Я с детства испытывал тягу к знаниям. Смотрел шоу "Своя игра" и поражался тому, откуда можно знать о мире настолько широко. Невозможно было игнорировать тот факт, что гроссмейстеры были в основном, пожилыми, а я хотел все знать сейчас, а не когда я выйду на пенсию. Поэтому я много читал и не переставал мечтать о том, чтобы можно было загрузить информацию в голову напрямую.
Последние несколько лет, компания Neuralink, с Илоном Маском в роли сооснователя, активно работает над созданием такого чипа. Этот факт, однако, повлек дискуссии, что именно произойдет, если информация попадет на чип, к которому у вас есть доступ, однако нейронные связи в вашем мозгу не сформировались и вы эту информацию не обдумывали? Чем эта ситуация отличается от того, когда информация находится в книге, на жестком диске, в телефоне или на компьютере, но вы книгу еще не читали? Разве что простотой доступа?
Эта дискуссия заставила меня задуматься над тем, есть ли иной способ ускорить освоение информации, не подвергаясь рискам от установки чипа, которого, в любом случае, не существует и не появится в обозримом будущем? Так я начал изучать технологии обучения.
Методов обучения множество. Часть из них ориентированы больше на усиление запоминания информации, а другая часть на углубление понимания. Однако, меня интересовало то, что увеличило бы именно скорость. Само собой напрашивается скорочтение. Тут хотелось бы остановиться и обсудить этот метод. Есть многочисленные исследования различных вариаций скорочтения и все они показывают, что скорочтение это миф и те, кто его практикуют, просто водят глазами по странице. Более того, если мы говорим не о художественных произведениях или текстах полных воды, а о "нормальных книгах", то очевидно, что прочитать страницу занимает 1 минуту, а обдумать - 10. Если даже за счет техник скорочтения можно было бы научиться прочитывать страницу за секунду, все еще остается потратить 10 минут на обдумывание.


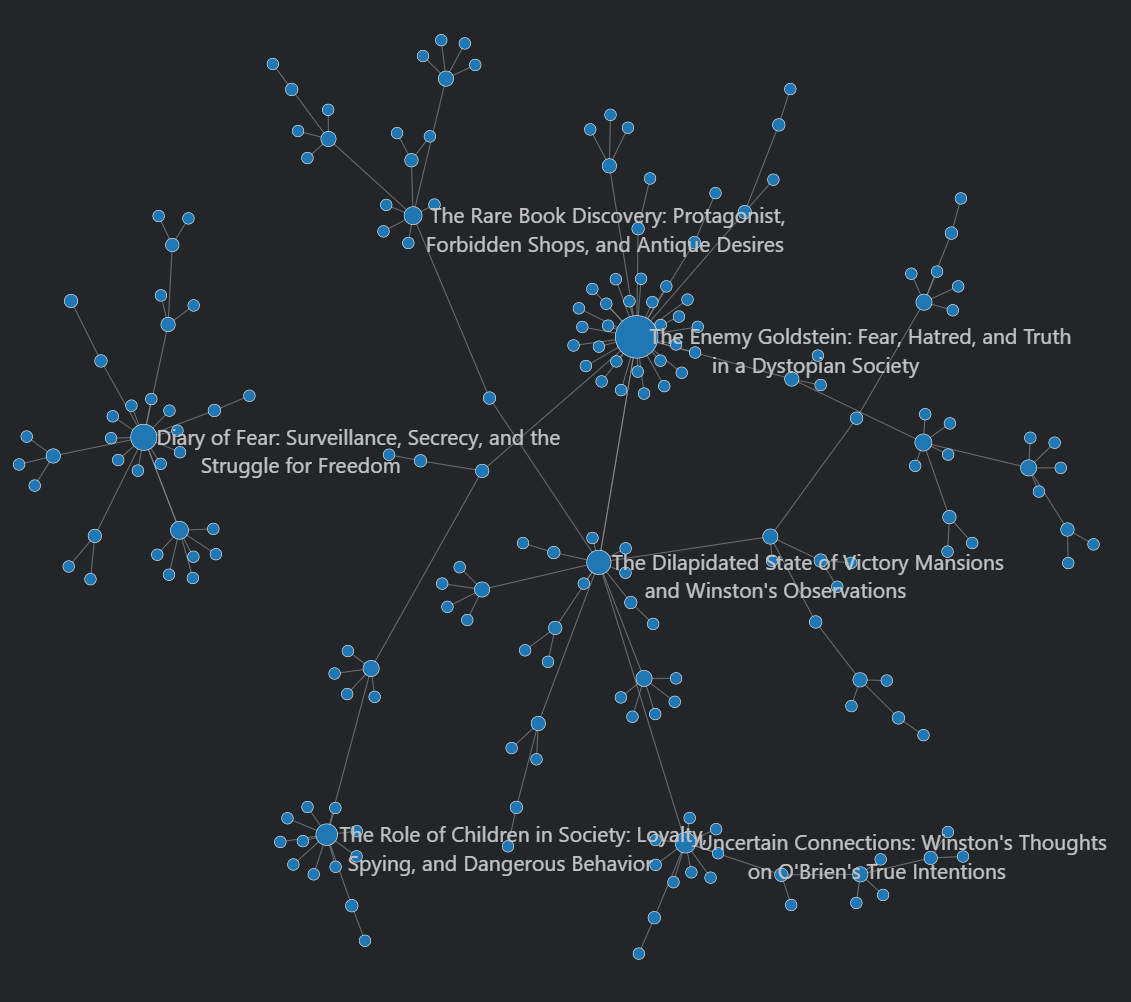
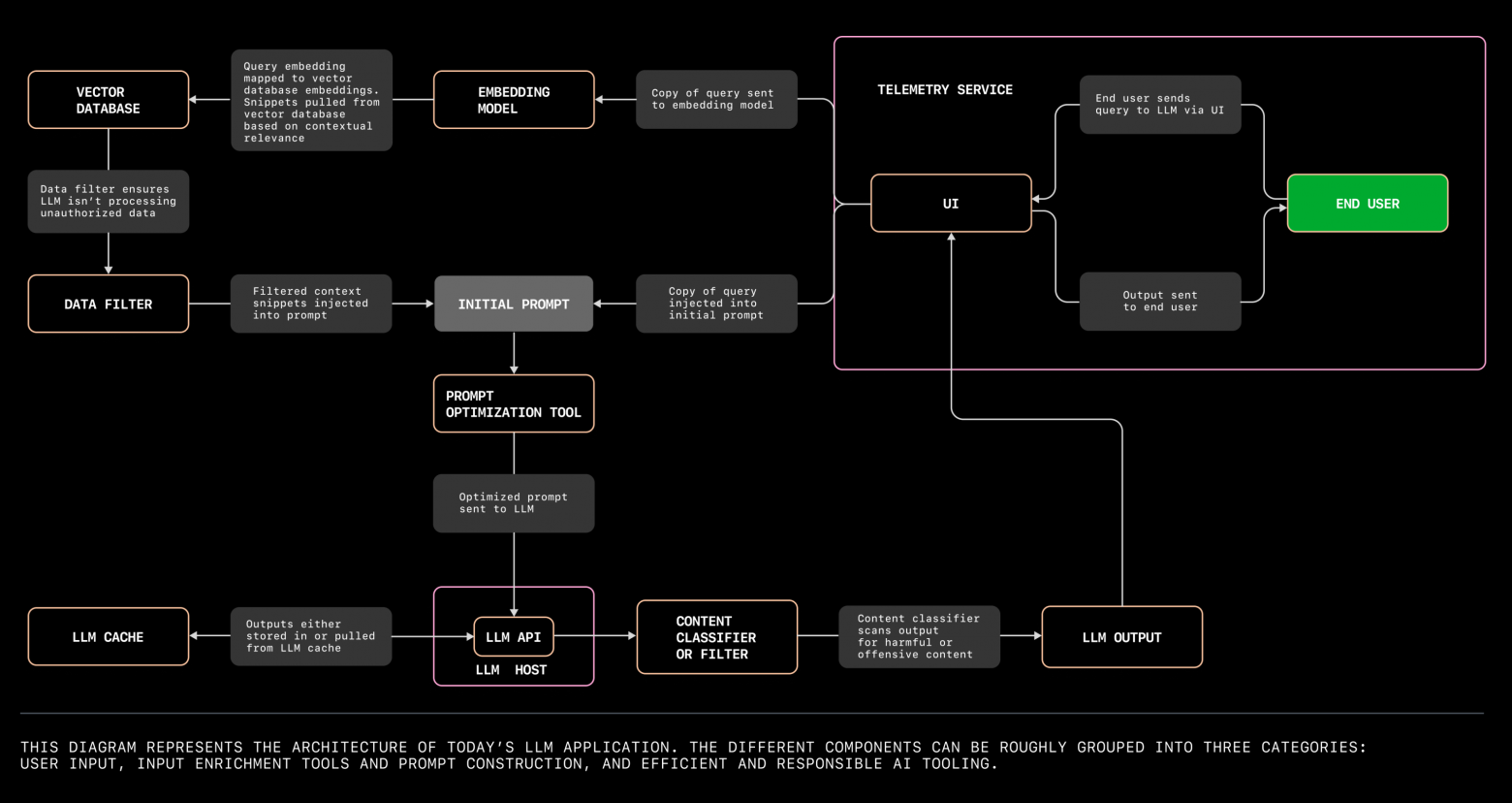









 В рамках Mobile Camp Яндекса наш коллега
В рамках Mobile Camp Яндекса наш коллега