
Apache Cassandra - это распределенная NoSQL база данных. В этой статье будут описаны основные механизмы передачи, репликации и поддержания согласованности данных внутри сети.
Apache Cassandra - это распределенная NoSQL база данных. В этой статье будут описаны основные механизмы передачи, репликации и поддержания согласованности данных внутри сети.

Привет! Меня зовут Андрей Михеев, я занимаюсь развитием бэкенда War Robots (это мобильный PvP-шутер, в котором с помощью больших роботов можно выяснить, кто круче). Игре уже почти 9 лет, и за это время мы повидали всякого.
Круто, когда у вас в команде есть большой опыт в разработке конкретной задачи, архитектура выверена, библиотеки и фреймворки отлажены. Но что делать, если опыта не хватает, готовых решений нет, проект — потенциальный highload, а запуститься желательно было бы уже вчера? Мы как раз оказались в такой ситуации. Об этом и поговорим — а заодно о выводах, которые тут можно сделать.







В Одноклассниках запросы пользователей обслуживает более 200 видов уникальных типов сервисов. Многие из них совмещают в одном JVM-процессе бизнес-логику и распределенную отказоустойчивую базу данных Cassandra, превращая обычный микросервис в микросервис с состоянием. Это позволяет нам строить высоконагруженные сервисы, управляющие сотнями миллиардов записей с миллионами операций в секунду на них.
Какие преимущества появляются при совмещении бизнес-логики и БД? Какие нюансы надо учесть, прибегая к такому подходу? Что с надёжностью и доступностью сервисов? Расскажем подробно об этом всём.

Всем привет. Мы разрабатываем продукт для анализа оффлайн-трафика. В проекте есть задача, связанная со статистическим анализом путей движения посетителей по областям.
В рамках этой задачи пользователи могут задавать системе запросы следующего вида:
и еще ряд подобных аналитических запросов.
Движение посетителя по областям представляет собой направленный граф. Почитав интернеты, я обнаружил, что графовые СУБД используются и для аналитических отчетов. У меня появилось желание посмотреть как будут справляться с подобными запросами графовые СУБД (TL;DR; плохо).


Предлагаю ознакомиться с расшифровкой доклада 2017 года Игорь Стрыхарь «ClickHouse – визуально быстрый и наглядный анализ данных в Tabix».
Веб-интерфейс для ClickHouse в проекте Tabix.
Основные возможности:




