Автор исходного изображения: Blue Flourishes/Shutterstock.com
Всем привет! В этом посте мы расскажем про синтез голосов Сбера, Афины и Джой — виртуальных ассистентов семейства Салют. О том, как мы в SberDevices обучали модели, чтобы сделать синтез живым и специфичным для каждого персонажа, а также с какими проблемами столкнулись и как их решали.
Согласно нашей «библии ассистентов», Сбер — энергичный гик, Афина — взрослая и деловая, а Джой — дружелюбная и веселая. Они отличаются не только уникальными характерами, обращением на «ты»/«вы» и предпочтениями в шутках. Мы попытались сделать так, чтобы их личности отражались и в голосах, которыми они разговаривают.
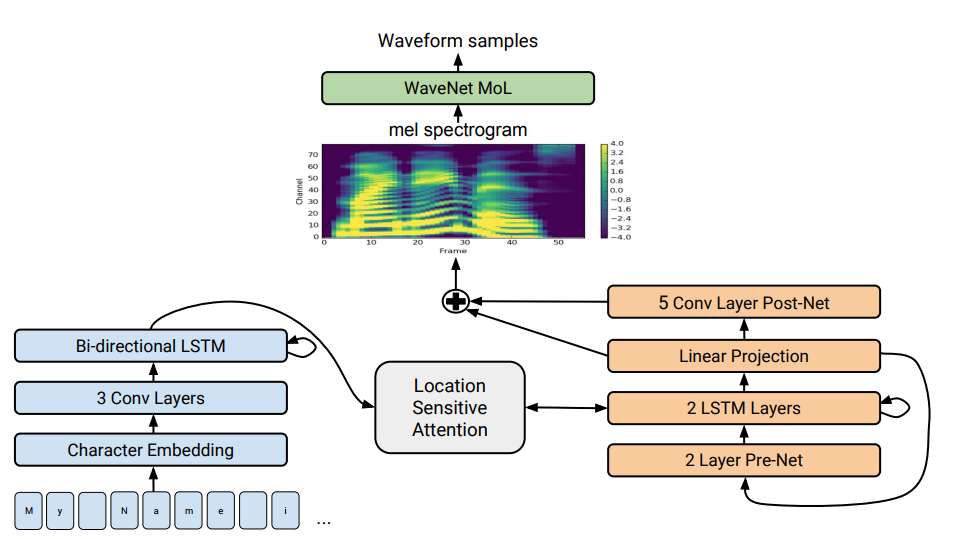
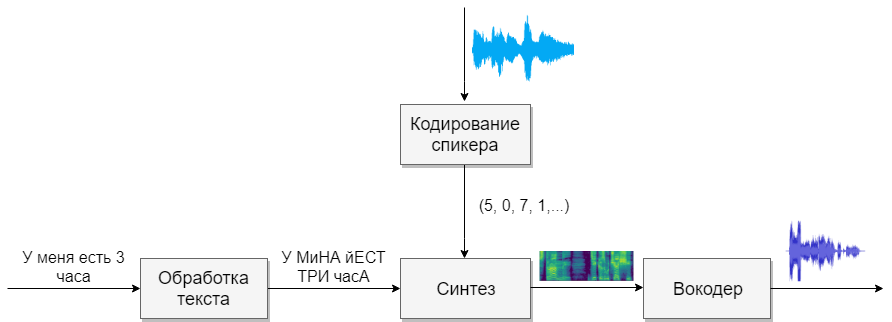
Персонажей озвучили телеведущая Анастасия Чернобровина (Афина) и актёры дубляжа Даниил Щебланов и Татьяна Ермилова (Сбер и Джой). Виртуальных ассистентов можно услышать в приложениях Сбер Салют, СберБанк Онлайн, нашем колл-центре по номеру 900, а также в устройствах SberBox и SberPortal. Всё, что вы услышите, — это синтез речи, реализованный с помощью нейросетей. Он работает на связке Tacotron 2 и LPCNet.
Но, чтобы было понятно, что, зачем и почему, — немного теории и истории