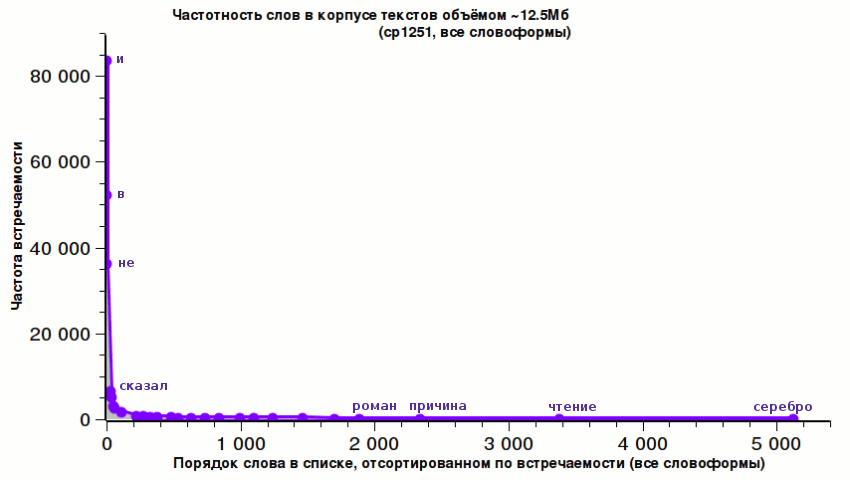
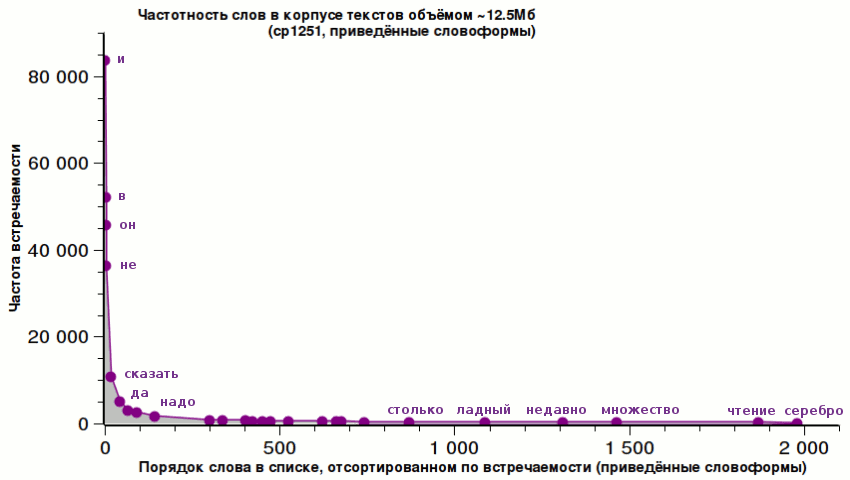
Как говорил великий классик Аристотель, «известное, оказывается, известно немногим».
Языковеды всего мира подвержены одной пагубной иллюзии, полагая, что если они сумеют построить «правильный синтаксический граф», (то есть, «дерево фразы»), то они в этом случае, наконец-таки, решат это треклятую проблему машинной обработки естественно-язычных текстов (еят). Вот и ищут лингвисты денно и нощно какие-то мифические связи и отношения между словами (семантическими единицами) в предложениях и абзацах текстов. Да ещё и кибернетиков подключили к этим своим безуспешным поискам. Прошло уже полвека таких изысканий, а воз, как говорится, и поныне там. Не строится никак этот граф, давая много лет устойчивые 50% ошибок. Уже и сотни миллионов долларов потрачены. Один только проект «Watson» чего стоит. А ведь, в принципе, этих «связей и отношений» и нет на самом-то деле. Всё это, если внимательно вдуматься, искусственные наукообразные выдумки, из-за которых, собственно, прогресс в деле создания технологии осмысленной обработки еят зашел в тот тупик, где сейчас и пребывает.
Лингвисты как те инопланетяне, в руки которых попало обыкновенное для землян куриное яйцо. Вот они его могут изучать и так и сяк. И обмерить вдоль и поперек, и взвесить, и рентгеном просветить, и скорлупу исследовать на состав, и её твердость по Моосу замерить, и хрупкость уточнить, и цвет откалориметрировать. В общем провести всё, что только можно измерить, а вот понять, как оно образуется, того бедняги никак не смогут, поскольку самой курицы не знают и не ведали. Точно также не могли туземцы океанических островов нашей планеты понять, каким это образом транзисторный приемник, занесенный к ним западной цивилизацией, может издавать членораздельные звуки или звуковые мелодии. И как-бы они не изучали этот приемник, не пробовали его на зуб или на вкус, того бы вовек сами не поняли, что к такому устройству еще и радиостанция нужна. Подобная картина наблюдается и с языковедами, изучающими еят, как продукт (яйцо, транзистор) человеческого мышления (курицы, радиостанции), не обращая, при этом, внимания на самого «генератора (производителя) яйца».