е годы, когда объектно-ориентированное программирование было главной парадигмой в разработке приложений. Задолго до этого было объектно-ориентированное программирование, были функциональные языки программирования, такие, как Lisp и Scheme, но их преимущества не были оценены за пределами академической среды. В последнее время функциональное программирование сильно выросло в значимости, потому что оно хорошо подходит для параллельного программирования и программирования, основанного на событиях («reactive»). Это не значит, что объектная ориентированность – плохо. Наоборот, вместо этого, выигрышная стратегия – смешивать объектно-ориентированное программирование и функциональное. Это имеет смысл, даже если вам не нужна параллельность. Например, библиотеки коллекций могут получить мощное API, если язык имеет удобный синтаксис для функциональных выражений.
Главным улучшением в Java 8 является добавление поддержки функциональных программных конструкций к его объектно-ориентированной основе.
Децентрализованное хранилище данных Ethereum Swarm
9 мин

Блокчейн Ethereum интересен своими смарт-контрактами, а также возможностью создания децентрализованных приложений DApp (Decentralized Application). Однако такому приложению необходимо децентрализованное хранилище данных.
Хранение данных большого объема в блокчейне может стоить немалых денег. На помощь приходят такие децентрализованные хранилища, как Ethereum Swarm («swarm» переводится как «рой», «куча»). Если кратко, то Ethereum Swarm представляет собой программный код, работающий на пиринговой сети Ethereum. Он обеспечивает децентрализованное хранение данных на дисках узлов, владельцы которых отдают свои ресурсы в общее пользование.
В этой статье мы расскажем о том, как установить локальный узел Ethereum Swarm для приватной сети Ethereum с целью тестирования технологии и разработки децентрализованных приложений, хранящих данные в Ethereum Swarm.