Привет! Меня зовут Сергей Тетерюков, и я работаю инженером инфраструктуры и автоматизации в X5 Tech. Недавно я написал для коллег обзорную статью о БД Apache Cassandra DB и её деплое, и теперь хочу поделиться ей с вами.
Центр Развития Перспективных Технологий - компания разработчик системы мониторинга товаров. Как IT компания с большим количеством данных мы используем множество NoSQL решений в своей повседневной работе. Одним из таких решений является Apache Cassandra.
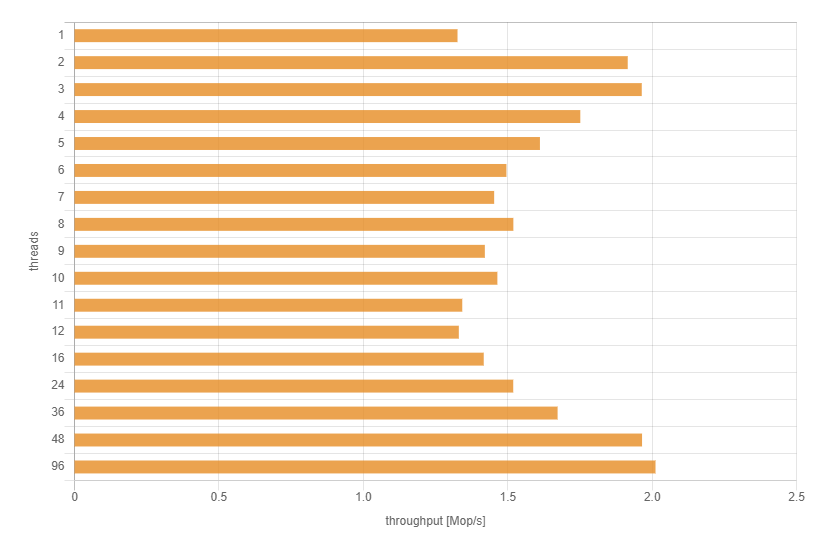
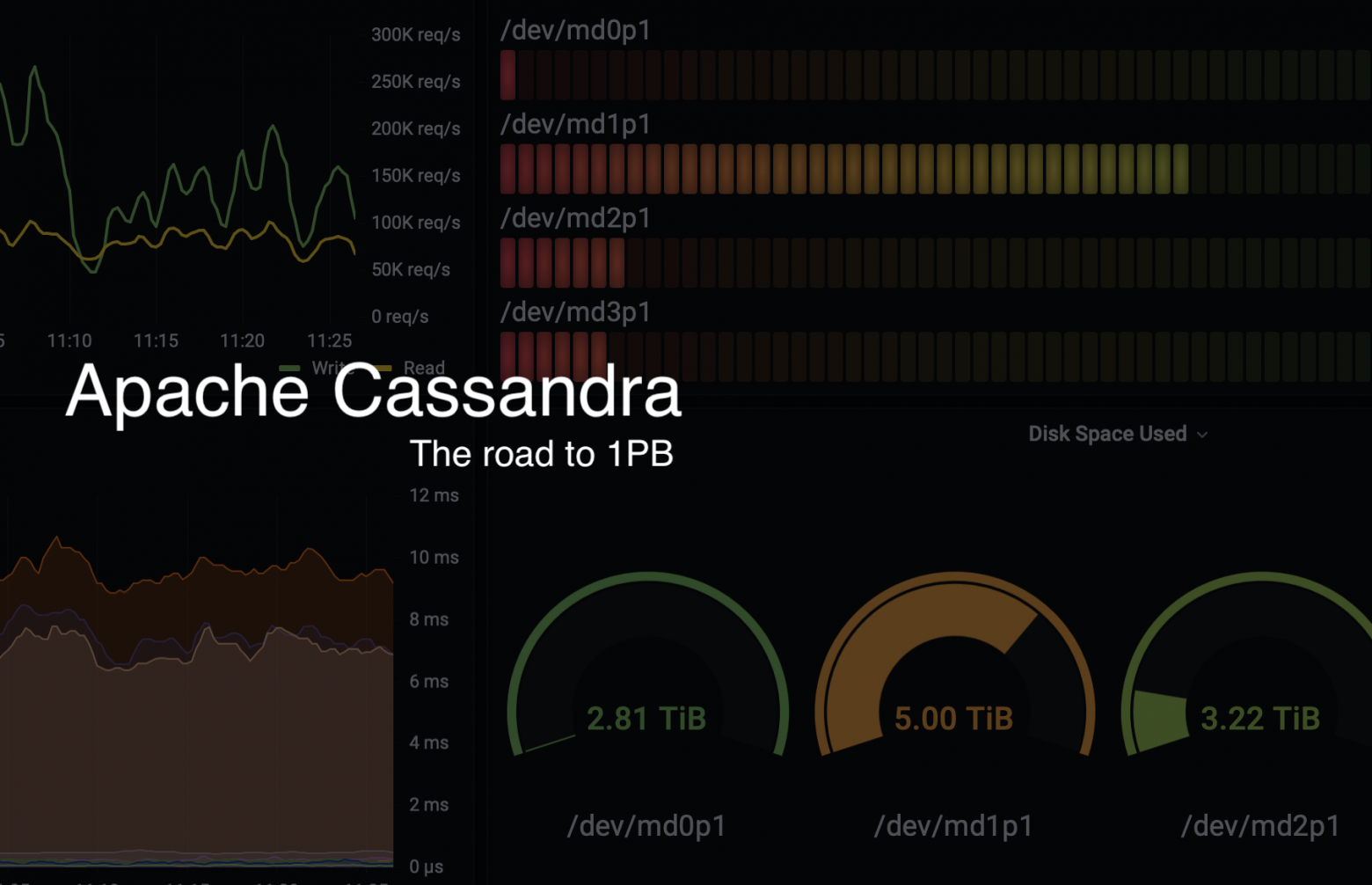
Суммарно, во всех кластерах Cassandra мы храним 0.4PB данных при общей емкости 0.9PB, стабильно производим 0.7млн операций записи и доступа к данным и 1.1млн когда необходимо разогнаться в трудные времена, при этом продолжаем непрерывно расширяться.
Отсюда лежит и название статьи, к моменту публикации последней главы из цикла петабайтный барьер емкости будет взят.
Материал подразумевает, что вы уже начали знакомиться с этой замечательной базой данных, хотите найти примеры её использования в российском сегменте интернета и будет полезен тем, кто постоянно ищет способ обучиться за счёт чужих ошибок. Ошибок мы совершили не мало, добро пожаловать!

Сердцем любого backend являются данные. Существует два сценария использования данных. В одном из них данные изменяются редко, но при этом активно используются в сыром или агрегированном виде и применяются для целей аналитики в реальном времени (такие системы принято называть OLAP). В других системах важно обеспечить сохранение с высокой скоростью большого количество неструктурированных или полуструктурированных объектов, поступающих от устройств Интернета вещей, из источников произвольных событий, наблюдений за активностью пользователя (такие системы называются OLTP - Online Transaction Processing, ориентированные на большое количество транзакций с минимальной задержкой обработки). Для таких систем важно обеспечить надежность хранения данных, поддержку распределенного хранения на нескольких серверах и/или дата-центрах и сохранение консистентности распределенного хранилища.
При этом сами объекты могут отличаться от привычной реляционной модели данных и представляться, например, в виде json-документов с произвольной схемой, объектов с полями со множественными значениями или графов. Разумеется это приводит к необходимости изучения новых подходов к поиску и добавлению данных, использованию специальных драйверов. Но что если соединить распределенное надежное хранилище и синтаксис запросов, близкий к SQL? В этой статье мы познакомимся с проектом Apache Cassandra и обсудим на примере разработки API на Kotlin для сбора телеметрии с датчиков, расположенных по всему миру (с поддержкой отказоустойчивости и управляемой репликации между дата-центрами).

Критериям выбора архивного хранилища она соответствовала идеально. Оптимизированная под запись, легко масштабируемая, совместимая с привычной уже Cassandra, только в разы быстрее… Имя же её — Сцилла (греч. Σκύλλα — «лающая») — напоминая о мифологическом чудовище, рисовало в воображении картины молниеносного поглощения гигантских объемов данных. Сложно было устоять и не попробовать.